иҪҜRAIDзӣёе…іжҰӮеҝөд»Ӣз»ҚеҸҠй…ҚзҪ®ж–№жі•
дјҒдёҡзә§зҡ„ж•°жҚ®еә“еә”з”ЁеӨ§еӨҡйғЁзҪІеңЁRAIDзЈҒзӣҳйҳөеҲ—зҡ„жңҚеҠЎеҷЁдёҠ,иҝҷж ·иғҪжҸҗй«ҳзЈҒзӣҳзҡ„и®ҝй—®жҖ§иғҪпјҢ并иғҪеӨҹе®һзҺ°е®№й”ҷ/е®№зҒҫгҖӮ
RAIDпјҲеҶ—дҪҷзЈҒзӣҳйҳөеҲ—пјүпјҢз®ҖеҚ•зҗҶи§ЈпјҢе°ұжҳҜжӢҝдёҖдәӣе»үд»·зҡ„зЎ¬зӣҳжқҘеҒҡжҲҗйҳөеҲ—гҖӮе…¶зӣ®зҡ„ж— йқһжҳҜдёәдәҶжү©еұ•еӯҳеӮЁе®№йҮҸпјҢжҸҗеҚҮиҜ»еҶҷжҖ§иғҪпјҢе®һзҺ°ж•°жҚ®еҶ—дҪҷ(еӨҮд»Ҫе®№зҒҫ)гҖӮ
дё»жөҒзҡ„еӨ§жҰӮеҸҜд»ҘеҲҶдёәеҮ дёӘзә§еҲ«:RAID 0гҖҒRAID 1гҖҒRAID 5гҖҒRAID6гҖҒRAID 10гҖҒ RAID 01гҖҒRAID 50зӯүгҖӮ
йҖҡиҝҮдёҠйқўRAID 10зҡ„д»Ӣз»Қд№ҹе°ұжҳҺзҷҪдәҶRAID 50зҡ„жҖ§иғҪжЁЎејҸдәҶеҗ§пјҹиҝҷйҮҢе°ұдёҚд»Ӣз»ҚдәҶгҖӮ
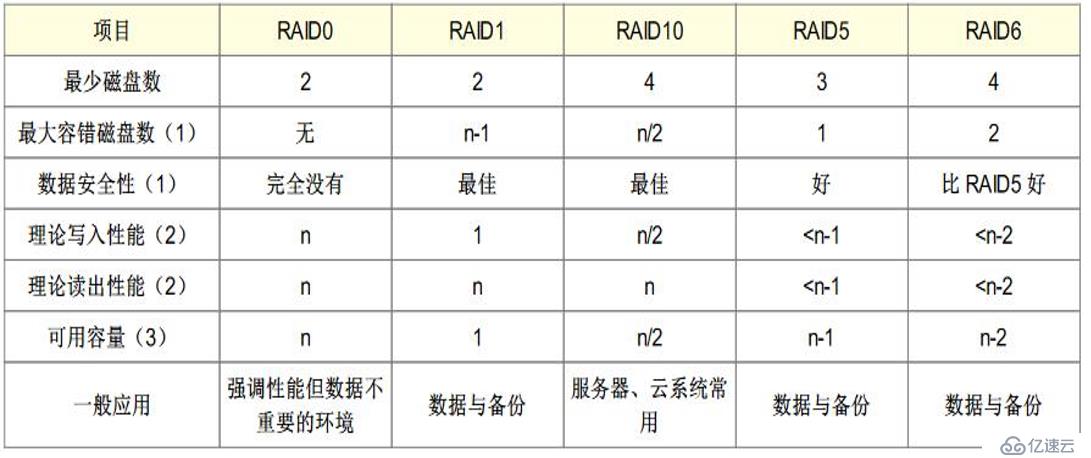
дёӢйқўжҳҜдёҖдёӘз»јеҗҲеҗ„з§ҚRAID зӯүзә§зҡ„жҖ§иғҪд»ҘеҸҠеә”з”ЁеңәжҷҜпјҡ
иҪҜRAIDй…ҚзҪ®е‘Ҫд»ӨвҖ”вҖ”mdadm
е‘Ҫд»Өж јејҸпјҡ
[root@localhost ~]# mdadm -C /dev/md5 -a yes -l 5 -n 3 -x 1 /dev/sd[b,c,d,e]
жҲ–иҖ…
[root@localhost ~]# mdadm -C /dev/md0 -ayes -l5 -n3 -x1 /dev/sd[b-e]1
е…ідәҺдёҠиҝ°зҡ„йҖүйЎ№дёҺеҸӮж•°д»Ӣз»Қпјҡ
- -C --createпјҡеҲӣе»әжЁЎејҸ
- -a --auto {yes|no}пјҡеҗҢж„ҸеҲӣе»әи®ҫеӨҮпјҢеҰӮдёҚеҠ жӯӨеҸӮж•°ж—¶еҝ…йЎ»е…ҲдҪҝз”Ёmknod е‘Ҫд»ӨжқҘеҲӣе»әдёҖдёӘRAIDи®ҫеӨҮпјҢдёҚиҝҮжҺЁиҚҗдҪҝз”Ё-a yesеҸӮж•°дёҖж¬ЎжҖ§еҲӣе»әпјӣ
- -l --level #пјҡйҳөеҲ—жЁЎејҸпјҢж”ҜжҢҒзҡ„йҳөеҲ—жЁЎејҸжңү linear, raid0, raid1, raid4, raid5, raid6, raid10, multipath, faulty, containerпјӣ
- -n #пјҡдҪҝз”Ё#дёӘеқ—и®ҫеӨҮжқҘеҲӣе»әжӯӨRAIDпјҲ-n 3 иЎЁзӨәз”Ё3еқ—зЎ¬зӣҳжқҘеҲӣе»әиҝҷдёӘRAIDпјү
- -x #пјҡеҪ“еүҚйҳөеҲ—дёӯзғӯеӨҮзӣҳеҸӘжңү#еқ—пјҲ-x 1 иЎЁзӨәзғӯеӨҮзӣҳеҸӘжңү1еқ—пјү
еҲӣе»әRAIDдёҫдҫӢпјҲд»ҘRAID 5дёәдҫӢпјү
йңҖжұӮеҰӮдёӢпјҡ
- еҲ©з”Ё4дёӘеҲҶеҢәз»„жҲҗRAID 5пјҢе…¶дёӯдёҖдёӘеҲҶеҢәдҪңдёәйў„еӨҮзЈҒзӣҳпјҢеҪ“е·ҘдҪңдёӯзҡ„RAIDжҚҹеқҸеҗҺпјҢйў„еӨҮзЈҒзӣҳйЎ¶дёҠпјӣ
- жҜҸдёӘеҲҶеҢәеӨ§е°Ҹдёә20GBпјӣ
- еҲ©з”Ё1дёӘеҲҶеҢәи®ҫзҪ®дёәйў„еӨҮеҲҶеҢәпјӣ
- жҢӮиҪҪеҲ°/testзӣ®еҪ•дҪҝз”ЁгҖ‘
ејҖе§Ӣй…ҚзҪ®пјҡ
1гҖҒеҲӣе»әRAID 5пјҡ
[root@localhost ~]# fdisk -l | grep зЈҒзӣҳ #д»ҘдёӢе°ұжҳҜз”ЁжқҘеҒҡRAID 5зҡ„зЈҒзӣҳ
..........................#зңҒз•ҘйғЁеҲҶеҶ…е®№
зЈҒзӣҳ /dev/sdbпјҡ21.5 GB, 21474836480 еӯ—иҠӮпјҢ41943040 дёӘжүҮеҢә
зЈҒзӣҳж Үзӯҫзұ»еһӢпјҡgpt
зЈҒзӣҳ /dev/sdcпјҡ21.5 GB, 21474836480 еӯ—иҠӮпјҢ41943040 дёӘжүҮеҢә
зЈҒзӣҳж Үзӯҫзұ»еһӢпјҡgpt
зЈҒзӣҳ /dev/sddпјҡ21.5 GB, 21474836480 еӯ—иҠӮпјҢ41943040 дёӘжүҮеҢә
зЈҒзӣҳж Үзӯҫзұ»еһӢпјҡgpt
зЈҒзӣҳ /dev/sdeпјҡ21.5 GB, 21474836480 еӯ—иҠӮпјҢ41943040 дёӘжүҮеҢә
зЈҒзӣҳж Үзӯҫзұ»еһӢпјҡgpt
..........................#зңҒз•ҘйғЁеҲҶеҶ…е®№
[root@localhost ~]# mdadm -C /dev/md0 -a yes -l 5 -n 3 -x 1 /dev/sd[b,c,d,e]
........................#еҝҪз•ҘйғЁеҲҶжҸҗзӨәдҝЎжҒҜ
Continue creating array? y #иҫ“е…ҘвҖңyвҖқиҝӣиЎҢзЎ®и®Ө
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started. #/dev/md0еҲӣе»әжҲҗеҠҹгҖӮ
[root@localhost ~]# cat /proc/mdstat #жҹҘиҜўеҲҡеҲҡеҲӣе»әзҡ„RAIDдҝЎжҒҜ
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdd[4] sde[3](S) sdc[1] sdb[0] #з»„жҲҗRAIDзҡ„е®һдҪ“зЈҒзӣҳеҸҠе…¶йЎәеәҸ
41908224 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
#зӣёе…ідҝЎжҒҜпјҢchunkеӨ§е°ҸеҸҠRAIDзӯүзә§иҜҙжҳҺпјҢеҗҺйқўзҡ„дёүдёӘUд»ЈиЎЁжӯЈеёёпјҢиӢҘдёҚжҳҜUеҲҷд»ЈиЎЁжңүиҜҜгҖӮ
unused devices: <none>
[root@localhost ~]# mdadm -D /dev/md0 #иҝҷдёӘе‘Ҫд»ӨжҹҘзңӢеҮәжқҘзҡ„з»“жһңжӣҙдәәжҖ§еҢ–еҶҷ
/dev/md0: #RAIDзҡ„и®ҫеӨҮж–Ү件еҗҚ
Version : 1.2
Creation Time : Thu Sep 5 09:37:42 2019 #еҲӣе»әRAIDзҡ„ж—¶й—ҙ
Raid Level : raid5 #RAIDзҡ„зӯүзә§пјҢиҝҷйҮҢжҳҜRAID5
Array Size : 41908224 (39.97 GiB 42.91 GB) #ж•ҙз»„RAIDзҡ„еҸҜз”ЁйҮҸ
Used Dev Size : 20954112 (19.98 GiB 21.46 GB) #жҜҸйў—зЈҒзӣҳзҡ„еҸҜз”Ёе®№йҮҸ
Raid Devices : 3 #з»„жҲҗRAIDзҡ„зЈҒзӣҳж•°йҮҸ
Total Devices : 4 #еҢ…жӢ¬spareзҡ„жҖ»зЈҒзӣҳж•°
Persistence : Superblock is persistent
Update Time : Thu Sep 5 09:39:28 2019
State : clean #зӣ®еүҚиҝҷдёӘRAIDзҡ„дҪҝз”ЁзҠ¶жҖҒ
Active Devices : 3 #еҗҜеҠЁзҡ„и®ҫеӨҮж•°йҮҸ
Working Devices : 4 #зӣ®еүҚдҪҝз”ЁдәҺжӯӨRAIDзҡ„и®ҫеӨҮж•°йҮҸ
Failed Devices : 0 #жҚҹеқҸзҡ„и®ҫеӨҮж•°йҮҸ
Spare Devices : 1 #йў„еӨҮзЈҒзӣҳзҡ„ж•°йҮҸ
Layout : left-symmetric
Chunk Size : 512K #chunkзҡ„е°ҸеҢәеқ—е®№йҮҸ
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : d395d245:8f9294b4:3223cd47:b0bee5d8
Events : 18
#д»ҘдёӢжҳҜжҜҸдёӘзЈҒзӣҳзҡ„дҪҝз”Ёжғ…еҶөпјҢеҢ…жӢ¬дёүдёӘactive syncе’ҢдёҖдёӘspare
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
4 8 48 2 active sync /dev/sdd
3 8 64 - spare /dev/sde
#RaidDeviceжҳҜжҢҮжӯӨRAIDеҶ…зҡ„зЈҒзӣҳйЎәеәҸ
2гҖҒж јејҸеҢ–并иҝӣиЎҢжҢӮиҪҪдҪҝз”Ёпјҡ
[root@localhost ~]# mkfs.xfs /dev/md0 #ж јејҸеҢ–еҲҡеҲҡеҲӣе»әзҡ„RAID 5
[root@localhost ~]# mkdir /test #еҲӣе»әжҢӮиҪҪзӮ№
[root@localhost ~]# mount /dev/md0 /test #жҢӮиҪҪ
[root@localhost ~]# df -hT /test #зЎ®и®ӨжҢӮиҪҪпјҢдҪҝз”Ёиө·жқҘе’Ңжҷ®йҖҡж–Ү件系з»ҹжІЎжңүеҢәеҲ«
ж–Ү件系з»ҹ зұ»еһӢ е®№йҮҸ е·Із”Ё еҸҜз”Ё е·Із”Ё% жҢӮиҪҪзӮ№
/dev/md0 xfs 40G 33M 40G 1% /test
#е°ҶжҢӮиҪҪдҝЎжҒҜеҶҷе…Ҙ/etc/fstabдёӯиҝӣиЎҢејҖжңәиҮӘеҠЁжҢӮиҪҪдәҶпјҢи®ҫеӨҮеҗҚеҸҜд»ҘжҳҜ/dev/md0пјҢд№ҹеҸҜд»ҘжҳҜи®ҫеӨҮзҡ„UUIDгҖӮ
[root@localhost ~]# blkid /dev/md0 #жҹҘиҜўиҜҘRAID 5зҡ„UUID
/dev/md0: UUID="93830b3a-69e4-4cbf-b255-f43f2ae4864b" TYPE="xfs"
[root@localhost ~]# vim /etc/fstab #жү“ејҖ/etc/fstabпјҢеҶҷе…ҘдёӢйқўеҶ…е®№
UUID=93830b3a-69e4-4cbf-b255-f43f2ae4864b /test xfs defaults 0 0
3гҖҒжөӢиҜ•RAID 5пјҡ
е…ідәҺжөӢиҜ•пјҢеҝ…然ж¶үеҸҠеҲ°дәҶдёҖдәӣз®ЎзҗҶRAIDзҡ„еҸӮж•°пјҢеҰӮдёӢпјҡ
- -f --failпјҡдјҡе°ҶеҗҺйқўзҡ„и®ҫеӨҮи®ҫзҪ®жҲҗдёәеҮәй”ҷзҡ„зҠ¶жҖҒпјӣ
- -a --addпјҡдјҡе°ҶеҗҺйқўзҡ„и®ҫеӨҮеҠ е…ҘеҲ°иҝҷдёӘmdдёӯпјӣ
- -r --removeпјҡдјҡе°ҶеҗҺйқўиҝҷдёӘи®ҫеӨҮз”ұиҝҷдёӘmdдёӯ移йҷӨпјӣ
[root@localhost ~]# echo "hi,girl,good morning." > /test/a.txt #еҶҷе…Ҙж•°жҚ®
[root@localhost ~]# cat /test/a.txt #жҹҘзңӢ
hi,girl,good morning.
[root@localhost ~]# mdadm /dev/md0 -f /dev/sdb #е°Ҷ/dev/sdbжҚҹеқҸ
mdadm: set /dev/sdb faulty in /dev/md0
[root@localhost ~]# mdadm -D /dev/md0 #жҹҘзңӢRAID 5зҡ„зҠ¶жҖҒ
/dev/md0:
Version : 1.2
Creation Time : Thu Sep 5 09:37:42 2019
Raid Level : raid5
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Sep 5 10:47:00 2019
State : clean
Active Devices : 3
Working Devices : 3
Failed Devices : 1 #жҹҘеҲ°еӨұиҙҘзҡ„зЈҒзӣҳжңү1дёӘ
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : d395d245:8f9294b4:3223cd47:b0bee5d8
Events : 39
Number Major Minor RaidDevice State
3 8 64 0 active sync /dev/sde
1 8 32 1 active sync /dev/sdc
4 8 48 2 active sync /dev/sdd
0 8 16 - faulty /dev/sdb #иҝҷе°ұжҳҜеҲҡжүҚжҚҹеқҸзҡ„зЈҒзӣҳ
#еҸҜд»ҘеҸ‘зҺ°дҪңдёәйў„еӨҮзЈҒзӣҳе·Із»ҸйЎ¶жӣҝдәҶжҚҹеқҸзҡ„зЈҒзӣҳдәҶ
[root@localhost ~]# df -hT /test #еҸҜз”Ёе®№йҮҸиҝҳжҳҜ40G
ж–Ү件系з»ҹ зұ»еһӢ е®№йҮҸ е·Із”Ё еҸҜз”Ё е·Із”Ё% жҢӮиҪҪзӮ№
/dev/md0 xfs 40G 33M 40G 1% /test
root@localhost ~]# mdadm /dev/md0 -r /dev/sdb #е°ҶжҚҹеқҸзҡ„зЈҒзӣҳ移йҷӨRAIDз»„
mdadm: hot removed /dev/sdb from /dev/md0
[root@localhost ~]# mdadm /dev/md0 -a /dev/sdf #ж·»еҠ дёҖеқ—зЈҒзӣҳеҲ°RAIDз»„
mdadm: added /dev/sdf
[root@localhost ~]# mdadm -D /dev/md0 #жҹҘзңӢRAIDз»„зҡ„жҲҗе‘ҳзҠ¶жҖҒ
/dev/md0:
.............#зңҒз•ҘйғЁеҲҶеҶ…е®№
Number Major Minor RaidDevice State
3 8 64 0 active sync /dev/sde
1 8 32 1 active sync /dev/sdc
4 8 48 2 active sync /dev/sdd
5 8 80 - spare /dev/sdf
#ж–°ж·»еҠ зҡ„зЈҒзӣҳе·Із»ҸжҲҗдёәдәҶRAIDз»„зҡ„йў„еӨҮзЈҒзӣҳ
4гҖҒе°ҶRAIDз»„йҮҚи®ҫзҪ®дёәжҷ®йҖҡзЈҒзӣҳ
[root@localhost ~]# umount /test
[root@localhost ~]# vim /etc/fstab
.............#зңҒз•ҘйғЁеҲҶеҶ…е®№
UUID=93830b3a-69e4-4cbf-b255-f43f2ae4864b /test xfs defaults 0 0
#е°Ҷи®ҫзҪ®зҡ„RAID 5иҮӘеҠЁжҢӮиҪҪеҲ йҷӨ
[root@localhost ~]# dd if=/dev/zero of=/dev/md0 bs=1M count=50
#жҚҹеқҸRAIDзҡ„и¶…зә§еҢәеқ—
[root@localhost ~]# mdadm --stop /dev/md0 #еҒңжӯўRAIDзҡ„дҪҝз”Ё
mdadm: stopped /dev/md0
#д»ҘдёӢж“ҚдҪңжҳҜе°ҶRAIDдёӯжҲҗе‘ҳзЈҒзӣҳзҡ„и¶…зә§еқ—дҝЎжҒҜиҰҶзӣ–
[root@localhost ~]# dd if=/dev/zero of=/dev/sdc bs=1M count=10
[root@localhost ~]# dd if=/dev/zero of=/dev/sdd bs=1M count=10
[root@localhost ~]# dd if=/dev/zero of=/dev/sde bs=1M count=10
[root@localhost ~]# dd if=/dev/zero of=/dev/sdf bs=1M count=10
[root@localhost ~]# cat /proc/mdstat #зЎ®и®ӨдёӢйқўдёҚеӯҳеңЁиҜҘRAID
Personalities : [raid6] [raid5] [raid4]
unused devices: <none>
з»ҸиҝҮд»ҘдёҠж“ҚдҪңеҚіжҒўеӨҚжҲҗдәҶжҷ®йҖҡзЈҒзӣҳпјҢдҪҶжҳҜеҺҹжң¬зҡ„ж•°жҚ®йғҪжІЎжңүдәҶпјҢеҗҺз»ӯдҪҝз”ЁжІЎжңүж·ұе…Ҙз ”з©¶пјҢеҸҜд»ҘдҪҝз”ЁдёҖдәӣйҮҚж–°жЈҖжөӢзҡ„е‘Ҫд»ӨиҝӣиЎҢзі»з»ҹжү«жҸҸжҲ–иҖ…йҮҚеҗҜзі»з»ҹпјҢеҚіеҸҜжҢӮиҪҪдҪҝз”ЁпјҢеҗҰеҲҷеҸҜиғҪдјҡжҢӮиҪҪдёҚдёҠгҖӮ
йҮҚж–°жЈҖжөӢе‘Ҫд»Өпјҡ
[root@localhost ~]# partprobe /dev/sdc
вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ” жң¬ж–ҮиҮіжӯӨз»“жқҹпјҢж„ҹи°ўйҳ…иҜ»





