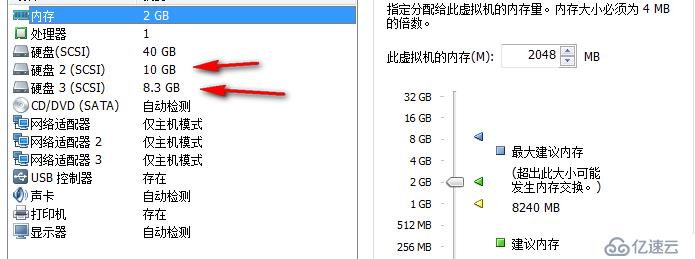
前面两篇文章中,老王和大家介绍了存储复制的功能,在单机对单机,以及延伸群集的实践,基本上大家可以看出,这是一种基于块级别的存储复制,原生内置于Windows Server 2016上面,可以帮助我们实现在单机对单机场景下的灾备,也可以结合群集,实现存储和应用结合,当发生站点级别灾难的时候,自动转移存储和应用
对于工程师来说,现在架构上又多了一个新的选择,我们可以不借助设备,不借助第三方产品,就使用微软原生的OS实现高可用+灾难恢复
虽然说延伸群集很好,但是仍有一个弊端,即不能直接使用各节点本地磁盘完成存储复制,各站点节点还必须接入自己站点的存储,两个站点需以非对称共享存储的方式来完成复制,老王猜想微软的本意,就是希望把延伸群集这项功能用于异地站点不同共享存储,例如北京站点各节点接入北京站点的存储,天津站点各节点接入天津站点的存储,然后呢,在两个Site之间做存储复制,以实现延伸群集的效果,即便是本地站点存储和计算节点全部崩溃,另外一个站点也可以使用
不过老王猜想应该还是群集机制的原因,导致目前延伸群集还不能使用各节点本地磁盘,因为微软群集设计之初就是要求实现群集存储永久保留,群集数据存放共享存储,以便切换直接挂载,如果直接本地磁盘进入群集磁盘,故障切换上会有一些问题
虽然说微软2016有了S2D技术,可以实现超融合存储,但是它本质上功能和我们讲的灾难恢复还是有一些区别,S2D老王认为是存储+群集结合起来的一项技术,我们在群集上面启用S2D,之后通过一个存储汇流排把各个节点的磁盘汇集在一起,但是注意,这里并不是说各节点的本地磁盘直接就进到群集磁盘,而是在群集存储里面机箱的区域可以看到所有节点的可用磁盘,我们开启S2D后,可以相当于我们逻辑的构建了一个存储机柜,这个存储机柜里面的存储是来自各个节点的磁盘,接下来要怎么用呢,我们还需要在这个逻辑的存储机柜上面划分Lun给各个节点接入,所以我们创建存储池,虚拟磁盘,实现容错,分层,缓存,最终交付到群集上面是虚拟磁盘,虚拟磁盘就可以被认作是一个群集磁盘,但是事实上只会显示一个群集磁盘,即便这个虚拟磁盘是通过逻辑存储机柜,多个节点创建出来的。
所以,在老王看来,S2D是借助于群集,实现了一个逻辑存储机柜,然后分配存储给群集应用使用,所以这个概念大家可以看到,和我们的存储复制还是有一些出入,相对来看,似乎业界都是通过S2D这样的超融合架构来实现延伸群集
直接底层S2D逻辑存储机柜的层面做好站点感知,然后分配给群集,存储在底层已经做好了容错,微软为什么没有实现这种架构,老王猜想应该是优化和机制的问题
1.当前S2D只能做到机架感知和机箱感知,不能做到站点感知,即没办法控制数据撒到不同站点
2.S2D对于网络性能要求太高,不适用于延伸群集场景
也maybe,过几个版本微软会针对于S2D做站点感知的优化,到时我们就可以实现超融合延伸群集,或者灾难恢复延伸群集
就目前的情况来看,我们只能通过灾难恢复来实现延伸群集的效果,那么很多朋友可能会问,为什么延伸群集不能和S2D相结合一起来用
首先老王认为在微软生态环境中这是两个解决不同场景的方案
延伸群集,是为了处理跨站点群集,存储的灾难恢复,为两个站点的存储实现复制,确保可以接受站点级别的灾难
S2D, 是为了处理存储设备昂贵,通过本地磁盘实现群集存储,通过操作系统软件实现存储设备的管理功能
如果我们使用S2D,在同一个群集内并不会显示两套存储,仅会显示一套存储,因为S2D是在底层实现的存储容错
而延伸群集需要两套存储,以实现不同站点的存储复制
所以根据目前这个定位来看,老王认为延伸群集不会和S2D有什么契合点,除非后面的版本有大变化
废弃当前通过存储复制机制实现的延伸群集,优化S2D站点感知,实现延伸群集
优化S2D站点感知,实现两种延伸群集模型
S2D架构开通一个click键,是否要实现延伸群集,如果是,则不通过底层容错,而提供两套存储,实现存储复制
就老王来看,我认为1和3的几率都不大,2的几率大一些,反正现在网络也不是瓶颈,如果企业有钱,当然可以选择用S2D实现延伸群集
事实上老王觉得目前这个存储复制实现的延伸群集效果也挺好的,对于企业没有高级存储设备,但是又想实现跨站点的灾备,通过存储复制+群集,可以实现很低的RTO和RPO,灾难切换的时候实现完全自动化,这更是一大优势
那么这是对于延伸群集中存储复制,S2D的一些探讨,对于Windows Server 2016的存储复制来说,我们还有另外一种场景,跨群集复制,将存储复制扩展至群集边界外
在这种场景中,我们就可以把S2D方案和存储复制方案相结合
前文我们提到过,存储复制解决方案对于存储没有要求,底层可以是本地SCSI/SATA,ISCSI,Share SAS ,SAN,SDS,对于延伸群集来说,可能是需要非对称共享存储的架构,要是ISCSI,SAN,JBOD等架构,但是对于单机对单机或者群集对群集来说,就没有这么多说法了,我们可以使用本地磁盘和SDS架构,在单机对单机的架构中,就相当于是,我给你系统OS提供一个存储,你别管我是怎么来的,只要两边大小一致符合要求就可以建立存储复制,群集对群集也基本上差不多,可以把一个群集看成一个大主机,两个群集就是两个大主机,你别管我这个群集的存储怎么来的,总之我群集有符合要求的存储,只要两个群集的存储配置都符合要求,就可以进行群集对群集的复制
这就有很多场景可以玩啦
例如:北京站点群集存储架构是ISCSI,天津站点群集存储架构是S2D,然后针对于两个群集做存储复制,一旦ISCSI主存储无法正常提供服务,立刻切换至天津站的提供服务,或者北京站点采用物理机部署,天津站点采用虚拟机部署,北京站点使用私有云部署群集,然后再在公有云部署群集,本地群集和存储宕机,公有云里面的群集和存储可以启动起来
群集对群集复制的好处
1.不用额外配置站点感知,如果北京群集都在北京站点,只会是群集内故障转移
2.两个站点的存储底层架构可以不一样,避免单一类型存储都出现故障
3.支持同步复制与异步复制
4.支持更复杂的架构,例如华北群集和华南群集,华北群集由北京节点和天津节点构成,华南群集由广东和深圳节点构成,各站点内部分别配置站点故障感知,北京节点坏了或者天津节点坏了无关紧要,应用会漂移至同群集的相近站点,如果整个华北地区群集全部宕机,还可以再华南群集重新启动群集角色
5.帮助实现群集级别的容灾,例如如果北京群集配置出现故障,不会影响到天津群集,天津群集可以利用复制过来的存储启动群集角色
6.两个站点可以使用不同的网络架构,以实现子网的容错
群集对群集复制的坏处
1.需要手动使用命令进行故障转移,无图形化界面操作
2.故障转移时,需事先在备群集准备好群集角色,然后重新挂载上存储
3.针对于文件服务器,跨群集故障转移后需使用新名称访问
跨群集复制技术部署需求
各复制节点操作系统需要是Windows Server 2016数据中心版
至少有四台服务器(两个群集中各两台服务器),支持最多 2 个 64 节点群集
两组共享存储, SAS JBOD、SAN、Share VHDX、S2D或 iSCSI,每个存储组设置为仅对每个群集可用
复制节点需安装File Server角色,存储副本功能,故障转移群集功能
Active Directory域环境,提供复制过程各节点的Kerberos验证
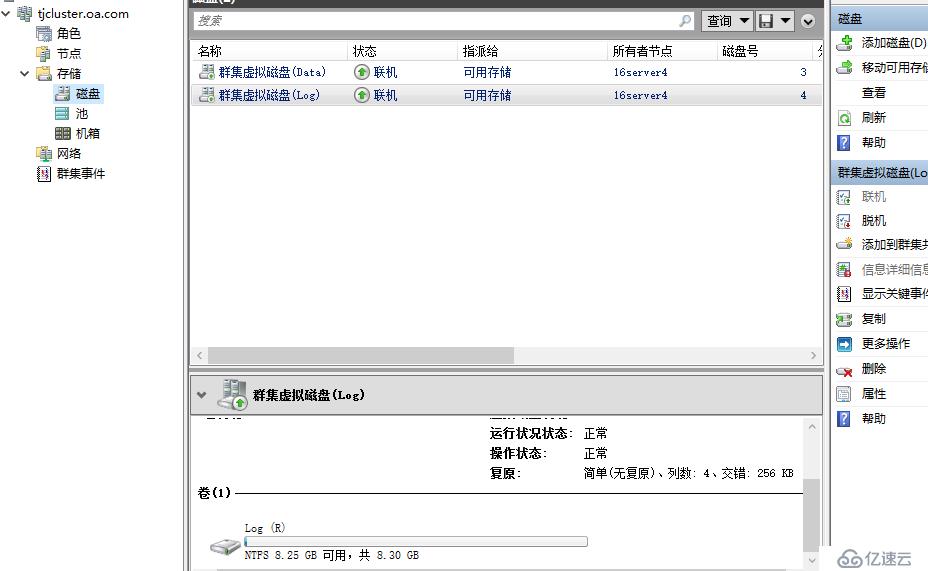
每个复制群集至少需要两个磁盘,一个数据磁盘,一个日志磁盘
数据磁盘和日志磁盘的格式必须为GPT,不支持MBR格式磁盘
两个群集数据磁盘大小与分区大小必须相同,最大 10TB
两个群集日志磁盘大小与分区大小必须相同,最少 8GB
需要为各群集内需要被复制的磁盘分配CSV或文件服务器角色
存储复制使用445端口(SMB - 复制传输协议),5895端口(WSManHTTP - WMI / CIM / PowerShell的管理协议),5445端口(iWARP SMB - 仅在使用iWARP RDMA网络时需要)
跨群集复制规划建议
建议为日志磁盘使用SSD,或NVME SSD,存储复制首先写入数据至日志磁盘,良好的日志磁盘性能可以帮助提高写入效率
建议规划较大的日志空间,较大的日志允许从较大的中断中恢复速度更快,但会消耗空间成本。
为同步复制场景准备可靠高速的网络带宽,建议1Gbps起步,最好10Gbps,同步复制场景,如果带宽不足,将延迟应用程序的写入请求时间
针对于跨云,跨国,或者远距离的跨群集复制,建议使用异步复制
跨群集复制可以整合的其它微软技术
部署:Nano Server , SCVMM
管理:PS,Azure ASR,WMI,Honolulu,SCOM,OMS,Azure Stack
整合:Hyper-V,Storage Spaces Direct ,Scale-Out File Server,SMB Multichannel,SMB Direct,重复资料删除,ReFS,NTFS
微软跨群集复制场景实作
本例模拟两座异地群集相互复制,北京站点两个节点,天津站点两个节点,北京站点有一台DC,也承载ISCSI服务器角色,北京站点群集使用ISCSI存储架构,天津站点两个节点,使用S2D架构,分别模拟节点宕机,站点宕机,站点恢复后反向复制。
AD&北京ISCSI
Lan:10.0.0.2 255.0.0.0
ISCSI:30.0.0.2 255.0.0.0
16Server1
MGMT: 10.0.0.3 255.0.0.0 DNS 10.0.0.2
ISCSI:30.0.0.3 255.0.0.0
Heart:18.0.0.3 255.0.0.0
16Server2
MGMT: 10.0.0.4 255.0.0.0 DNS 10.0.0.100
ISCSI:30.0.0.4 255.0.0.0
Heart:18.0.0.4 255.0.0.0
天津站点
16Server3
MGMT: 10.0.0.5 255.0.0.0 DNS 10.0.0.2
S2D:30.0.0.5 255.0.0.0
Heart:19.0.0.5 255.0.0.0
16Server4
MGMT: 10.0.0.6 255.0.0.0 DNS 10.0.0.2
S2D:30.0.0.6 255.0.0.0
Heart:19.0.0.6 255.0.0.0
由于我们采用群集对群集架构,因此网络上面也更加灵活,例如,心跳网络不必都在同一个网段内,因为心跳网络是群集级别,跨群集了之后即便你在一个网段,另外的群集也不知道,管理网络也可以使用不同的子网,例如如果不做多个复制组,不做多活的话,那么天津的对外网络可以设置在一个安全的网段下,正常不对外提供服务,再通过网络策略限制存储复制流量从ISCSI卡到S2D卡,这样只需要打通两个群集的存储流量即可,天津如果有DC,则最好群集可以使用天津站点DC。当灾难发生时,再把北京的网络和天津的管理网络打通,让北京用户访问天津的角色
操作流程
1.北京站点接入存储
2.北京站点创建群集
3.北京站点创建群集角色
4.天津站点接入存储
5.天津站点创建群集
6.天津站点开启S2D
7.天津站点创建群集角色
8.分配互相群集权限
9.创建存储复制
10.站点灾难恢复
北京站点接入存储
16server1
16server2
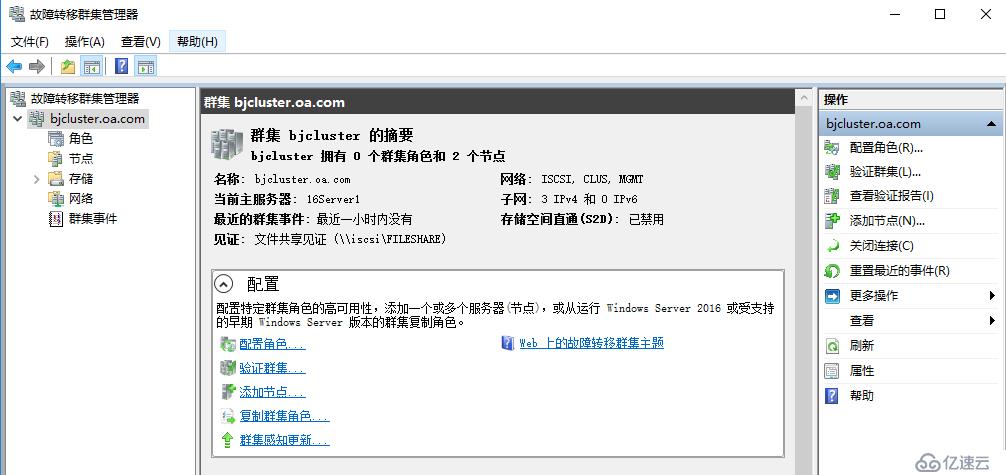
北京站点创建群集,配置群集仲裁为文件共享见证或云见证
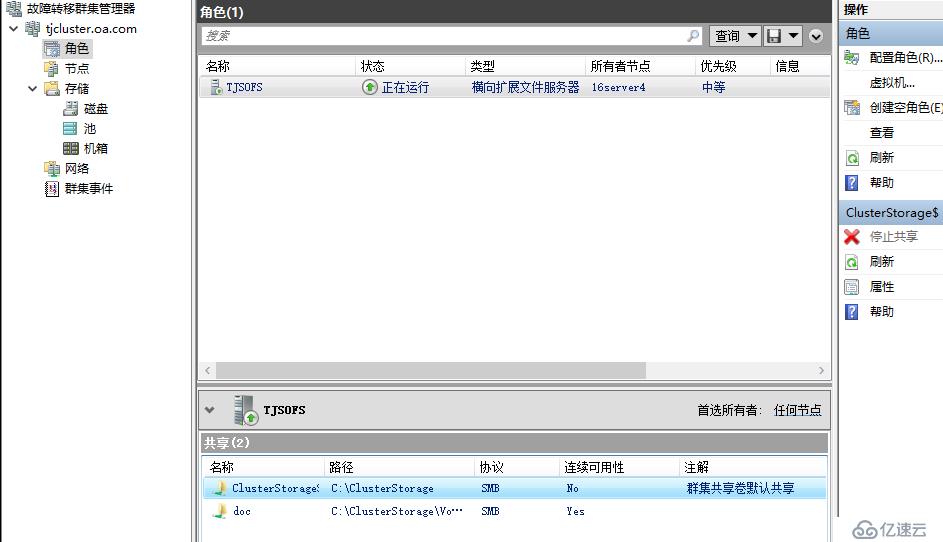
北京站点创建文件服务器群集角色
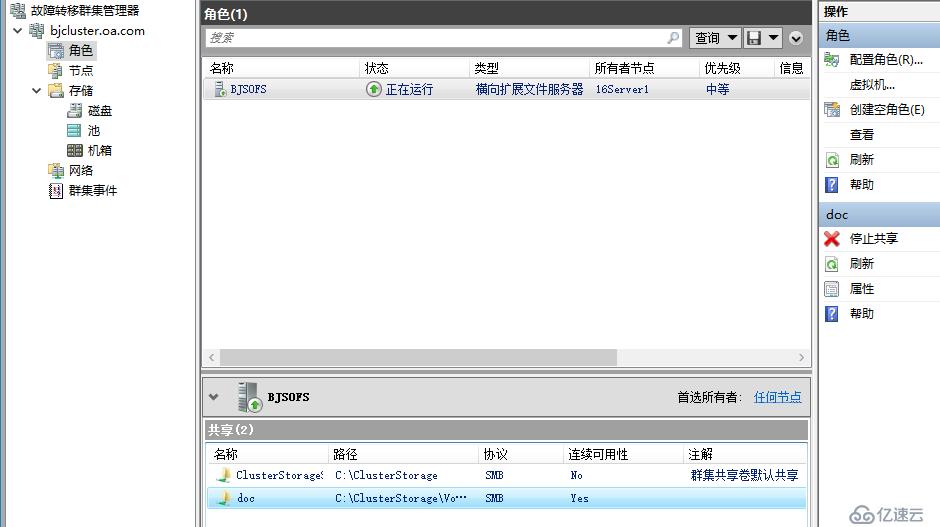
可以看到,老王这里创建的群集角色是SOFS,这是跨群集复制和延伸群集的不同点,延伸群集的时候微软说明负载只是CSV和传统高可用文件服务器角色,但是在跨群集复制时场景又变成了可以支持SOFS,我们都知道SOFS主要强调的是文件服务器双活以及透明故障转移,由于在延伸群集中故障转移需要先存储切换再转移角色,因此很难实现透明故障转移,在跨群集复制时,可能由于是两个群集,所以每个群集内部可以部署SOFS,实现群集内部的透明故障转移,至于站点故障,则没办法完全透明
天津各节点接入本地存储,大小随意,最后我们在群集存储空间上面会重新创建群集磁盘
16server3
16server4
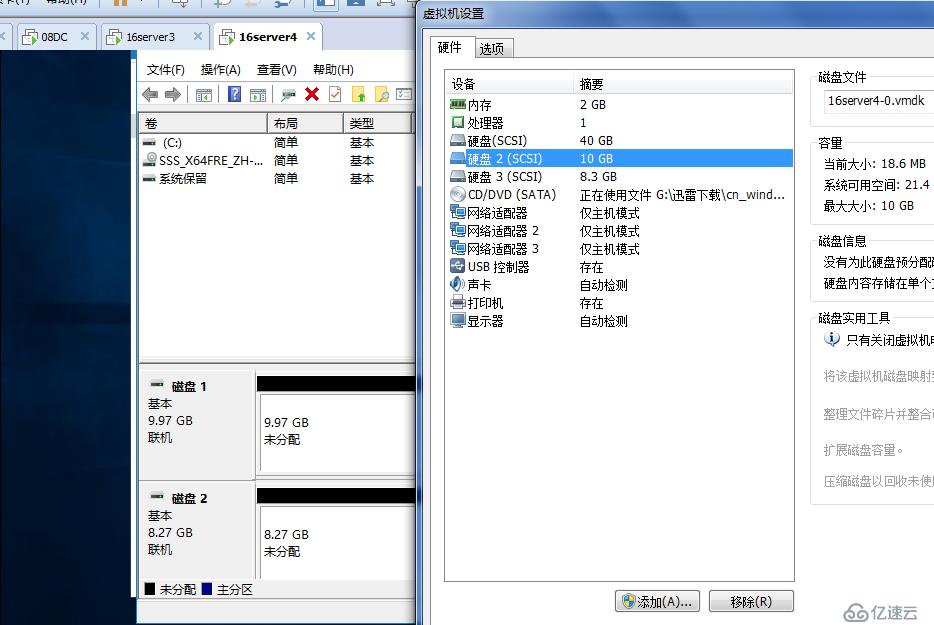
拿到存储后,各节点把磁盘联机,初始化为GPT磁盘即可,不要直接对磁盘进行分区操作,我们需要再通过S2D包上一层才能交付给群集
天津站点创建S2D群集
New-Cluster -Name TJCluster -Node 16Server3,16Server4 -StaticAddress 10.0.0.20 –NoStorage
注:执行前确保节点已符合S2D需求,生产环境建议执行群集验证


开启群集S2D功能
Enable-ClusterS2D -CacheState disabled -Autoconfig 0 -SkipEligibilityChecks
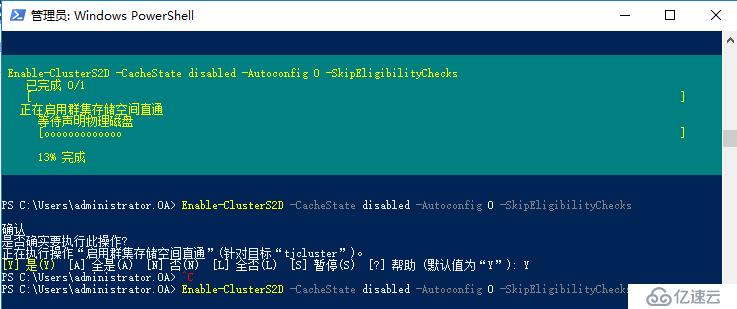
如果你是在vmware workstation上面模拟这个实验,你会发现开启S2D的过程会始终卡在这里,没办法进行下去,查看日志发现S2D一直没办法识别磁盘
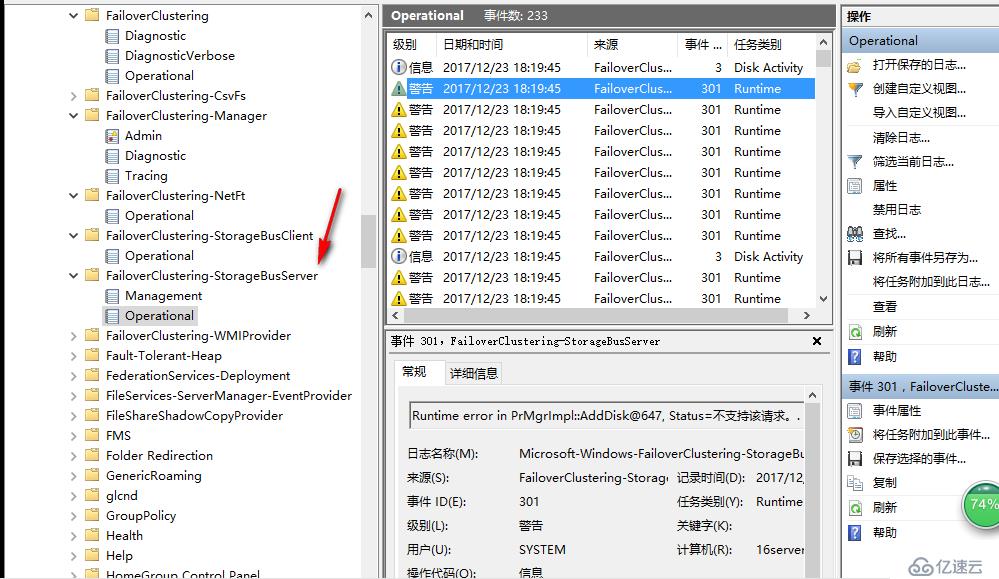
但是到底是什么原因识别不了磁盘呢,vmware虚拟上来的磁盘是SAS总线的,也符合S2D的需求,经过一番研究后,老王找到了原因,原来通过vmware虚拟出来的虚拟机没有Serial Number,而开启S2D会去找磁盘的这个数字,找不到,所以磁盘没办法被声明为S2D可用

通过在vmware虚拟机vmx配置文件关机添加参数即可
disk.EnableUUID="true"
添加完成后开机可以看到Serial Number已经可以正常显示

配置各节点磁盘MediaType标签
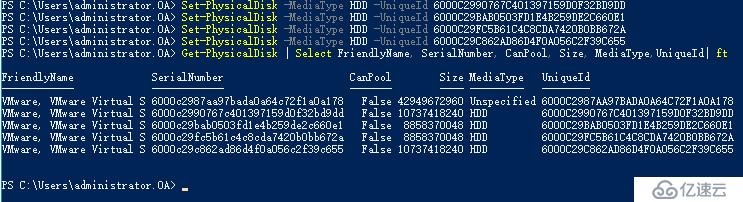
再次开启S2D,顺利通过,现在我们可以在vmware workstation上面模拟S2D实验!
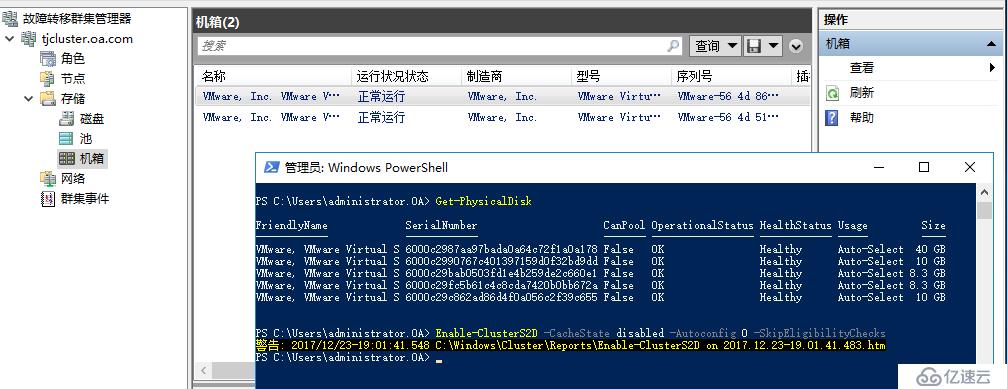
创建群集存储池
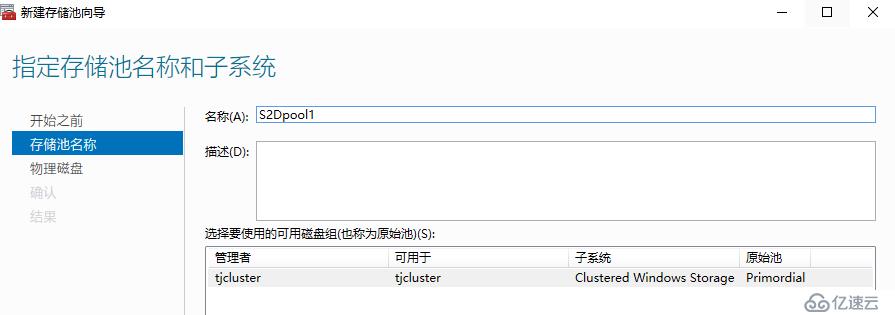
新建虚拟磁盘(存储空间),这里的虚拟磁盘交付出来就是群集磁盘,所以我们要和北京群集的群集磁盘大小确保一致,以便实现存储复制
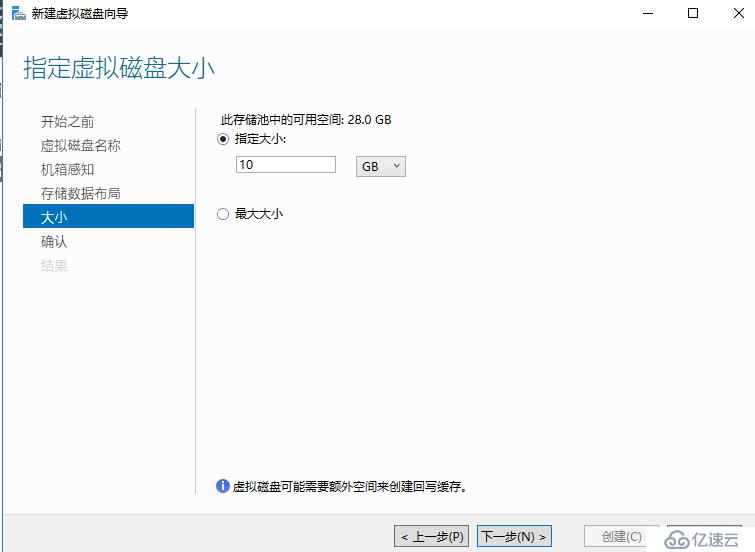
数据磁盘
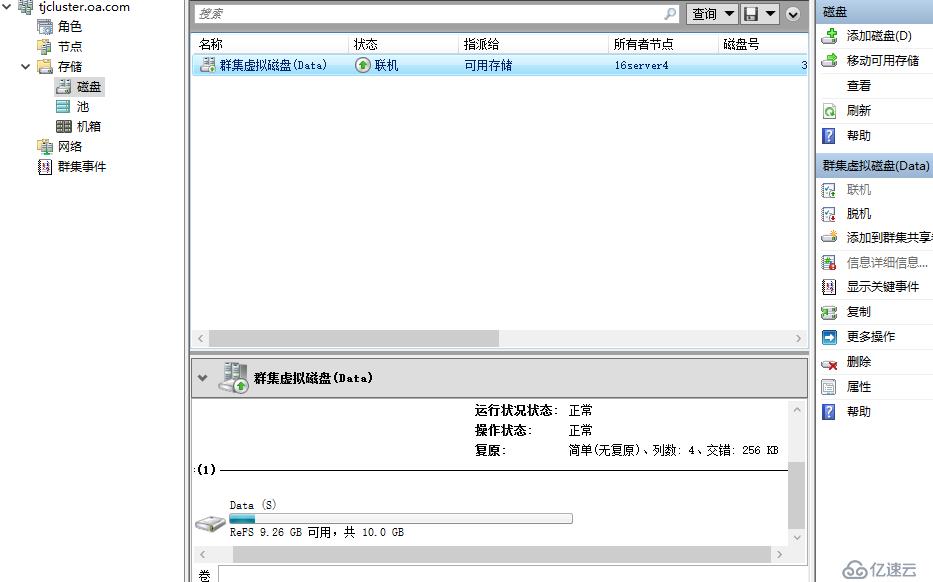
日志磁盘
天津站点配置群集角色
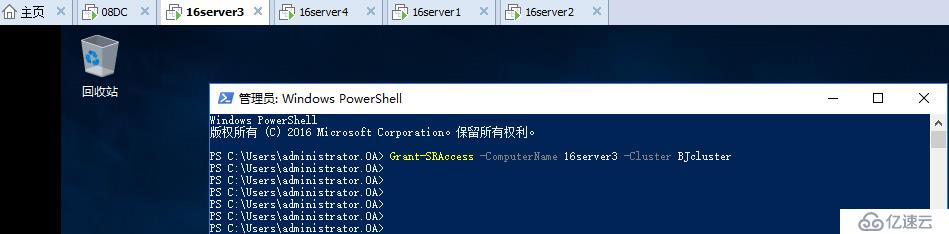
在天津站点任意节点上授予到北京站点群集的权限
Grant-SRAccess -ComputerName 16server3 -Cluster BJcluster
在北京站点任意节点上授予到天津站点群集的权限
Grant-SRAccess -ComputerName 16server1 -Cluster TJcluster

创建群集对群集复制关系
New-SRPartnership -SourceComputerName bjcluster -SourceRGName rg01 -SourceVolumeName C:\ClusterStorage\Volume1 -SourceLogVolumeName R: -DestinationComputerName tjcluster -DestinationRGName rg02 -DestinationVolumeName C:\ClusterStorage\Volume1 -DestinationLogVolumeName R:
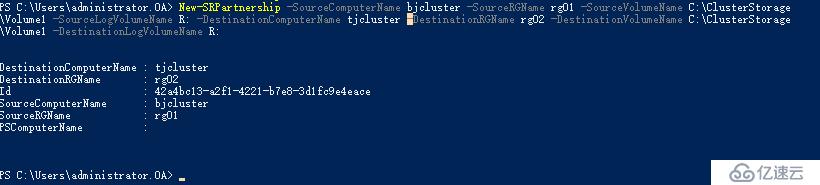
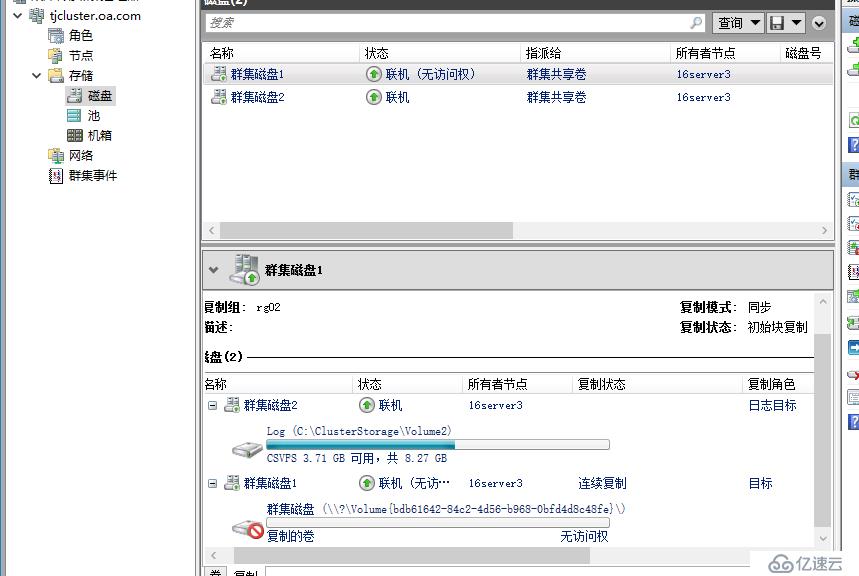
创建完成复制关系后,当前天津群集的数据磁盘会变成 联机(无访问权) ,到这里大家需要有这个意识,对于跨群集来说,我们现在把复制的边界跨越了群集,因此每个复制组运作过程中都会有一个群集的数据磁盘是待命状态,对于待命群集,复制组内磁盘不能被使用,如果部署多个跨群集复制组,可以实现群集应用互为待命。
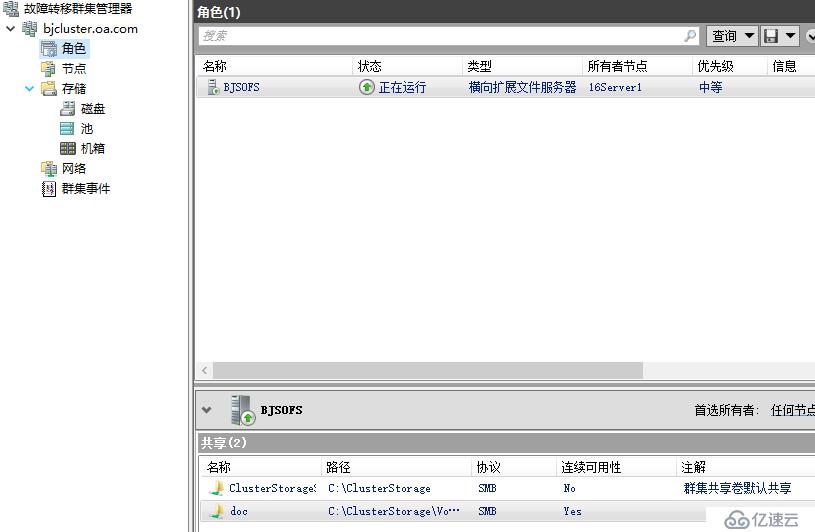
当前文件服务器群集角色在北京站点提供服务,所有者节点为16server1,已经有一些数据文件
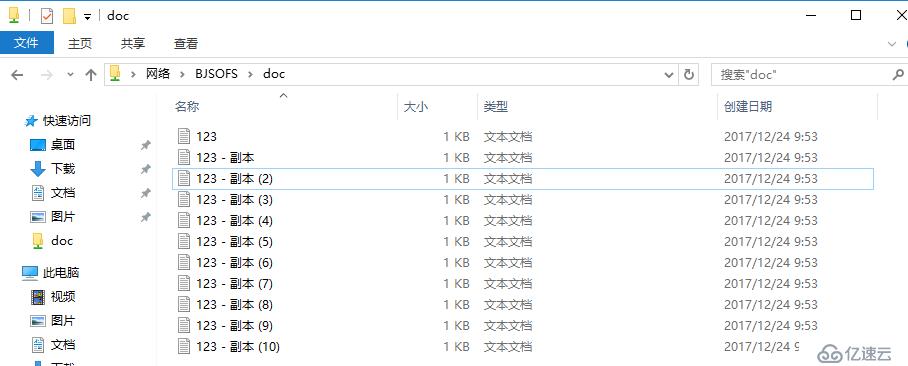
直接断电16server1,SOFS自动透明故障转移至同站点内16server2
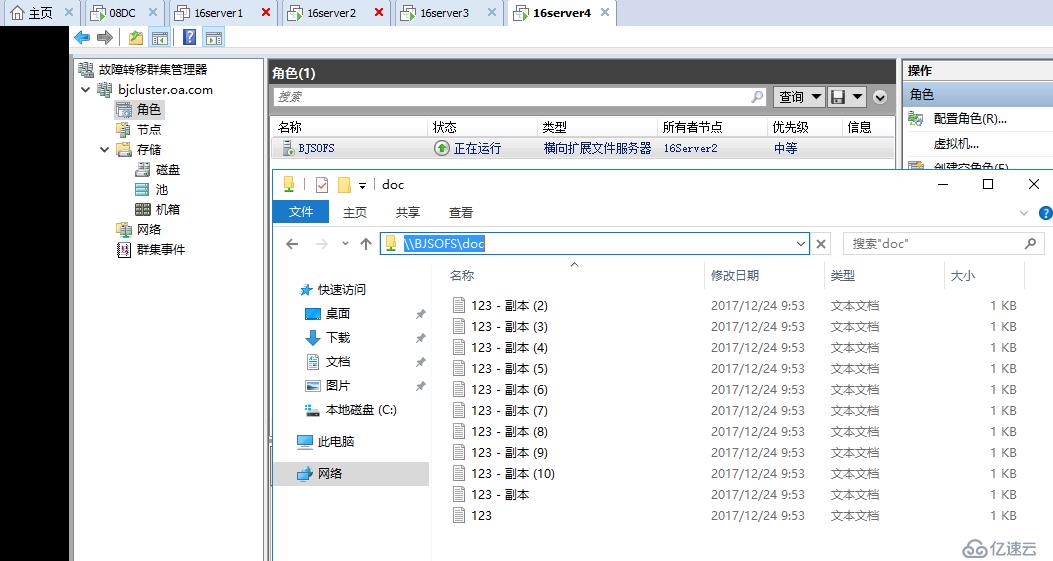
存储复制继续在同站点16server2进行,由此大家可以看出,存储复制和Hyper-V复制一样,在群集内有一个复制协调引擎,通过群集名称和外面的群集进行复制,然后再协调内部由那个节点进行复制,一旦某个群集节点宕机,自动协调另外一个节点参与复制,区别在于Hyper-V复制在群集有显式的群集角色,存储复制的群集角色是隐藏的
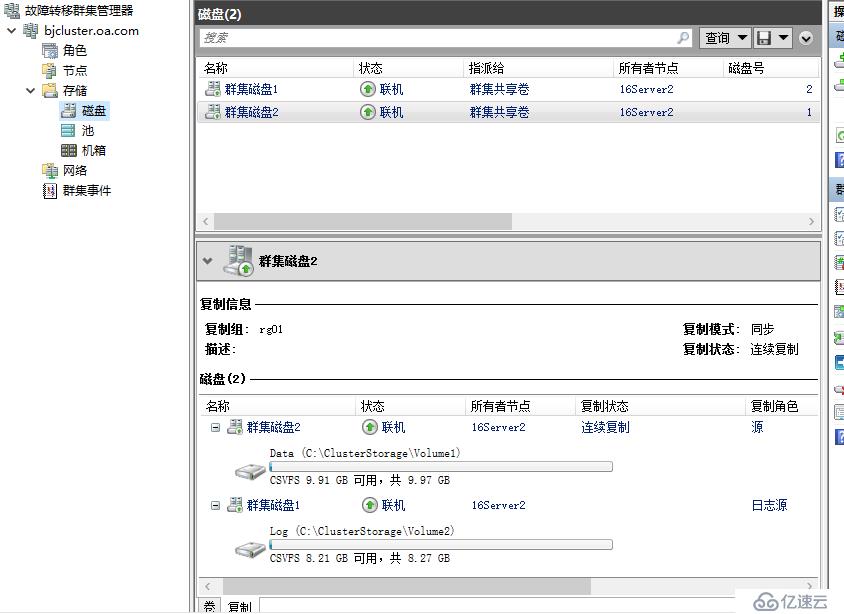
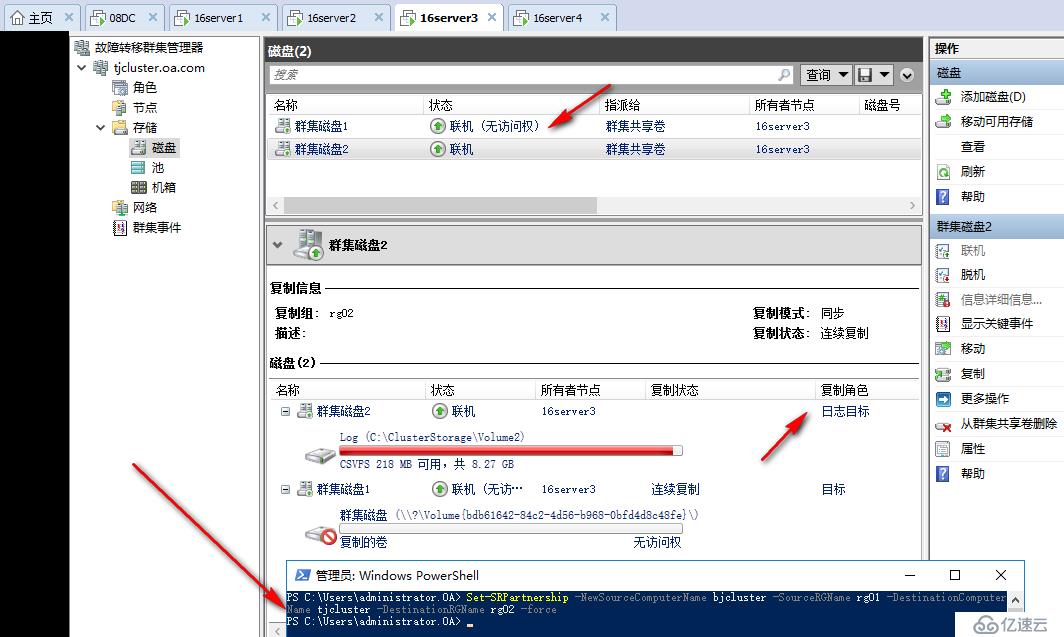
接下来模拟北京站点全部发生灾难,16server1,16server2全部断电,这时来到天津站点的群集可以看到,当前群集磁盘处于脱机状态,并不会自动完成跨群集的故障转移
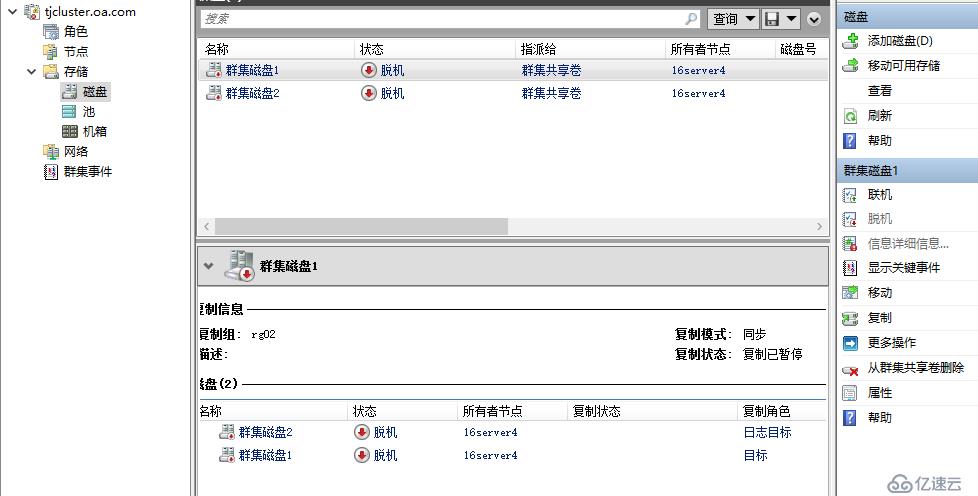
手动强制跨群集故障转移
Set-SRPartnership -NewSourceComputerName tjcluster -SourceRGName rg02 -DestinationComputerName bjcluster -DestinationRGName rg01 -force

执行完成后当前数据在天津站点可读
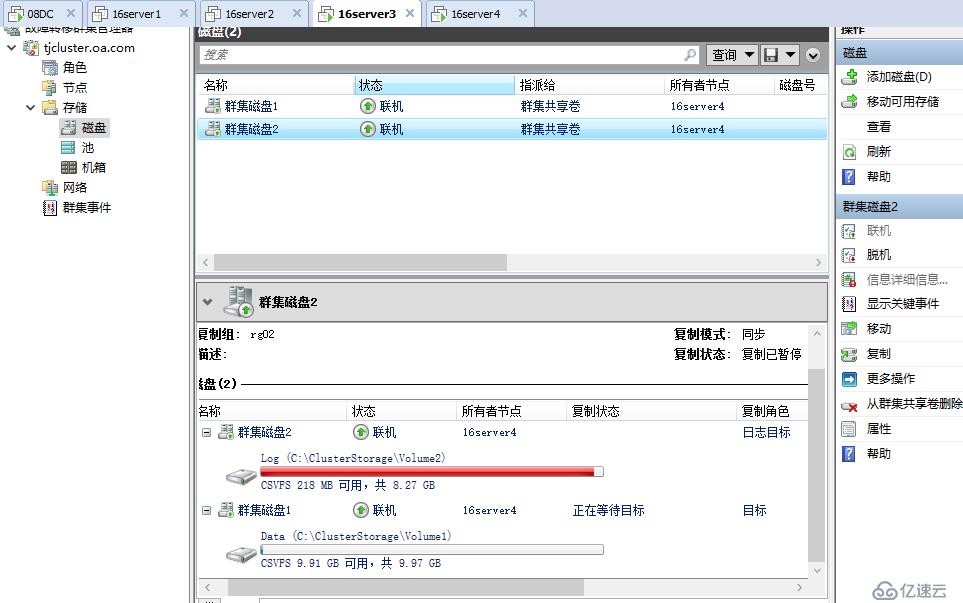
打开数据磁盘CSV可以看到北京站点的数据被完整复制过来
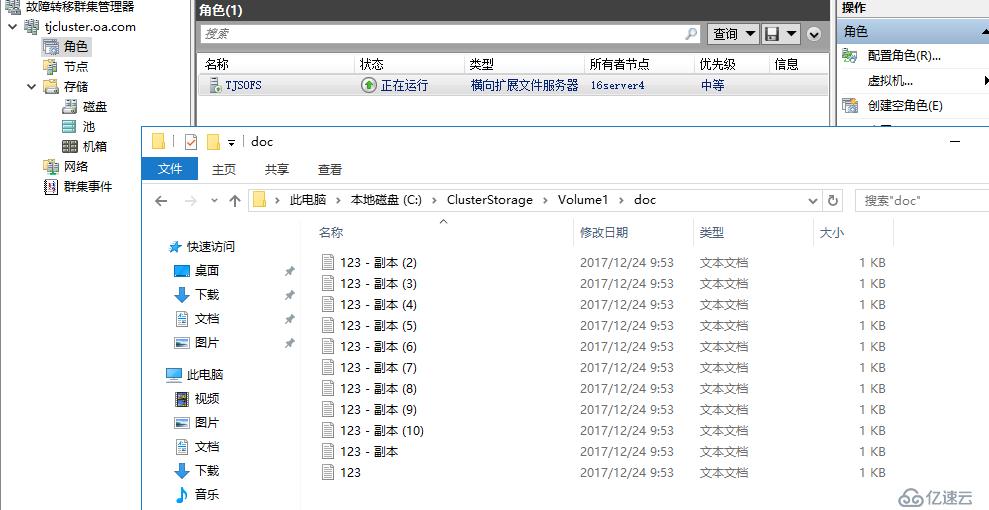
实际测试跨服务器故障转移后,共享文件夹权限并不会被自动迁移,默认情况下会是未共享状态,自行手动共享即可,猜想是跨服务器转移磁盘的缘故,如果权限较多,大家可以尝试下配合权限迁移能否映射过来,不过事实上,对于这种跨服务器故障转移的负载,实际生产环境还是建议以SQL文件,VHDX,VHD文件为主,发生跨群集故障转移后直接在新群集重新启动数据库或虚拟机角色。
现在我们完成了跨群集的灾难恢复,如果采用网络分离的架构,把天津站点的访问公开给北京用户即可,正如我们之前所说,转移后会使用新的名称进行访问
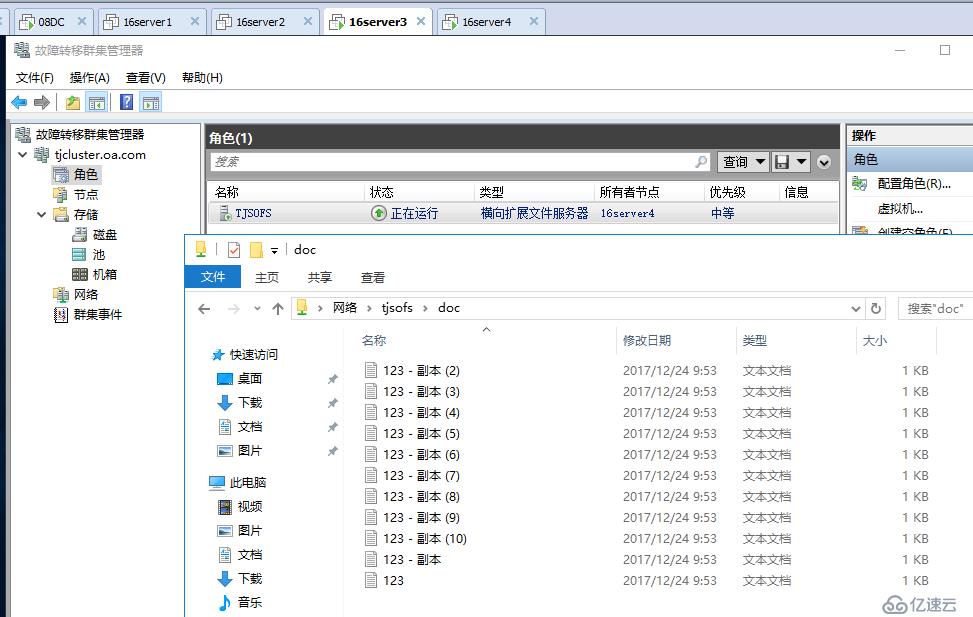
即便这时天津站点再坏掉一个节点,SOFS也可以透明故障转移至仅存的节点存活,前提是仲裁配置得当
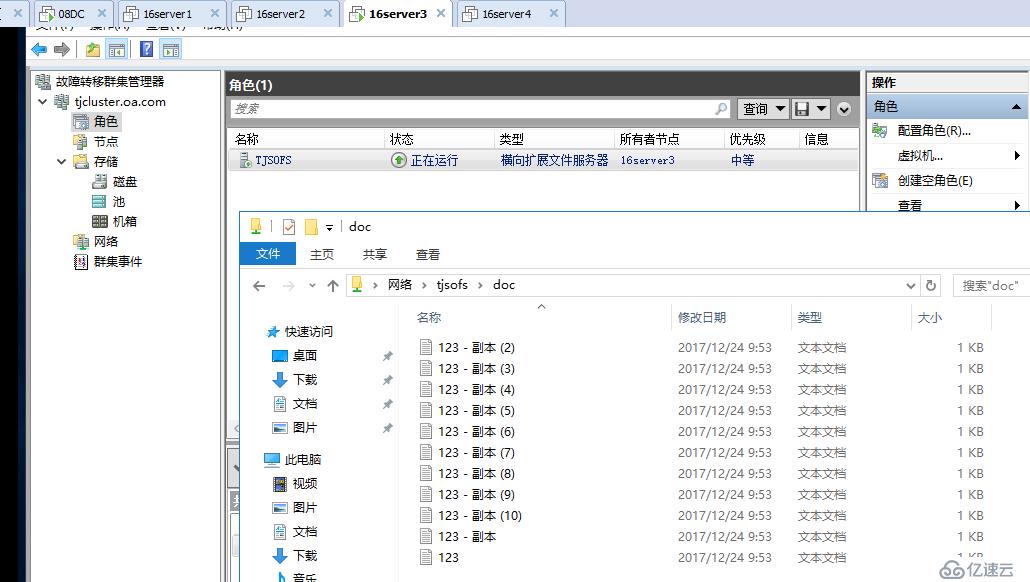
仅剩下一个最后节点时,存储复制会处于暂停状态,等待其它节点恢复
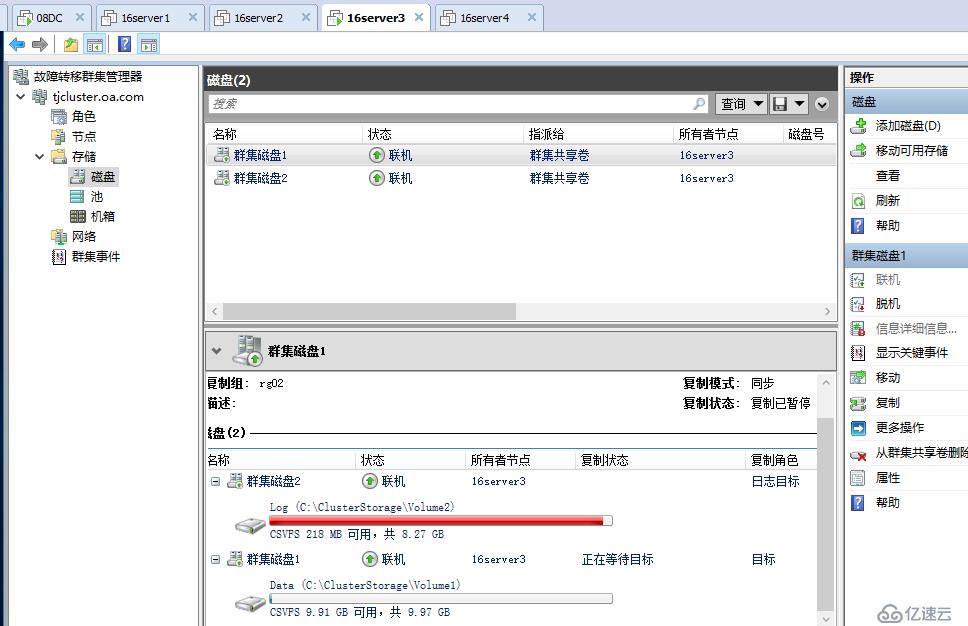
等待一段时间后,各站点服务器陆续修复完成上线,存储复制自动恢复正常连续复制,当前主复制站点为天津站点
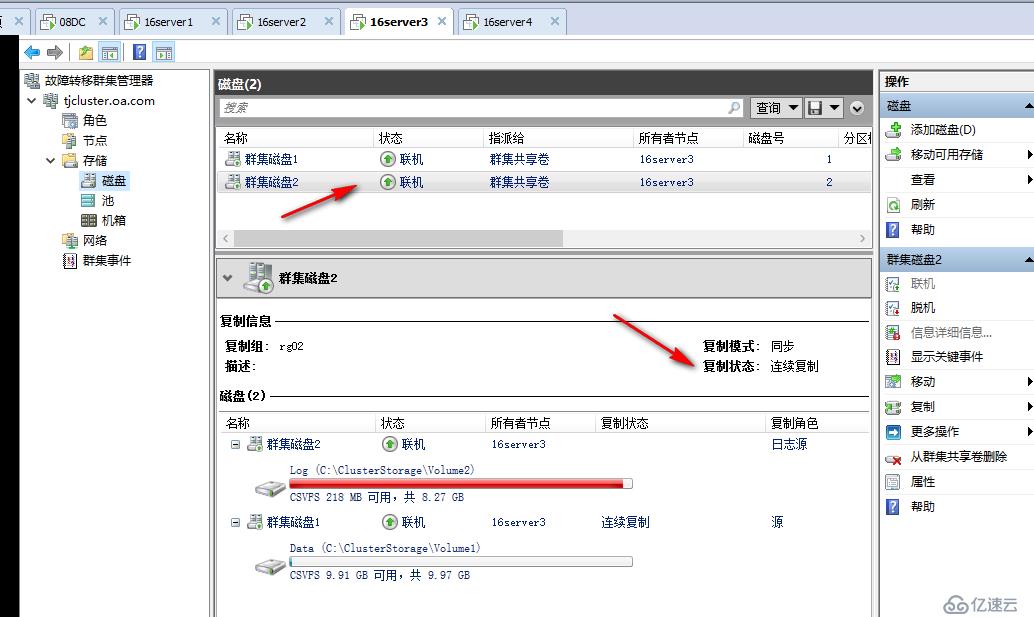
如果希望此时继续由北京站点恢复为主站点,可以执行反转复制,把天津站点内容复制回北京站点,主备关系恢复
通过三篇对于Windows Server 2016存储复制功能的介绍,相信大家对于这项技术都有了了解,很高兴的一点是听闻有的朋友看了我的博客已经开始在实际环境使用了,存储复制技术是2016存储的一项主要进步,原生的块级别复制,如果节点很少,不想维护群集的话,可以使用单机对单机场景实现灾难恢复,如果希望群集获得最低的RTO/RPO,可以使用延伸群集功能,获得自动化的灾难恢复,如果希望规划更为复杂的架构,针对于不同站点希望使用不同网络和存储架构,实现跨群集跨站点级别的灾难恢复,现在也可以实现,最终希望大家看了文章后都能有自己的思考
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





