一个典型的计算机系统如下图所示:
直接让应用使用硬件可能会导致滥用,并且应用需要处理复杂的硬件细节,容易出错。所以我们引入了操作系统来管理硬件资源,如下图所示:
操作系统为了让应用能更好更简单地使用硬件资源,对硬件资源做了进一步抽象,如下图所示: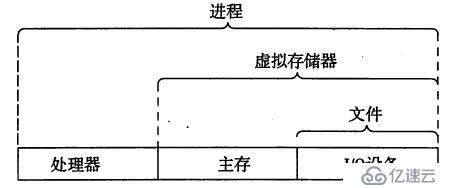
虚拟存储器把进程访问的存储设备抽象成一个巨大的字节数组,并对每个字节做唯一的地址编码。它提供了三个重要的功能:
虚拟存储器在幕后自动地工作,无需应用程序员干涉,既然如此,为什么我们还需要去理解它呢?我想理解它可以带来以下几点好处:
进程看到是虚拟地址,但是信息是存在物理内存上的,那么系统是如何用虚拟地址来获取对应物理内存的字节信息的呢?简单来说,可以分为三步:
具体过程如下图: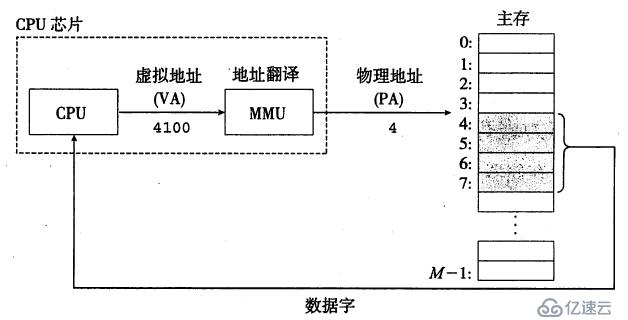
MMU是如何把虚拟地址翻译为物理地址的呢?
OS会把物理内存、虚拟内存分为同样大小的块(linux默认为4k),并称之为页。同时为每个进程分配页表,页表是一个页表条目(PTE)数组,其中每个PTE记录了虚拟页与物理页的映射关系。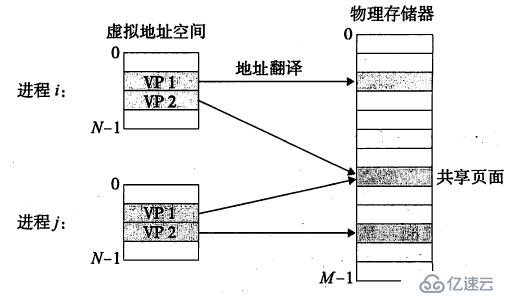
一个虚拟地址可以分为两部分:虚拟页号×××和虚拟页偏移量VPO。由于虚拟页与物理页是同样大小,因此虚拟页偏移量就是物理页偏移量;虚拟页号是页表中PTE的索引,对应的PTE中存储着物理页号和有效位(表示页面是否有对应物理页),这样MMU通过查询PTE就可以找到虚拟页对应的物理页,再加上虚拟页偏移量就可以得到物理地址,如下图:
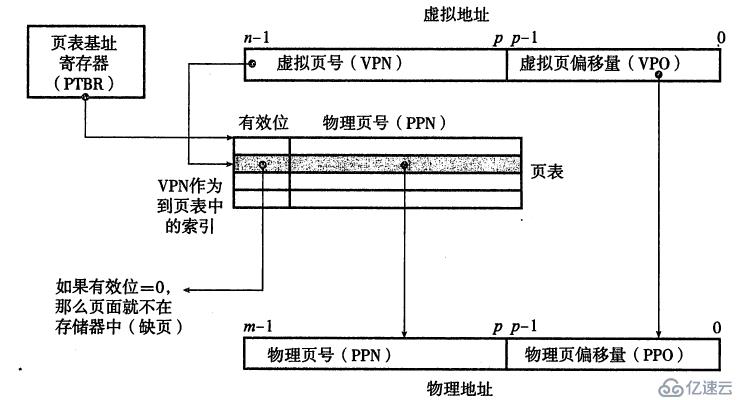
如果每个进程只有一个页表(假设物理页大小为4k),那么对于32位系统,需要占用4M内存(每个PTE是4字节);对于64位系统(实际只用了48位用来寻址),则需要256G内存,实在是太大了。为了解决这个问题,我们用多级页表,如下图: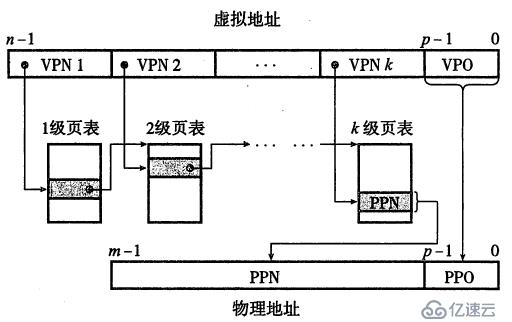
在多级页表中,所有级别的页表大小是一样的,我们以linux的4级页表为例,则最少要4个页表,假设一个页表4k,总共16k;随着进程消耗内存的增长,第k级页表数目随之线性增长,由于其他级别的页表数目远远小于k级页表,因此总页表消耗内存页页接近于线性增长。由于进程实际占用内存大小远小于256T,因此页表消耗内存远小于一级页表。
从上述小结,我们知道每个进程都有一个独立的虚拟存储器空间,那么其布局是否有规律呢?我们以linux下的64位进程举例,见下图: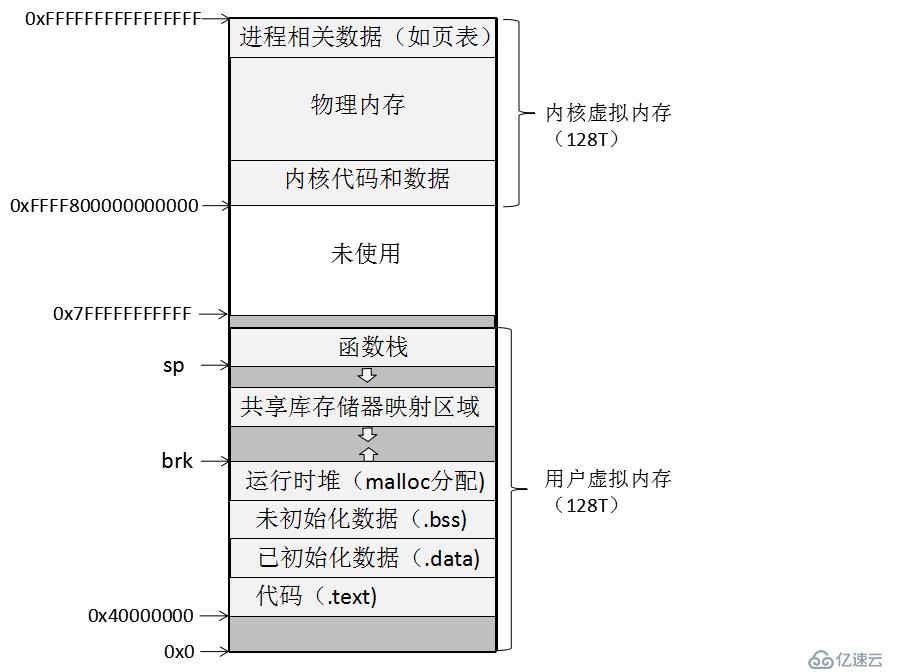
linux将用户虚拟存储器组织成一些段的集合。一个段就是已分配的虚拟存储器的连续片。只有存在于段的虚拟存储器页是可以被进程访问的。
#include <stdlib.h>
int main()
{
char *p = (char*)malloc(1);
while(1);
return 0;
}编译上述代码并运行,通过top获取此进程PID后,我们可以打开/proc/PID/maps文件查看进程的内存布局:
00400000-00401000 r-xp 00000000 fd:01 723899 /home/wld/test/a.out
00600000-00601000 r--p 00000000 fd:01 723899 /home/wld/test/a.out
00601000-00602000 rw-p 00001000 fd:01 723899 /home/wld/test/a.out
0148c000-014ad000 rw-p 00000000 00:00 0 [heap]
7fb917267000-7fb917425000 r-xp 00000000 fd:01 1731435 /lib/x86_64-linux-gnu/libc-2.19.so
7fb917425000-7fb917625000 ---p 001be000 fd:01 1731435 /lib/x86_64-linux-gnu/libc-2.19.so
7fb917625000-7fb917629000 r--p 001be000 fd:01 1731435 /lib/x86_64-linux-gnu/libc-2.19.so
7fb917629000-7fb91762b000 rw-p 001c2000 fd:01 1731435 /lib/x86_64-linux-gnu/libc-2.19.so
7fb91762b000-7fb917630000 rw-p 00000000 00:00 0
7fb917630000-7fb917653000 r-xp 00000000 fd:01 1731443 /lib/x86_64-linux-gnu/ld-2.19.so
7fb917835000-7fb917838000 rw-p 00000000 00:00 0
7fb917850000-7fb917852000 rw-p 00000000 00:00 0
7fb917852000-7fb917853000 r--p 00022000 fd:01 1731443 /lib/x86_64-linux-gnu/ld-2.19.so
7fb917853000-7fb917854000 rw-p 00023000 fd:01 1731443 /lib/x86_64-linux-gnu/ld-2.19.so
7fb917854000-7fb917855000 rw-p 00000000 00:00 0
7ffe8b3e1000-7ffe8b402000 rw-p 00000000 00:00 0 [stack]
7ffe8b449000-7ffe8b44b000 r--p 00000000 00:00 0 [vvar]
7ffe8b44b000-7ffe8b44d000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]上面每一行表示一个段,每个段的有6列,各列含义如下:
假如MMU在尝试翻译某个虚拟地址A时,没有对应的物理地址,则会触发了一个缺页异常。这个异常会导致控制转移到内核的缺页异常处理程序,处理程序随后执行如下步骤:
通过执行以下两种的任意一种命令可查看某个进程的缺页中断信息
ps -o majflt,minflt -C program_name
ps -o majflt,minflt -p pid
majflt和minor这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
其中majflt与minflt的不同是,majflt表示需要读写磁盘,可能是内存对应页面在磁盘中需要load到物理内存中,也可能是此时物理内存不足,需要淘汰部分物理页面至磁盘中。
linux通过将虚拟内地段与一个磁盘上的文件关联起来,以初始化这个虚拟存储器段的内容,这个过程称之为内存映射(memory mapping)。内存映射有两种:
###6.1 共享对象
内存映射可以让我们简单高效地把程序和数据加载到虚拟存储器空间中。在实际中,许多进程会映射同一个文件到内存中,比如glic动态库,如果物理内存中存在多份,那就是极端的浪费。我们可以通过共享对象技术来消除浪费。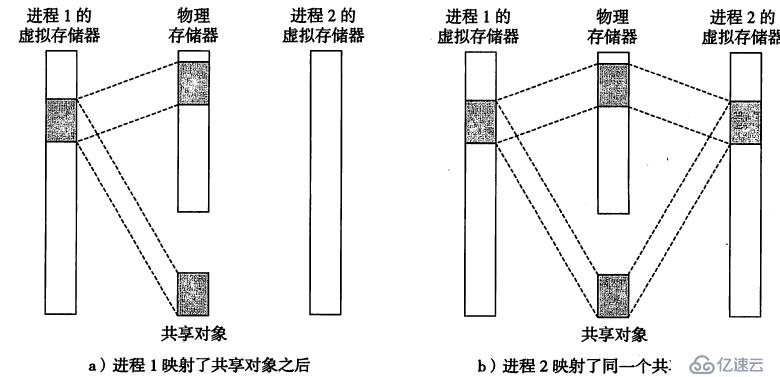
对于私有对象,我们可以用写时拷贝技术来共享物理内存页。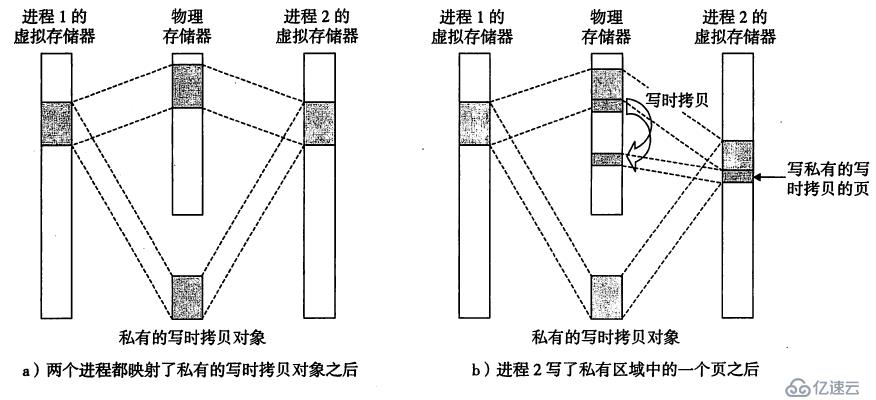
类unix操作系统下的动态内存分配器有很多,比如ptmalloc(linux默认),tcmalloc(google出品),jemalloc(FreeBSD、NetBSD和firefox默认)。这三种分配器的详细介绍可以参考http://www.360doc.com/content/13/0915/09/8363527_314549128.shtml。
本文以ptmalloc为例介绍动态内存分配。在linux下os提供两种动态内存分配brk和mmap。ptmalloc对于申请内存小于128k的采用brk方式,大于128k的采用mmap方式。
对于大内存,malloc会直接调用系统函数mmap分配内存,以物理页为最小单位做对齐。free会直接调用系统函数munmap释放内存。
进程有一个指针指向堆的顶部的地址,通过系统函数brk可以改变这个指针的位置,从而改变堆的大小(堆可以扩大也可以收缩)。当已有的堆不能分配内存时,brk会扩大堆来分配动态内存。当顶部的内存被释放,切释放内存大于128k,brk就会收缩堆,如下图: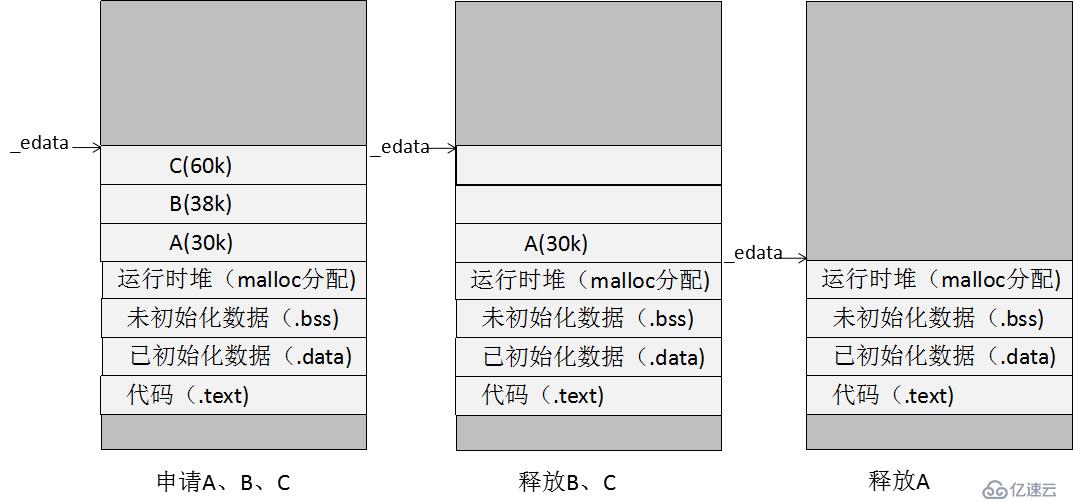
从上面的堆分配释放方式,我们知道实际上很多小内存申请后是不会马上释放给OS,为了将这些内存重复利用,内存分配器需要由一个算法,下面介绍下ptmalloc是如何处理的。
ptmalloc通过chunk的数据结构来组织每个内存单元。当我们使用malloc分配得到一块内存的时候,这块内存就会通过chunk的形式被记录到glibc上并且管理起来。你可以把它想象成自己写内存池的时候的一个内存数据结构。chunk的结构可以分为使用中的chunk和空闲的chunk。使用中的chunk和空闲的chunk数据结构基本项同,但是会有一些设计上的小技巧,巧妙的节省了内存。
使用中的chunk: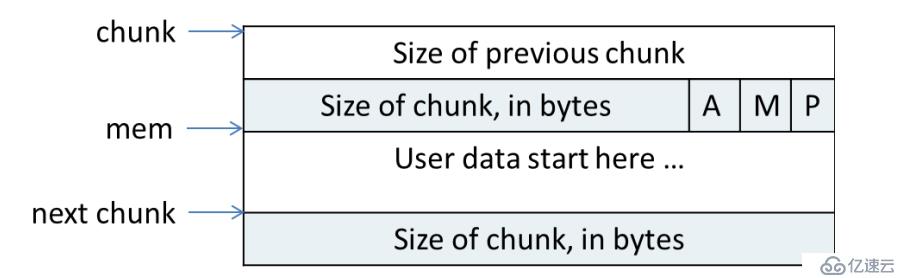
空闲的chunk结构会复用User data来保存双向链表指针。
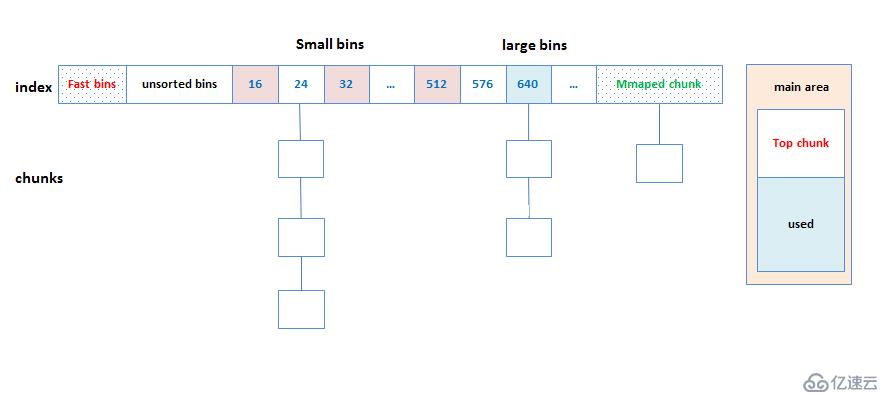
ptmalloc一共维护了128bin。每个bins都维护了大小相近的双向链表的chunk。
通过上图这个bins的列表就能看出,当用户调用malloc的时候,能很快找到用户需要分配的内存大小是否在维护的bin上,如果在某一个bin上,就可以通过双向链表去查找合适的chunk内存块给用户使用。
造成堆利用率低的主要原因是碎片,当虽然有未使用的内存但不能用来满足分配请求时,就会发生这种现象。有两种形式的碎片:
####提问1:请问下面代码运行后,OS会立即分配1G物理内存吗?
#include <cstdlib>
int main()
{
char *p = (char*)malloc(1024*1024*1024);
while(1);
return 0;
}###提问2:请问下面代码运行后,OS会分配多少物理内存?
#include <cstdlib>
#include <cstring>
int main()
{
const size_t MAX_LEN = 1024*1024*1024;
char *p = (char*)malloc(MAX_LEN);
memset(p, 0, MAX_LEN/2);
while(1);
return 0;
}免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





