小编给大家分享一下XML文件解析SAX/DOM/PULL的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
Sax特点( SAX是Simple API for XML的简称)
1. 解析效率高,占用内存少
2.可以随时停止解析
3.不能载入整个文档到内存
4.不能写入xml
5.SAX解析xml文件采用的是事件驱动
pull与sax的不同之处
1.pull读取xml文件后触发相应的事件调用方法返回的是数字。
2.pull可以在程序中控制,想解析到哪里就可以停止到哪里
3.Android中更推荐使用pull解析
DOM的特点
优点
1.整个文档树在内存中,便于操作;支持删除、修改、重新排列等多种功能
2.通过树形结构存取xml文档
3.可以在树的某个节点上向前或向后移动
缺点
1.将整个文档调入内存(包括无用的节点),浪费时间和空间
适用场合
一旦解析了文档还需多次访问这些数据;硬件资源充足(内存,cpu)
首先定义我定义了一个Student.xml文件
**示例**
[code]<?xml version="1.0" encoding="utf-8"?> <students> <student id="1" > <name> 小红 </name> <age> 21 </age> <sex> 女 </sex> <adress> 上海 </adress> </student> <student id="2" > <name> 小黑 </name> <age> 22 </age> <sex> 男 </sex> <adress> 天津 </adress> </student> <student id="3" > <name> 小网 </name> <age> 23 </age> <sex> 男 </sex> <adress> 北京 </adress> </student> </students>
**1.sax解析**
[code]package com.example.sax_xml;
import java.io.IOException;
import java.io.InputStream;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.InputSource;
import org.xml.sax.XMLReader;
import android.app.Activity;
import android.content.res.AssetManager;
import android.os.Bundle;
import android.view.View;
public class MainActivity extends Activity {
@Override
protected void onCreate(Bundle savedInstanceState) {
// TODO Auto-generated method stub
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
}
public void sax_xml(View v) {
// 得到设备管理者对象
AssetManager manager = this.getAssets();
try {
// 获取到assets目录下的Student.xml文件输入流
InputStream is = manager.open("Student.xml");
/**
* SAXParserFactory 定义了一个API工厂,使得应用程序可以配置和获得一个基于SAX(Simple API for
* XML
*
* )的解析器,从而能够解析XML文档( 原文: Defines a factory API that enables
* applications to configure and obtain a SAX based parser to parse
* XML documents. )
*
* 它的构造器是受保护的,因而只能用newInstance()方法获得实例( Protected constructor to
* force use of newInstance(). )
*/
SAXParserFactory factory = SAXParserFactory.newInstance();
/**
* XmlReader 类是一个提供对 XML 数据的非缓存、只进只读访问的抽象基类。 该类符合 W3C 可扩展标记语言 (XML)
* 1.0 和 XML 中的命名空间的建议。 XmlReader 类支持从流或文件读取 XML 数据。
* 该类定义的方法和属性使您可以浏览数据并读取节点的内容。 当前节点指读取器所处的节点。
* 使用任何返回当前节点值的读取方法和属性推进读取器。 XmlReader 类使您可以: 1. 检查字符是不是合法的
* XML字符,元素和属性的名称是不是有效的 XML 名称。 2. 检查 XML 文档的格式是否正确。 3. 根据 DTD
* 或架构验证数据。 4.从 XML流检索数据或使用提取模型跳过不需要的记录。
*/
XMLReader xmlReader = factory.newSAXParser().getXMLReader();
/**
* ContentHandler是Java类包中一个特殊的SAX接口,位于org.xml.sax包中。该接口封装了一些对事件处理的方法
* ,当XML解析器开始解析XML输入文档时,它会遇到某些特殊的事件,比如文档的开头和结束、元素开头和结束、以及元素中的字符数据等事件
* 。当遇到这些事件时,XML解析器会调用ContentHandler接口中相应的方法来响应该事件。
*/
//由于它是一个接口所以我直接编写一个类继承它的子类DefaultHandler,重新其方法
ContentHandler handler = new ContentHandler();
// 将ContentHandler的实例设置到XMLReader中
// setContentHandler此方法设置 XML 读取器的内容处理程序
xmlReader.setContentHandler(handler);
// 开始执行解析
//InputSource:XML 实体的单一输入源。
xmlReader.parse(new InputSource(is));
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}**自己定义的ContentHandler类**
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import android.util.Log;
public class ContentHandler extends DefaultHandler {
private StringBuilder id;
private StringBuilder name;
private StringBuilder sex;
private StringBuilder age;
private StringBuilder adress;
private String nodeName;// 记录当前节点的名字
// 开始xml解析的时候调用
@Override
public void startDocument() throws SAXException {
id = new StringBuilder();
name = new StringBuilder();
sex = new StringBuilder();
age = new StringBuilder();
adress = new StringBuilder();
}
// 开始解析某个节点的时候调用
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
nodeName = localName;
}
// 获取某个节点中的内容时调用
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if ("id".equals(nodeName)) {
id.append(ch, start, length);
} else if ("name".equals(nodeName)) {
name.append(ch, start, length);
} else if ("age".equals(nodeName)) {
age.append(ch, start, length);
} else if ("sex".equals(nodeName)) {
sex.append(ch, start, length);
} else if ("adress".equals(nodeName)) {
adress.append(ch, start, length);
}
}
//完成某个节点的解析的时候调用
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if ("student".equals(localName)) {
Log.d("ContentHandler", "id is" + id.toString().trim());
Log.d("ContentHandler", "name is" + name.toString().trim());
Log.d("ContentHandler", "age is" + age.toString().trim());
Log.d("ContentHandler", "sex is" + sex.toString().trim());
Log.d("ContentHandler", "adress is" + adress.toString().trim());
// 最后要将StringBuilder清空掉
id.setLength(0);
name.setLength(0);
age.setLength(0);
sex.setLength(0);
adress.setLength(0);
}
}
//完成整个XML解析的时候调用
@Override
public void endDocument() throws SAXException {
// TODO Auto-generated method stub
super.endDocument();
}
}**2.pull解析**
[code]package com.example.xmlpull;
import android.app.Activity;
import android.content.res.AssetManager;
import android.os.Bundle;
import android.util.Log;
import android.util.Xml;
import android.view.View;
import android.widget.Toast;
import org.xmlpull.v1.XmlPullParser;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
*
* 读取到xml的声明返回数字0 START_DOCUMENT;
* 读取到xml的结束返回数字1 END_DOCUMENT ;
* 读取到xml的开始标签返回数字2 START_TAG
* 读取到xml的结束标签返回数字3 END_TAG
* 读取到xml的文本返回数字4 TEXT
*
*/
public class MainActivity extends Activity {
/**
* 用于装载解析出来的数据
*/
private List<Map<String, Object>> oList;
private Map<String, Object> oMap;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
}
public void btn_pull(View v) {
// 获取设备管理器对象
AssetManager manager = this.getAssets();
try {
// 得到assets文件下的Student.xml文件输入流
InputStream is = manager.open("Student.xml");
// 得到pull解析对象,它的构造器是受保护的,因而只能用newInstance()方法获得实例
XmlPullParser parser = Xml.newPullParser();
// 将xml文件输入流传给pull解析对象
parser.setInput(is, "UTF-8");
// 获取解析时的事件类型,
int type = parser.getEventType();
// 使用while循环,如果解析的事件类型不等于全文档最后节点类型,一直解析
while (type != XmlPullParser.END_DOCUMENT) {
// 得到当前的节点名字
String nodeName = parser.getName();
switch (type) {
// 如果是全文档的开始节点类型
case XmlPullParser.START_DOCUMENT:
// 初始化装载数据的集合
oList = new ArrayList<Map<String, Object>>();
break;
// 如果是group开始节点类型
case XmlPullParser.START_TAG:
// 根据解析的节点名字进行判断
if ("students".equals(nodeName)) {
} else if ("student".equals(nodeName)) {
oMap = new HashMap<String, Object>();
// 得到group开头的student节点
String id = parser.getAttributeValue(0);
oMap.put("id", id);
} else if ("name".equals(nodeName)) {
// 节点对应的文本
String name = parser.nextText();
oMap.put("name", name);
} else if ("sex".equals(nodeName)) {
String sex = parser.nextText();
oMap.put("sex", sex);
} else if ("age".equals(nodeName)) {
String age = parser.nextText();
oMap.put("age", age);
} else if ("adress".equals(nodeName)) {
String adress = parser.nextText();
oMap.put("adress", adress);
}
break;
// 到了group最后的节点
case XmlPullParser.END_TAG:
if ("name".equals(nodeName)) {
Toast.makeText(this, "姓名解析完成", Toast.LENGTH_LONG)
.show();
}
if ("student".equals(nodeName)) {
oList.add(oMap);
}
break;
}
//切换到下一个group
type = parser.next();
}
} catch (Exception e) {
e.printStackTrace();
}
//最后遍历集合Log
for (int i = 0; i < oList.size(); i++) {
Log.e("error",
"name:" + oList.get(i).get("name") + "----sex:"
+ oList.get(i).get("sex") + "----age:"
+ oList.get(i).get("age") + "----address:"
+ oList.get(i).get("adress"));
}
}
}首先说一下DOM解析需要注意的地方,因为讲这个的时候我们老师就犯了这个错误,这里特别指出一下
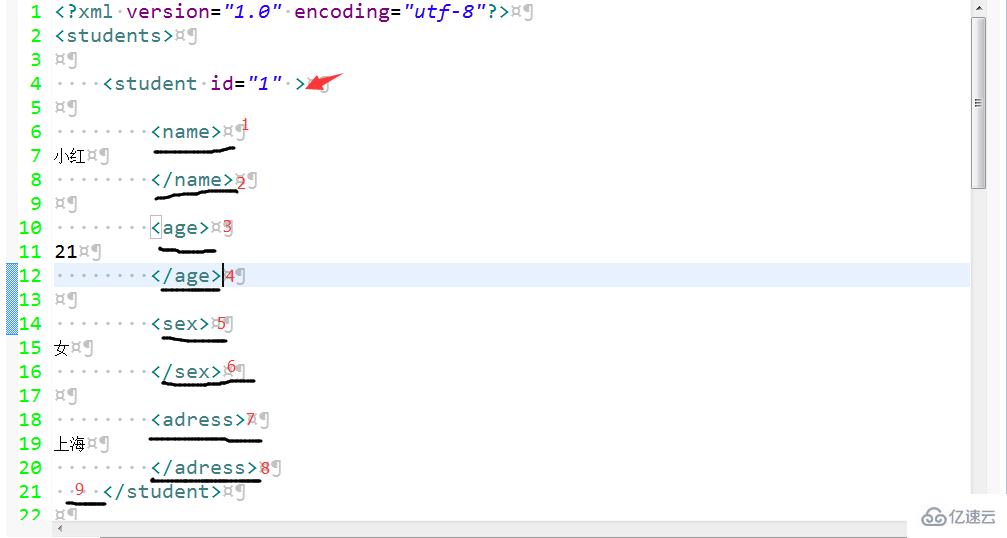
在这里当我们得到节点student时,也就是图中箭头所画的地方,如果我们调用它的getChildNodes()方法,大家猜猜它的子节点有几个?不包括它的孙子节点,小红这种的除外,因为它是孙子节点。它总共有5个子节点,分别是图中黑色横线标记的那样。所以在解析时,一定要小心,不要忽略空白的地方。
下面附上具体解析代码
这里我是把dom解析的部分拆分成了一个工具类
[code]package com.example.domxml;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
*Dom解析是将xml文件全部载入,组装成一颗dom树,
*然后通过节点以及节点之间的关系来解析xml文件,一层一层拨开
*/
public class Dom_xml_Util {
private List<Student> list = new ArrayList<Student>();
public List<Student> getStudents(InputStream in) throws Exception{
//获取dom解析工厂,它的构造器是受保护的,因而只能用newInstance()方法获得实例
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//使用当前配置的参数创建一个新的 DocumentBuilder 实例
//DocumentBuilder使其从 XML 文档获取 DOM 文档实例。
//使用此类,应用程序员可以从 XML 获取一个 Document
DocumentBuilder builder = factory.newDocumentBuilder();
//获取Document
Document document = builder.parse(in);
//getDocumentElement()这是一种便捷属性,该属性允许直接访问文档的文档元素的子节点
//Element 接口表示 HTML 或 XML 文档中的一个元素
Element element = document.getDocumentElement();
//以文档顺序返回具有给定标记名称的所有后代 Elements 的 NodeList
NodeList bookNodes = element.getElementsByTagName("student");
//遍历NodeList
//getLength()列表中的节点数
for(int i=0;i<bookNodes.getLength();i++){
//返回集合中的第 i个项
Element bookElement = (Element) bookNodes.item(i);
Student student = new Student();
//得到item大节点中的属性值。
student.setId(Integer.parseInt(bookElement.getAttribute("id")));
//得到大节点中的小节点的Nodelist
NodeList childNodes = bookElement.getChildNodes();
// System.out.println("*****"+childNodes.getLength());
//遍历小节点
for(int j=0;j<childNodes.getLength();j++){
/**
* getNodeType()表示基础对象的类型的节点
* Node.ELEMENT_NODE 该节点为 Element
* getNodeName()此节点的名称,取决于其类型
* getFirstChild() 此节点的第一个子节点
* getNodeValue()此节点的值,取决于其类型
*/
if(childNodes.item(j).getNodeType()==Node.ELEMENT_NODE){
if("name".equals(childNodes.item(j).getNodeName())){
student.setName(childNodes.item(j).getFirstChild().getNodeValue());
}else if("age".equals(childNodes.item(j).getNodeName())){
student.setAge(Integer.parseInt(childNodes.item(j).getFirstChild().getNodeValue()));
}else if("sex".equals(childNodes.item(j).getNodeName())){
student.setSex(childNodes.item(j).getFirstChild().getNodeValue());
}else if("address".equals(childNodes.item(j).getNodeName())){
student.setAddress(childNodes.item(j).getFirstChild().getNodeValue());
}
}
}//end for j
list.add(student);
}//end for i
return list;
}
}Student.class
[code]package com.example.domxml;
public class Student {
private int id;
private String name;
private int age;
private String sex;
private String address;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}在activity中调用
activity_main
[code]<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" android:orientation="vertical" > <TextView android:id="@+id/tv_id" android:layout_width="match_parent" android:layout_height="wrap_content" /> <TextView android:id="@+id/tv_name" android:layout_width="match_parent" android:layout_height="wrap_content" /> <TextView android:id="@+id/tv_age" android:layout_width="match_parent" android:layout_height="wrap_content" /> <TextView android:id="@+id/tv_sex" android:layout_width="match_parent" android:layout_height="wrap_content" /> <TextView android:id="@+id/tv_adress" android:layout_width="match_parent" android:layout_height="wrap_content" /> </LinearLayout>
MainActivity
[code]package com.example.domxml;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import android.os.Bundle;
import android.app.Activity;
import android.content.res.AssetManager;
import android.view.Menu;
import android.view.View;
import android.widget.TextView;
public class MainActivity extends Activity {
private TextView tv_id,tv_name,tv_age,tv_sex,tv_adress;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
tv_id=(TextView)findViewById(R.id.tv_id);
tv_name=(TextView)findViewById(R.id.tv_name);
tv_age=(TextView)findViewById(R.id.tv_age);
tv_sex=(TextView)findViewById(R.id.tv_sex);
tv_adress=(TextView)findViewById(R.id.tv_adress);
}
public void bnt_parse(View v)
{
AssetManager manager=getAssets();
try {
InputStream in=manager.open("Student.xml");
List<Student> oList =new ArrayList<Student>();
try {
//返回一个泛型为Student的集合
oList = new Dom_xml_Util().getStudents(in);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//遍历集合,取集合中的第一组数据
for (int i = 0; i < oList.size(); i++) {
tv_id.setText(oList.get(0).getId());
tv_name.setText(oList.get(0).getName());
tv_age.setText(oList.get(0).getAge());
tv_sex.setText(oList.get(0).getSex());
tv_adress.setText(oList.get(0).getAddress());
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}以上是“XML文件解析SAX/DOM/PULL的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





