今天就跟大家聊聊有关集算器协助java处理结构化文本的集合运算是怎样的,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
JAVA不直接支持集合运算,因此要用嵌套循环才能实现文本文件之间的交集、并集、差集 等集合运算,如果文件数量较多,或者文件较大而无法放入内存直接计算,再或者要按照多个字段进行集合运算,则相应的代码会更加复杂。集算器直接支持集合运 算,可以协助JAVA轻松实现此类算法,下面我们通过例子来看一下具体作法。
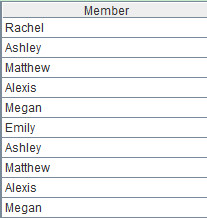
有两个小文件:f1.txt和f2.txt,***行是列名,现在需要对文件中的Name字段进行交集运算。部分数据如下:
文件f1.txt:

文件f2.txt:

集算器代码:
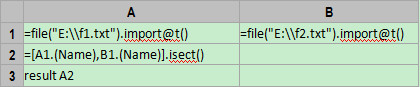
A1、B1:用import函数将文件读=[A1.(Name),B1.(Name)].isect()入内存,默认的分隔符是tab。这里的函数 选项@t表示将***行读为列名,这样一来后续的计算就可以直接用Name和Dept来引用相应的列,如果***行不是列名,则应当用_1和_2这种默认列名 来引用。
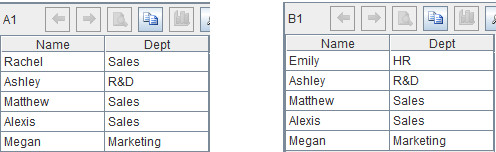
计算后A1和B1的值分别如下:
函数import可以读取指定的列,比如本案例只有Name会参与计算,因此可以只读取Name列,对应的代码是:file(“E:\\f1.txt”).import@t(Name) 。
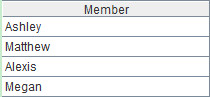
A2= 函数isect可以进行集合间的交集运算,A1.(Name)表示取出A1的Name列,形成一个集合,B1.(Name)表示取出B1的Name列。本案例的最终结果如下:
A3:result A2。这表示将计算结果输出到JDBC接口。A3可以和A2合为一步:result [A1.(Name),B1.(Name)].isect() 。
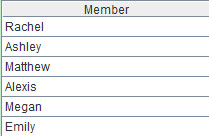
上述是求交集的过程,求并集只需换个函数:[A1.(Name),B1.(Name)].union(),计算结果如下:
求差集的代码:[A1.(Name),B1.(Name)].diff(),计算结果如下:

还有一类特殊的集合算法:和集,即求并集时保留重复的元素,和集的代码:[A1.(Name),B1.(Name)].conj(),计算结果如下:
可以直接用运算符来代替函数,写法更加简洁,比如交集,并集、差集、合集可以改写为:
A1.(Name) ^ B1.(Name)
A1.(Name) & B1.(Name)
A1.(Name) \ B1.(Name)
A1.(Name) | B1.(Name)
也可以对多个文件进行集合运算,比如f1.txt、f2.txt、f3.txt读入内存后对应的变量分别是A1、B1、C1,对它们求交集,代码如 下:A1.(Name) ^ B1.(Name) ^C1.(Name) 或 [A1.(Name),B1.(Name),C1.(Name)].isect() 。
有时候文件比较大,会影响集合运算的性能,可以用sort函数事先排序,再用merge函数来进行集合运算,这样一来性能会显著提高。其中,求交集时应当使用函数选项@i,并集使用@u,差集使用@d,对应的代码分别如下:
=[A1.(Name).sort(),B1.(Name).sort()].merge@i()
=[A1.(Name).sort(),B1.(Name).sort()].merge@u()
=[A1.(Name).sort(),B1.(Name).sort()].merge@d()
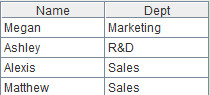
函数merge还可以进行多字段的集合运算,假设不同的Dept会存在相同的Name,现在需要将Dept和Name当作一个整体来进行交集运算, 对应的代码如下:[A1.sort(Dept,Name),B1.sort(Dept,Name)].merge@i(Dept,Name) 。
计算结果如下:
对于内存放不下的大文件,可以用cursor函数来读取文件,并用merge函数来实现集合运算。其中,求交集的代码如下:
A1=file(“e:\\f1.txt”).cursor()
B1=file(“e:\\f2.txt”).cursor()
A2=[ A1.sortx(Name),B1.sortx(Name)].merge@xi(Name)
注意,这里函数cursor并不会将数据全部读入内存,而是以游标(或流)的方式打开文件。集算器引擎会自动分配合适的缓冲区,每次读取一部分数据参与计算,再循环往复,完成最终的计算。
与内存计算不同,操作游标需要使用游标函数,比如排序时应当使用函数sortx。这里的merge函数使用了两个函数选项,@i表示求交集,@x表示参与计算的对象不是内存数据,而是游标。另外,union等函数只能进行内存数据的集合运算,不能用于大文件。
上述脚本已经完成了所有的数据处理工作,接下来通过JDBC将集算器脚本集成在JAVA里。JAVA代码如下:
//建立esProc jdbc连接 Class.forName(“com.esproc.jdbc.InternalDriver”); con= DriverManager.getConnection(“jdbc:esproc:local://”); //调用esProc,其中test是脚本文件名 st =(com.esproc.jdbc.InternalCStatement)con.prepareCall(“call test()”); st.execute();//执行esProc存储过程 ResultSet set = st.getResultSet();//获得计算结果
看完上述内容,你们对集算器协助java处理结构化文本的集合运算是怎样的有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





