本篇文章为大家展示了如何用Lucene.net全文检索实现仿造百度,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
Lucene.Net
Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,是一个Library.你也可以把它理解为一个将索引,搜索功能封装的很好的一套简单易用的API(提供了完整的查询引擎和索引引擎)。利用这套API你可以做很多有关搜索的事情,而且很方便.。开发人员可以基于Lucene.net实现全文检索的功能。
注意:Lucene.Net只能对文本信息进行检索。如果不是文本信息,要转换为文本信息,比如要检索Excel文件,就要用NPOI把Excel读取成字符串,然后把字符串扔给Lucene.Net。Lucene.Net会把扔给它的文本切词保存,加快检索速度。
更多概念性的知识可以参考这篇博文:http://blog.csdn.net/xiucool/archive/2008/11/28/3397182.aspx
这个小Demo样例展示:
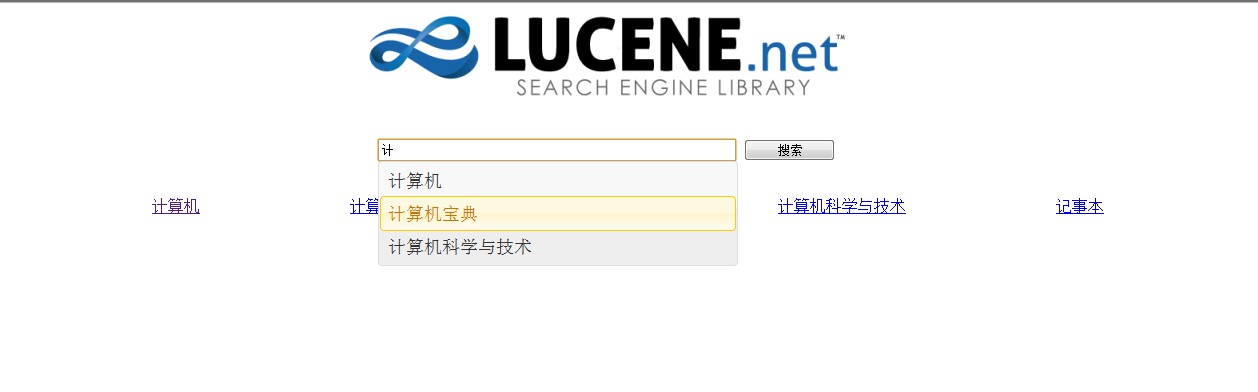

ok,接下来就细细详解下士怎样一步一步实现这个效果的。
Lucene.Net 核心——分词算法(Analyzer)
学习Lucune.Net,分词是核心。当然最理想状态下是能自己扩展分词,但这要很高的算法要求。Lucene.Net中不同的分词算法就是不同的类。所有分词算法类都从Analyzer类继承,不同的分词算法有不同的优缺点。
内置的StandardAnalyzer是将英文按照空格、标点符号等进行分词,将中文按照单个字进行分词,一个汉字算一个词
Analyzer analyzer = new StandardAnalyzer(); TokenStream tokenStream = analyzer.TokenStream("",new StringReader("Hello Lucene.Net,我1爱1你China")); Lucene.Net.Analysis.Token token = null; while ((token = tokenStream.Next()) != null) { Console.WriteLine(token.TermText()); }分词后结果:

二元分词算法,每两个汉字算一个单词,“我爱你China”会分词为“我爱 爱你 china”,点击查看二元分词算法CJKAnalyzer。
Analyzer analyzer = new CJKAnalyzer(); TokenStream tokenStream = analyzer.TokenStream("", new StringReader("我爱你中国China中华人名共和国")); Lucene.Net.Analysis.Token token = null; while ((token = tokenStream.Next()) != null) { Response.Write(token.TermText()+"<br/>"); }
这时,你肯定在想,上面没有一个好用的,二元分词算法乱枪打鸟,很想自己扩展Analyzer,但并不是算法上的专业人士。怎么办?
天降圣器,盘古分词,点击下载。
Lucene.Net核心类简介(一)
Directory表示索引文件(Lucene.net用来保存用户扔过来的数据的地方)保存的地方,是抽象类,两个子类FSDirectory(文件中)、RAMDirectory (内存中)。
IndexReader对索引进行读取的类,对IndexWriter进行写的类。
IndexReader的静态方法bool IndexExists(Directory directory)判断目录directory是否是一个索引目录。IndexWriter的bool IsLocked(Directory directory) 判断目录是否锁定,在对目录写之前会先把目录锁定。两个IndexWriter没法同时写一个索引文件。IndexWriter在进行写操作的时候会自动加锁,close的时候会自动解锁。IndexWriter.Unlock方法手动解锁(比如还没来得及close IndexWriter 程序就崩溃了,可能造成一直被锁定)。
创建索引库操作:
构造函数:IndexWriter(Directory dir, Analyzer a, bool create, MaxFieldLength mfl)因为IndexWriter把输入写入索引的时候,Lucene.net是把写入的文件用指定的分词器将文章分词(这样检索的时候才能查的快),然后将词放入索引文件。
void AddDocument(Document doc),向索引中添加文档(Insert)。Document类代表要索引的文档(文章),最重要的方法Add(Field field),向文档中添加字段。Document是一片文档,Field是字段(属性)。Document相当于一条记录,Field相当于字段。
Field类的构造函数 Field(string name, string value, Field.Store store, Field.Index index, Field.TermVector termVector): name表示字段名; value表示字段值; store表示是否存储value值,可选值 Field.Store.YES存储, Field.Store.NO不存储,Field.Store.COMPRESS压缩存储;默认只保存分词以后的一堆词,而不保存分词之前的内容,搜索的时候无法根据分词后的东西还原原文,因此如果要显示原文(比如文章正文)则需要设置存储。 index表示如何创建索引,可选值Field.Index. NOT_ANALYZED ,不创建索引,Field.Index. ANALYZED,创建索引;创建索引的字段才可以比较好的检索。是否碎尸万段!是否需要按照这个字段进行“全文检索”。 termVector表示如何保存索引词之间的距离。“北京欢迎你们大家”,索引中是如何保存“北京”和“大家”之间“隔多少单词”。方便只检索在一定距离之内的词。
private void CreateIndex() { //索引库存放在这个文件夹里 string indexPath = ConfigurationManager.AppSettings["pathIndex"]; //Directory表示索引文件保存的地方,是抽象类,两个子类FSDirectory表示文件中,RAMDirectory 表示存储在内存中 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory()); //判断目录directory是否是一个索引目录。 bool isUpdate = IndexReader.IndexExists(directory); logger.Debug("索引库存在状态:"+isUpdate); if (isUpdate) { if (IndexWriter.IsLocked(directory)) { IndexWriter.Unlock(directory); } } //第三个参数为是否创建索引文件夹,Bool Create,如果为True,则新创建的索引会覆盖掉原来的索引文件,反之,则不必创建,更新即可。 IndexWriter write = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, IndexWriter.MaxFieldLength.UNLIMITED); WebClient wc = new WebClient(); //编码,防止乱码 wc.Encoding = Encoding.UTF8; int maxID; try { //读取rss,获得第一个item中的链接的编号部分就是最大的帖子编号 maxID = GetMaxID(); } catch (WebException webEx) { logger.Error("获得最大帖子号出错",webEx); return; } for (int i = 1; i <= maxID; i++) { try { string url = "http://localhost:8080/showtopic-" + i + ".aspx"; logger.Debug("开始下载:"+url); string html = wc.DownloadString(url); HTMLDocumentClass doc = new HTMLDocumentClass(); doc.designMode = "on";//不让解析引擎尝试去执行 doc.IHTMLDocument2_write(html); doc.close(); string title = doc.title; string body = doc.body.innerText; //为避免重复索引,先输出number=i的记录,在重新添加 write.DeleteDocuments(new Term("number", i.ToString())); Document document = new Document(); //Field为字段,只有对全文检索的字段才分词,Field.Store是否存储 document.Add(new Field("number", i.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED)); document.Add(new Field("title", title, Field.Store.YES, Field.Index.NOT_ANALYZED)); document.Add(new Field("body", body, Field.Store.YES, Field.Index.ANALYZED, Field.TermVector.WITH_POSITIONS_OFFSETS)); write.AddDocument(document); logger.Debug("索引" + i.ToString() + "完毕"); } catch (WebException webEx) { logger.Error("下载"+i.ToString()+"失败",webEx); } } write.Close(); directory.Close(); logger.Debug("全部索引完毕"); } //取最大帖子号 private int GetMaxID() { XDocument xdoc = XDocument.Load("Http://localhost:8080/tools/rss.aspx"); XElement channel = xdoc.Root.Element("channel"); XElement fitstItem = channel.Elements("item").First(); XElement link = fitstItem.Element("link"); Match match = Regex.Match(link.Value, @"http://localhost:8080/showtopic-(\d+)\.aspx"); string id = match.Groups[1].Value; return Convert.ToInt32(id); }这样就创建了索引库,利用WebClient爬去所有网页的内容,这儿需要你添加引用Microsoft mshtml组件,MSHTML是微软公司的一个COM组件,该组件封装了HTML语言中的所有元素及其属性,通过其提供的标准接口,可以访问指定网页的所有元素。
当然,创建索引库最好定时给我们自动创建,类似于Windows计划任务。
在这儿你可以了解Quartz.Net
首先添加对其(我这个版本有两个,一个是Quartz.dll,还有一个是Common.Logging)的引用,貌似两个缺一不可,否则会报错,类似于文件路径错误。
在Global里配置如下:
public class Global : System.Web.HttpApplication { private static ILog logger = LogManager.GetLogger(typeof(Global)); private IScheduler sched; protected void Application_Start(object sender, EventArgs e) { //控制台就放在Main logger.Debug("Application_Start"); log4net.Config.XmlConfigurator.Configure(); //从配置中读取任务启动时间 int indexStartHour = Convert.ToInt32(ConfigurationManager.AppSettings["IndexStartHour"]); int indexStartMin = Convert.ToInt32(ConfigurationManager.AppSettings["IndexStartMin"]); ISchedulerFactory sf = new StdSchedulerFactory(); sched = sf.GetScheduler(); JobDetail job = new JobDetail("job1", "group1", typeof(IndexJob));//IndexJob为实现了IJob接口的类 Trigger trigger = TriggerUtils.MakeDailyTrigger("tigger1", indexStartHour, indexStartMin);//每天10点3分执行 trigger.JobName = "job1"; trigger.JobGroup = "group1"; trigger.Group = "group1"; sched.AddJob(job, true); sched.ScheduleJob(trigger); //IIS启动了就不会来了 sched.Start(); } protected void Session_Start(object sender, EventArgs e) { } protected void Application_BeginRequest(object sender, EventArgs e) { } protected void Application_AuthenticateRequest(object sender, EventArgs e) { } protected void Application_Error(object sender, EventArgs e) { logger.Debug("网络出现未处理异常:",HttpContext.Current.Server.GetLastError()); } protected void Session_End(object sender, EventArgs e) { } protected void Application_End(object sender, EventArgs e) { logger.Debug("Application_End"); sched.Shutdown(true); } }最后我们的Job去做任务,但需要实现IJob接口
public class IndexJob:IJob { private ILog logger = LogManager.GetLogger(typeof(IndexJob)); public void Execute(JobExecutionContext context) { try { logger.Debug("索引开始"); CreateIndex(); logger.Debug("索引结束"); } catch (Exception ex) { logger.Debug("启动索引任务异常", ex); } } }Ok,我们的索引库建立完了,接下来就是搜索了。
Lucene.Net核心类简介(二)
IndexSearcher是进行搜索的类,构造函数传递一个IndexReader。IndexSearcher的void Search(Query query, Filter filter, Collector results)方法用来搜索,Query是查询条件, filter目前传递null, results是检索结果,TopScoreDocCollector.create(1000, true)方法创建一个Collector,1000表示最多结果条数,Collector就是一个结果收集器。
Query有很多子类,PhraseQuery是一个子类。 PhraseQuery用来进行多个关键词的检索,调用Add方法添加关键词,query.Add(new Term("字段名", 关键词)),PhraseQuery. SetSlop(int slop)用来设置关键词之间的最大距离,默认是0,设置了Slop以后哪怕文档中两个关键词之间没有紧挨着也能找到。 query.Add(new Term("字段名", 关键词)) query.Add(new Term("字段名", 关键词2)) 类似于:where 字段名 contains 关键词 and 字段名 contais 关键词。
调用TopScoreDocCollector的GetTotalHits()方法得到搜索结果条数,调用Hits的TopDocs TopDocs(int start, int howMany)得到一个范围内的结果(分页),TopDocs的scoreDocs字段是结果ScoreDoc数组, ScoreDoc 的doc字段为Lucene.Net为文档分配的id(为降低内存占用,只先返回文档id),根据这个id调用searcher的Doc方法就能拿到Document了(放进去的是Document,取出来的也是Document);调用doc.Get("字段名")可以得到文档指定字段的值,注意只有Store.YES的字段才能得到,因为Store.NO的没有保存全部内容,只保存了分割后的词。
搜索的代码:
查看盘古分词文档找到高亮显示:
private string Preview(string body,string keyword) { PanGu.HighLight.SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<font color=\"Red\">","</font>"); PanGu.HighLight.Highlighter highlighter = new PanGu.HighLight.Highlighter(simpleHTMLFormatter, new Segment()); highlighter.FragmentSize = 100; string bodyPreview = highlighter.GetBestFragment(keyword, body); return bodyPreview; }因为我们页面刚进入需要加载热词,为了减轻服务端压力,缓存的使用能使我们解决这一问题。
既然是热词,当然是最近几天搜索量最多的,故Sql语句需要考虑指定的时间之内的搜索数量的排序。
public IEnumerable<Model.SearchSum> GetHotWords() { //缓存 var data=HttpRuntime.Cache["hotwords"]; if (data==null) { IEnumerable<Model.SearchSum> hotWords = DoSelect(); HttpRuntime.Cache.Insert("hotwords",hotWords,null,DateTime.Now.AddMilliseconds(30),TimeSpan.Zero ); return hotWords; } return (IEnumerable<Model.SearchSum>)data; } private IEnumerable<Model.SearchSum> DoSelect() { DataTable dt = SqlHelper.ExecuteDataTable(@" select top 5 Keyword,count(*) as searchcount from keywords where datediff(day,searchdatetime,getdate())<7 group by Keyword order by count(*) desc "); List<Model.SearchSum> list = new List<Model.SearchSum>(); if (dt!=null&&dt.Rows!=null&&dt.Rows.Count>0) { foreach (DataRow row in dt.Rows) { Model.SearchSum oneModel=new Model.SearchSum (); oneModel.Keyword = Convert.ToString(row["keyword"]); oneModel.SearchCount = Convert.ToInt32(row["SearchCount"]); list.Add(oneModel); } } return list; }搜索建议,类似于Baidu搜索时下拉提示框,Jquery UI模拟,下面是获取根据搜索数量最多的进行排序,得到IEnumerable<Model.SearchSum>集合
public IEnumerable<Model.SearchSum> GetSuggestion(string kw) { DataTable dt = SqlHelper.ExecuteDataTable(@"select top 5 Keyword,count(*) as searchcount from keywords where datediff(day,searchdatetime,getdate())<7 and keyword like @keyword group by Keyword order by count(*) desc",new SqlParameter("@keyword","%"+kw+"%")); List<Model.SearchSum> list = new List<Model.SearchSum>(); if (dt != null && dt.Rows != null && dt.Rows.Count > 0) { foreach (DataRow row in dt.Rows) { Model.SearchSum oneModel = new Model.SearchSum(); oneModel.Keyword = Convert.ToString(row["keyword"]); oneModel.SearchCount = Convert.ToInt32(row["SearchCount"]); list.Add(oneModel); } } return list; }最关键的搜索代码,详见注释和上面Lucene.Net核心类二:
protected void Page_Load(object sender, EventArgs e) { //加载热词 hotwordsRepeater.DataSource = new Dao.KeywordDao().GetHotWords(); hotwordsRepeater.DataBind(); kw = Request["kw"]; if (string.IsNullOrWhiteSpace(kw)) { return; } //处理:将用户的搜索记录加入数据库,方便统计热词 Model.SerachKeyword model = new Model.SerachKeyword(); model.Keyword = kw; model.SearchDateTime = DateTime.Now; model.ClinetAddress = Request.UserHostAddress; new Dao.KeywordDao().Add(model); //分页控件 MyPage pager = new MyPage(); pager.TryParseCurrentPageIndex(Request["pagenum"]); //超链接href属性 pager.UrlFormat = "CreateIndex.aspx?pagenum={n}&kw=" + Server.UrlEncode(kw); int startRowIndex = (pager.CurrentPageIndex - 1) * pager.PageSize; int totalCount = -1; List<SearchResult> list = DoSearch(startRowIndex,pager.PageSize,out totalCount); pager.TotalCount = totalCount; RenderToHTML = pager.RenderToHTML(); dataRepeater.DataSource = list; dataRepeater.DataBind(); } private List<SearchResult> DoSearch(int startRowIndex,int pageSize,out int totalCount) { string indexPath = "C:/Index"; FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory()); IndexReader reader = IndexReader.Open(directory, true); //IndexSearcher是进行搜索的类 IndexSearcher searcher = new IndexSearcher(reader); PhraseQuery query = new PhraseQuery(); foreach (string word in CommonHelper.SplitWord(kw)) { query.Add(new Term("body", word)); } query.SetSlop(100);//相聚100以内才算是查询到 TopScoreDocCollector collector = TopScoreDocCollector.create(1024, true);//最大1024条记录 searcher.Search(query, null, collector); totalCount = collector.GetTotalHits();//返回总条数 ScoreDoc[] docs = collector.TopDocs(startRowIndex, pageSize).scoreDocs;//分页,下标应该从0开始吧,0是第一条记录 List<SearchResult> list = new List<SearchResult>(); for (int i = 0; i < docs.Length; i++) { int docID = docs[i].doc;//取文档的编号,这个是主键,lucene.net分配 //检索结果中只有文档的id,如果要取Document,则需要Doc再去取 //降低内容占用 Document doc = searcher.Doc(docID); string number = doc.Get("number"); string title = doc.Get("title"); string body = doc.Get("body"); SearchResult searchResult = new SearchResult() { Number = number, Title = title, BodyPreview = Preview(body, kw) }; list.Add(searchResult); } return list; }Jquery UI模拟Baidu下拉提示和数据的绑定
<script type="text/javascript"> $(function () { $("#txtKeyword").autocomplete( { source: "SearchSuggestion.ashx", select: function (event, ui) { $("#txtKeyword").val(ui.item.value); $("#form1").submit(); } }); }); </script><div align="center"> <input type="text" id="txtKeyword" name="kw" value='<%=kw %>'/> <%-- <asp:Button ID="createIndexButton" runat="server" onclick="searchButton_Click" Text="创建索引库" />--%> <input type="submit" name="searchButton" value="搜索" style="width: 91px" /><br /> </div> <br /> <ul id="hotwordsUL"> <asp:Repeater ID="hotwordsRepeater" runat="server"> <ItemTemplate> <li><a href='CreateIndex.aspx?kw=<%#Eval("Keyword") %>'><%#Eval("Keyword") %></a></li> </ItemTemplate> </asp:Repeater> </ul> <br /> <asp:Repeater ID="dataRepeater" runat="server" EnableViewState="true"> <HeaderTemplate> <ul> </HeaderTemplate> <ItemTemplate> <li> <a href='http://localhost:8080/showtopic-<%#Eval("Number") %>.aspx'><%#Eval("Title") %></a> <br /> <%#Eval("BodyPreview") %> </li> </ItemTemplate> <FooterTemplate> </ul> </FooterTemplate> </asp:Repeater> <br /> <div class="pager"><%=RenderToHTML%></div>上述内容就是如何用Lucene.net全文检索实现仿造百度,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





