前言
不知不觉,技术人生·我和数据中心的故事来到了第二期,有朋友开始关心小y是谁,这不重要,我们更关心的是技术层面的分享以及给客户带来的实际的风险提示。后续我们还会继续分享中包括操作系统的小亦,中间件的小W的故事....小y这个名字,其实没有什么特殊的含义,就暂且用他来代表我们这些为数据中心奉献自己无悔青春的运维人吧!
本期分享主题
小y今天要和大家分享的是下面这么一个严肃的话题:
你的Oracle RAC是真的高可用么?还是伪高可用呢?
换句话说:
当Oracle RAC集群中的一个节点所在的分区/服务器宕掉的时候,
你是否可以和领导拍着胸脯说,
“没事,这是ORACLE RAC,还有一个节点呢!只要该节点可以抗住负载,完全可以正常对外提供服务!”
如果你再把上面那段话读一遍,是否有开始犹豫的感觉了呢?
小y再换个方法来问一下这个话题:
虽然系统上线前做过RAC高可用测试,但是当集群中的一个节点长时间运行,包括CPU、内存、进程数在内的负载在不断变化,并且又经历了一些列变更后,期间又没有再做过高可用测试,这样的情况下,如果RAC一个节点所在的分区/服务器宕掉的时候,你是否依然可以拍着胸脯坚定的说,“我的Oracle RAC其他的节点一定可以正常对外提供服务!”?
同样的问题,当多了一些话语的铺垫后,再次听到这个问题的你,答案是否又更加犹豫了呢?
小y今天就为大家奉献一个“RAC高可用丢失”的真实案例及其完整、真实的分析过程。
你可以从案例中获得什么
了解到导致Oracle RAC高可用失效的一些具体因素。
小y估计不少朋友的系统中依然还存在类似的问题,
建议参考本案例进行细致检查,排除隐患。
。
案例精彩看点预告
这个案例会有不小的难度,客户为了分析该问题发生的根因,投入了大量的人力和时间,一度没有结果。小y接手该case后,在缺少信息的情况下,问题的分析也一度陷入僵局。不过小y最终还是通过反复梳理所有线索,从一个和数据库毫不相关的小细节中找到了突破口,成功定位到了问题原因。大家可以借鉴一下这样的方法。
Part 1
故障描述
现象:Oracle RAC高可用丢失。表现如下
1)下午16点1分左右,XX系统数据库RAC集群节点2所在的P595 发生硬件故障,导致节点2 数据库所在的分区不可用。
2)但从16点1分开始,应用程序无法连接到数据库RAC集群中存活的节点1。
ORACLE数据库RAC集群未能发挥高可用架构的作用!
客户指示,务必找到问题根因,以便对系统高可用架构提出改进意见。
小y很理解,出了这样的大事,对于一个运行着几百套RAC的数据中心而言,是一个巨大的风险,其他系统是否也还存在这样的问题?什么时候会再发生?如果不找到问题根因,又如何做到由点带面全面全面梳理、检查和预防呢?
环境描述:
AIX 5.3
Oracle 10.2 2节点 RAC
HACMP+裸设备
所以,小y接到该case时,还是有很大压力的。在开始分析前,小y得到了以下信息:
1)故障时运维DBA在RAC存活节点1通过sqlplus “/as sysdba”连接到数据库挂起
2)故障时运维DBA在RAC存活节点1通过sqlplus -prelim “/as sysdba”连接到数据库挂起,加了-prelim参数连接到数据库也hang,这是很罕见的情况
3)在存活的节点1上通过 crsctl stop crs -f停止crs无法停止,命令挂起无法结束
4)在存活的节点1上通过shutdown –Fr重启操作系统,命令挂起无法结束,最终通过hmc重启分区,业务恢复正常
Part 2
分析过程
集群中一个节点宕掉,其他节点无法对外提供服务。
通常情况下,是因为当中的集群软件没有完成对整个集群状态、数据的重组,
因此数据未达到一致,所以集群其他节点无法对外提供服务。
这个环境中部署在IBM小机上,其中用到的集群软件有:
ORACLE RAC/ORACLE CRS/IBM HACMP
因此,需要分别查看这三个集群是否完成了重组、重新配置
查看一节点数据库alert日志,可以看到,RAC集群在16点1分32秒就完成了重组。
可排除该问题。

可以看到,从16:01开始网络心跳超时,开始对节点2进行剔除的动作,最终在16:01:27节点2离开集群。可排除该问题。

经AIX专家分析,未发现HACMP中出现异常
整个检查下来,没有发现异常。
既然节点2数据库所在的Lpar宕了,那么节点2的vip应该会漂移到节点1上,接下来通过netstat –in命令检查,发现节点1上居然没有节点2飘过来的VIP !
接管VIP的动作最终将由CRSD进程来完成,因此检查CRSD.log,以便查看是否在接管过程中发生了什么异常。
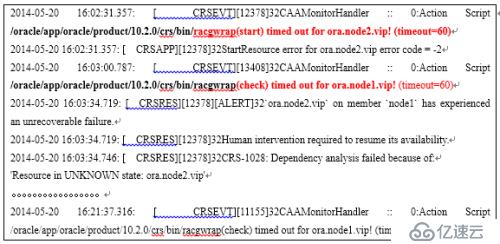
可以看到:
1)节点2当掉后,节点1的CRS要把节点2的vip、db等资源接管过来,在节点1启动,但是调用脚本racgwarp来做check/start/stop时均出现了超时timeout,从而把子进程终止了。
2)并且节点1 本身自己的 vip检测中也出现了超时,如下所示
/oracle/app/oracle/product/10.2.0/crs/bin/racgwrap(check) timed out for ora.node1.vip! (timeout=60)
3) 因此,CRS在资源管理上也出现了一定的异常,主要是调用脚本racgwrap时出现了超时异常。
Racgwrap脚本出现timeout,通常是因为:
操作系统性能缓慢,如内存大量换页
脚本执行过程出现命令挂起的情况
可以看到,5月20日的nmon居然停止在了故障时间点16点1分,这说明NMON执行到某个命令可能出现了挂起等异常

另外,从监控软件来看,操作系统未出现内存、CPU的告警。
那么,接下来,我们的分析重点到底是放在数据库还是操作系统层面呢?
通过上面的线索梳理,我们有理由相信:
操作系统在当时出现了某些异常!因此后续把分析的重点方向放在操作系统层面!
1)存活节点Sqlplus –prelim无法attach到共享内存
2)Kill -9 无法杀掉部分进程
进程处于一个原子级的调用,例如一个IO,必须在两个调用之间才可以接受进程终止的信号,说明某个原子调用无法结束导致无法被kill -9终止
3)CRS通过脚本无法接管故障节点vip,出现超时
4) CRS通过脚本无法检测存活节点本身的vip/监听等资源,均出现超时
5)存活节点Nmon故障点后无输出
虽然把方向放在操作系统上,但AIX专家未检查到异常。
AIX专家的结论是操作系统当时是没有异常的!
因为他们检查了一些crontab的脚本,是有输出的,说明OS还在工作。
如下图所示

小y把方向定到了操作系统,但是操作系统专家检查并否认操作系统有异常。
对于存活节点nmon为什么停止写入的问题,双方持不同意见。
至此,问题分析陷入僵局,小y开始思考,该如何继续往下分析呢?怎么能证明操作系统的异常呢?
1)如果没有给到操作系统一个明确的点,那么操作系统是很难查到到底有哪些异常的问题
2)问题分析陷入僵局,该如何找到突破口成为关键
3)坚信操作系统异常这个方向是正确的
回到原点,重新梳理和验证每个线索,会不会漏掉了什么重要线索

重现检查之前的线索,有重大发现!

可以看到:
从16点02分以及后续的的采样可以看到,到了” The file system result is as follows”的检测就停止了,没有写SYSTEM.SH_RUN_COMPLETE关键字来表示脚本执行完成.这说明操作系统在执行非数据库命令时也遇到了异常!
检查shell脚本,发现脚本挂在” The file system result is as follows:”的地方,事实上是调用了df命令来查看文件系统。
那么这个操作在什么情况会出现HANG的情况呢。
答案是使用nfs文件系统的时候。
XX系统数据库集群中使用了NFS文件系统,将节点2的/arch3文件系统通过NFS挂载到了节点1的/arch3文件系统上。当节点2出现硬件故障后,导致节点1无法与节点2的nfs server通讯,继而导致节点1上,df命令查看文件系统时挂起。
由此来看,节点1 nmon数据停止的原因是df命令hang住了
但是这和节点1无法连接数据库又有什么关系呢?
当小y看到df命令时,泪奔了!
所有现象都可以得到解释了!当所有现象都得到解释的时候,心里就踏实了!这意味着你找到了问题的根因,那么预防措施就万无一失了!
执行连接数据库操作时,需要获取当前工作目录(pwd)
但是由于AIX某些版本操作系统内部实现pwd过程的缺陷,导致必须递归到根目录/下检查目录或文件的权限、类型.
当检查到nfs时,由于nfs 以hard/background方式挂载,当nfs server不可用时,必然导致检查nfs目录时出现挂起,继而导致了无法获得pwd的输出结果,继而导致无法连接数据库!
1) 存活节点Sqlplus –prelim无法attach到共享内存
获取当前工作目录时,由于nfs mount点丢失,get_cwd(pwd)挂起
2) Kill -9 无法杀掉部分进程
进程对nfs mount点进行IO操作,挂起,因此没有机会收到进程终止信号
3) CRS通过脚本无法接管故障节点vip,出现超时
Racgwrap脚本中调用了pwd命令
4) CRS通过脚本无法检测存活节点本身的vip/监听等资源,均出现超时
Racgwrap脚本中调用了pwd命令
5) 存活节点Nmon故障点后无输出
Nfs mount点丢失导致nmon调用df命令时挂起
1.该机制下,如果根目录/小文件或目录很多,则pwd(get_cwd)的性能会很差
2.测试环境重现过程
节点2 mount /testfs到节点1的/testfs,停止节点2 nfs服务,未能重现。原因在于pwd的输出为/oracle, 首字母o比t要小,因此未检测到/testfs就获得pwd结果而退出了
节点2 mount /aa到节点1的/aa,停止节点2 nfs服务,未能重现。原因是通过truss命令对比,发现生产和测试环境检索/根目录下的行为不一致,继而检查OS版本,发现测试环境OS版本较高
3.高版本的OS无法重现,低版本的操作系统可以重现,说明操作系统做了修正和增强,在ibm.com上已nfs hang搜索,可以发现IBM发布了APAR来修复该问题。
Part 3
原因总结和建议
1、RAC集群节点2所在的P595 发生硬件故障,导致节点2 LPAR不可用。
继而导致Nfs mount点丢失。
2、登陆数据库时,需要获取当前工作目录(pwd)
3、但是由于AIX某些版本操作系统内部实现pwd过程的缺陷,导致必须递 归到根目录/下检查目录或文件的权限、类型.
4、当检查到nfs挂载点目录/arch3时,由于nfs 以hard/background方式 挂载,当nfs server不可用时,必然导致检查nfs目录时出现挂起,继 而导致了无法获得pwd的输出结果,继而导致无法连接数据库!
以hard/background挂载的NFS server丢失是导致RAC成为伪集群的根本原因!
所有故障现象都可以得到解释,如下:
1、存活节点Sqlplus –prelim无法attach到共享内存
获取当前工作目录时,由于nfs mount点丢失,get_cwd(pwd)挂起
2、Kill -9 无法杀掉部分进程
进程对nfs mount点进行IO操作,挂起,因此没有机会收到进程终止信号
3、CRS通过脚本无法接管故障节点vip,出现超时
Racgwrap脚本中调用了pwd命令
4、CRS通过脚本无法检测存活节点本身的vip/监听等资源,均出现超时
Racgwrap脚本中调用了pwd命令
5、存活节点Nmon故障点后无输出
Nfs mount点丢失导致nmon调用df命令时挂起
1) 如果需要实用nfs,则mount到二级目录,比如mount到/home /arch 2而不是/arch3
2) 使用gpfs代替nfs
3) 提供故障线索时,请勿根据个人经验过滤掉认为不重要的信息
4) 安装AIX APAR,改变操作系统get_cwd(pwd)调用的内部实现方式
5) 处理故障时Df命令hang的情况如果一开始就反馈给小y,那么这个
case直接就解开了,就不需要查了!
6) 只在上线前做高可用测试是不够的,因为上线后系统会经历一系列的 变更,可能某些因素会报纸RAC冗余性丢失,建议定期做高可用测 试,可以选择在变更窗口选择逐个重启实例、服务器的方式来进行验证。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





