使用Spring Batch如何实现将txt文件写入数据库?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
1、创建 Maven 项目,并在 pom.xml 中添加依赖
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.2.RELEASE</version> </parent> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.2.0</version> </dependency> <!-- 工具类依赖--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.12.6</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.4</version> </dependency> <!-- 数据库相关依赖 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.0.26</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> </dependencies>
这里是这个小项目中用到的所有依赖,包括连接数据库的依赖以及工具类等。
2、编写 Model 类
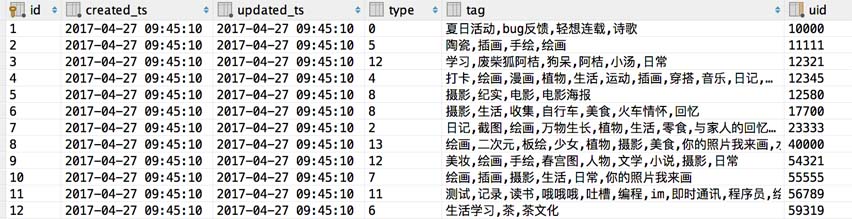
我们要从文档中读取的有效列就是 uid,tag,type,就是用户 ID,用户可能包含的标签(用于推送),用户类别(用户用户之间互相推荐)。
UserMap.java 中的 @Entity,@Column 注解,是为了利用 JPA 生成数据表而写的,可要可不要。
UserMap.java
@Data
@EqualsAndHashCode
@NoArgsConstructor
@AllArgsConstructor
//@Entity(name = "user_map")
public class UserMap extends BaseModel {
@Column(name = "uid", unique = true, nullable = false)
private Long uid;
@Column(name = "tag")
private String tag;
@Column(name = "type")
private Integer type;
}3、实现批处理配置类
BatchConfiguration.java
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
@Autowired
@Qualifier("prodDataSource")
DataSource prodDataSource;
@Bean
public FlatFileItemReader<UserMap> reader() {
FlatFileItemReader<UserMap> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("c152.txt"));
reader.setLineMapper(new DefaultLineMapper<UserMap>() {{
setLineTokenizer(new DelimitedLineTokenizer("|") {{
setNames(new String[]{"uid", "tag", "type"});
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper<UserMap>() {{
setTargetType(UserMap.class);
}});
}});
return reader;
}
@Bean
public JdbcBatchItemWriter<UserMap> importWriter() {
JdbcBatchItemWriter<UserMap> writer = new JdbcBatchItemWriter<>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
writer.setSql("INSERT INTO user_map (uid,tag,type) VALUES (:uid, :tag,:type)");
writer.setDataSource(prodDataSource);
return writer;
}
@Bean
public JdbcBatchItemWriter<UserMap> updateWriter() {
JdbcBatchItemWriter<UserMap> writer = new JdbcBatchItemWriter<>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
writer.setSql("UPDATE user_map SET type = (:type),tag = (:tag) WHERE uid = (:uid)");
writer.setDataSource(prodDataSource);
return writer;
}
@Bean
public UserMapItemProcessor processor(UserMapItemProcessor.ProcessStatus processStatus) {
return new UserMapItemProcessor(processStatus);
}
@Bean
public Job importUserJob(JobCompletionNotificationListener listener) {
return jobBuilderFactory.get("importUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(importStep())
.end()
.build();
}
@Bean
public Step importStep() {
return stepBuilderFactory.get("importStep")
.<UserMap, UserMap>chunk(100)
.reader(reader())
.processor(processor(IMPORT))
.writer(importWriter())
.build();
}
@Bean
public Job updateUserJob(JobCompletionNotificationListener listener) {
return jobBuilderFactory.get("updateUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(updateStep())
.end()
.build();
}
@Bean
public Step updateStep() {
return stepBuilderFactory.get("updateStep")
.<UserMap, UserMap>chunk(100)
.reader(reader())
.processor(processor(UPDATE))
.writer(updateWriter())
.build();
}
}prodDataSource 是假设用户已经设置好的,如果不知道怎么配置,也可以参考之前的文章进行配置:Springboot 集成 Mybatis。
reader(),这方法从文件中读取数据,并且设置了一些必要的参数。紧接着是写操作 importWriter() 和 updateWriter() ,读者看其中一个就好,因为我这里是需要更新或者修改的,所以分为两个。
processor(ProcessStatus status) ,该方法是对我们处理数据的类进行实例化,这里我根据 status 是 IMPORT 还是 UPDATE 来获取不同的处理结果。
其他的看代码就可以看懂了,哈哈,不详细说了。
4、将获得的数据进行清洗
UserMapItemProcessor.java
public class UserMapItemProcessor implements ItemProcessor<UserMap, UserMap> {
private static final int MAX_TAG_LENGTH = 200;
private ProcessStatus processStatus;
public UserMapItemProcessor(ProcessStatus processStatus) {
this.processStatus = processStatus;
}
@Autowired
IUserMapService userMapService;
private static final String TAG_PATTERN_STR = "^[a-zA-Z0-9\\u4E00-\\u9FA5_-]+$";
public static final Pattern TAG_PATTERN = Pattern.compile(TAG_PATTERN_STR);
private static final Logger LOG = LoggerFactory.getLogger(UserMapItemProcessor.class);
@Override
public UserMap process(UserMap userMap) throws Exception {
Long uid = userMap.getUid();
String tag = cleanTag(userMap.getTag());
Integer label = userMap.getType() == null ? Integer.valueOf(0) : userMap.getType();
if (StringUtils.isNotBlank(tag)) {
Map<String, Object> params = new HashMap<>();
params.put("uid", uid);
UserMap userMapFromDB = userMapService.selectOne(params);
if (userMapFromDB == null) {
if (this.processStatus == ProcessStatus.IMPORT) {
return new UserMap(uid, tag, label);
}
} else {
if (this.processStatus == ProcessStatus.UPDATE) {
if (!tag.equals(userMapFromDB.getTag()) && !label.equals(userMapFromDB.getType())) {
userMapFromDB.setType(label);
userMapFromDB.setTag(tag);
return userMapFromDB;
}
}
}
}
return null;
}
/**
* 清洗标签
*
* @param tag
* @return
*/
private static String cleanTag(String tag) {
if (StringUtils.isNotBlank(tag)) {
try {
tag = tag.substring(tag.indexOf("{") + 1, tag.lastIndexOf("}"));
String[] tagArray = tag.split(",");
Optional<String> reduce = Arrays.stream(tagArray).parallel()
.map(str -> str.split(":")[0])
.map(str -> str.replaceAll("\'", ""))
.map(str -> str.replaceAll(" ", ""))
.filter(str -> TAG_PATTERN.matcher(str).matches())
.reduce((x, y) -> x + "," + y);
Function<String, String> str = (s -> s.length() > MAX_TAG_LENGTH ? s.substring(0, MAX_TAG_LENGTH) : s);
return str.apply(reduce.get());
} catch (Exception e) {
LOG.error(e.getMessage(), e);
}
}
return null;
}
protected enum ProcessStatus {
IMPORT,
UPDATE;
}
public static void main(String[] args) {
String distinctTag = cleanTag("Counter({'《重新定义》': 3, '轻想上的轻小说': 3, '小说': 2, 'Fate': 2, '同人小说': 2, '雪狼八组': 1, " +
"'社会': 1, '人文': 1, '短篇': 1, '重新定义': 1, 'AMV': 1, '《FBD》': 1, '《雪狼六组》': 1, '战争': 1, '《灰羽联盟》': 1, " +
"'谁说轻想没人写小说': 1})");
System.out.println(distinctTag);
}
}读取到的数据格式如 main() 方法所示,清理之后的结果如:
轻想上的轻小说,小说,Fate,同人小说,雪狼八组,社会,人文,短篇,重新定义,AMV,战争,谁说轻想没人写小说 。
去掉了特殊符号以及数字等。使用了 Java8 的 Lambda 表达式。
并且这里在处理的时候,判断如果该数据用户已经存在,则进行更新,如果不存在,则新增。
5、Job 执行结束回调类
JobCompletionNotificationListener.java
@Component
public class JobCompletionNotificationListener extends JobExecutionListenerSupport {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
@Autowired
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void afterJob(JobExecution jobExecution) {
System.out.println("end .....");
}
}具体的逻辑可自行实现。
完成以上几个步骤,运行项目,就可以读取并写入数据到数据库了。
关于使用Spring Batch如何实现将txt文件写入数据库问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





