PythonдёӯжҖҺд№Ҳзј–еҶҷUnixз®ЎйҒ“
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іPythonдёӯжҖҺд№Ҳзј–еҶҷUnixз®ЎйҒ“пјҢж–Үз« еҶ…е®№иҙЁйҮҸиҫғй«ҳпјҢеӣ жӯӨе°Ҹзј–еҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҜ№зӣёе…ізҹҘиҜҶжңүдёҖе®ҡзҡ„дәҶи§ЈгҖӮ
дёҖдёӘж—Ҙеҝ—еӨ„зҗҶд»»еҠЎ
еә”з”ЁеңәжҷҜеҰӮдёӢпјҡ
в—Ҷ жҹҗдёӘзӣ®еҪ•еҸҠеӯҗзӣ®еҪ•дёӢжңүдёҖдәӣ web жңҚеҠЎеҷЁзҡ„ж—Ҙеҝ—ж–Ү件пјҢж—Ҙеҝ—ж–Ү件еҗҚд»Ҙ access-log ејҖеӨҙ
в—Ҷ ж—Ҙеҝ—ж јејҸеҰӮдёӢ
81.107.39.38 - ... "GET /ply/ply.html HTTP/1.1" 200 97238
81.107.39.38 - ... "GET /ply HTTP/1.1" 304 - |
е…¶дёӯ***дёҖеҲ—ж•°еӯ—дёәеҸ‘йҖҒзҡ„еӯ—иҠӮж•°пјҢиӢҘдёә вҖҳ-вҖҷ еҲҷиЎЁзӨәжІЎжңүеҸ‘йҖҒж•°жҚ®
в—Ҷзӣ®ж ҮжҳҜз®—еҮәжҖ»е…ұеҸ‘йҖҒдәҶеӨҡе°‘еӯ—иҠӮзҡ„ж•°жҚ®пјҢе®һйҷ…дёҠд№ҹе°ұжҳҜиҰҒжҠҠж—Ҙеҝ—и®°еҪ•зҡ„жІЎдёҖиЎҢзҡ„***дёҖеҲ—ж•°еҖјеҠ иө·жқҘ
жҲ‘дёҚзӣҙжҺҘеұ•зӨәеҰӮдҪ•з”Ё Unix з®ЎйҒ“зҡ„йЈҺж јжқҘеӨ„зҗҶиҝҷдёӘй—®йўҳпјҢиҖҢжҳҜе…Ҳз»ҷеҮәдёҖдәӣвҖңдёҚйӮЈд№ҲеҘҪвҖқзҡ„д»Јз ҒпјҢжҢҮеҮәе®ғ们зҡ„й—®йўҳпјҢ***еҶҚеұ•зӨәз®ЎйҒ“йЈҺж јзҡ„д»Јз ҒпјҢ并д»Ӣз»ҚеҰӮдҪ•дҪҝз”Ё generator жқҘйҒҝе…Қж•ҲзҺҮдёҠзҡ„й—®йўҳгҖӮ
й—®йўҳ并дёҚеӨҚжқӮпјҢеҮ дёӘ for еҫӘзҺҜе°ұиғҪжҗһе®ҡпјҡ
sum = 0
for path, dirlist, filelist in os.walk(top):
for name in fnmatch.filter(filelist, "access-log*"):
# еҜ№еӯҗзӣ®еҪ•дёӯзҡ„жҜҸдёӘж—Ҙеҝ—ж–Ү件иҝӣиЎҢеӨ„зҗҶ
with open(name) as f:
for line in f:
if line[-1] == '-':
continue
else:
sum += int(line.rsplit(None, 1)[1]) |
еҲ©з”Ё os.walk иҝҷдёӘй—®йўҳи§ЈеҶіиө·жқҘеҫҲж–№дҫҝпјҢз”ұжӯӨд№ҹеҸҜд»ҘзңӢеҮә python зҡ„ for иҜӯеҸҘеҒҡйҒҚеҺҶжҳҜеӨҡд№Ҳзҡ„ж–№дҫҝпјҢдёҚйңҖиҰҒйўқеӨ–жҺ§еҲ¶еҫӘзҺҜж¬Ўж•°зҡ„еҸҳйҮҸпјҢзңҒеҺ»дәҶи®ҫзҪ®еҲқе§ӢеҖјгҖҒжӣҙж–°гҖҒеҲӨж–ӯеҫӘзҺҜз»“жқҹжқЎд»¶зӯүе·ҘдҪңпјҢзӣёжҜ” C/C++/Java иҝҷж ·зҡ„иҜӯиЁҖзңҹжҳҜеӨӘж–№дҫҝдәҶгҖӮзңӢиө·жқҘдёҖеҲҮйғҪеҫҲзҫҺеҘҪгҖӮ
然иҖҢпјҢи®ҫжғід»ҘеҗҺжңүдәҶж–°зҡ„з»ҹи®Ўд»»еҠЎпјҢжҜ”еҰӮпјҡ
1.з»ҹи®ЎжҹҗдёӘзү№е®ҡйЎөйқўзҡ„и®ҝй—®ж¬Ўж•°
2.еӨ„зҗҶеҸҰеӨ–зҡ„дёҖдәӣж—Ҙеҝ—ж–Ү件пјҢж—Ҙеҝ—ж–Ү件еҗҚеӯ—д»Ҙ error-log ејҖеӨҙ
е®ҢжҲҗиҝҷдәӣд»»еҠЎзӣҙжҺҘжӢҝдёҠйқўзҡ„д»Јз ҒиҝҮжқҘж”№ж”№е°ұеҸҜд»ҘдәҶпјҢж–Ү件еҗҚзҡ„ pattern ж”№дёҖдёӢпјҢеӨ„зҗҶжҜҸдёӘж–Ү件зҡ„д»Јз Ғж”№дёҖдёӢгҖӮе…¶е®һжҜҸж¬Ўд»»еҠЎзҡ„еӨ„зҗҶдёӯпјҢжүҫеҲ°зү№е®ҡеҗҚеӯ—дёәзү№е®ҡ pattern зҡ„ж–Ү件зҡ„д»Јз ҒжҳҜдёҖж ·зҡ„пјҢзӣҙжҺҘдҝ®ж”№д№ӢеүҚзҡ„д»Јз Ғе…¶е®һе°ұеј•е…ҘдәҶйҮҚеӨҚгҖӮ
еҰӮжһңйҮҚеӨҚзҡ„д»Јз ҒйҮҸеҫҲеӨ§пјҢжҲ‘们еҫҲиҮӘ然зҡ„дјҡжіЁж„ҸеҲ°гҖӮ然иҖҢ python зҡ„ for еҫӘзҺҜе®һеңЁеӨӘж–№дҫҝдәҶпјҢеғҸиҝҷйҮҢжүҫж–Ү件зҡ„д»Јз ҒдёҖе…ұе°ұдёӨиЎҢпјҢе“ӘжҖ•йҮҚеҶҷдёҖйҒҚд№ҹдёҚдјҡи§үеҫ—еӨӘйә»зғҰгҖӮfor еҫӘзҺҜзҡ„ж–№дҫҝдҪҝеҫ—жҲ‘们дјҡеҝҪз•Ҙиҝҷж ·з®ҖеҚ•д»Јз Ғзҡ„йҮҚеӨҚгҖӮ然иҖҢпјҢеҶҚжҖҺд№Ҳж–№дҫҝеҘҪз”ЁпјҢfor еҫӘзҺҜж— жі•йҮҚз”ЁпјҢеҸӘжңүжҠҠе®ғж”ҫеҲ°еҮҪж•°дёӯжүҚиғҪиҝӣиЎҢйҮҚз”ЁгҖӮ
(е…ҲиҖғиҷ‘дёӢжҳҜдҪ дјҡеҰӮдҪ•йҒҝе…ҚиҝҷйҮҢзҡ„д»Јз Ғзҡ„йҮҚеӨҚгҖӮдёӢйқўй©¬дёҠеҮәзҺ°зҡ„д»Јз Ғ并дёҚеҘҪпјҢжҳҜвҖңиҜҜеҜјжҖ§вҖқзҡ„д»Јз ҒпјҢжҲ‘дјҡеңЁд№ӢеҗҺеҶҚз»ҷеҮәвҖңжӣҙеҘҪвҖқзҡ„д»Јз ҒгҖӮ)
еӣ жӯӨпјҢжҲ‘们жҠҠдёҠйқўд»Јз ҒдёӯдёҚеҸҳзҡ„йғЁеҲҶжҸҗеҸ–жҲҗдёҖдёӘйҖҡз”Ёзҡ„еҮҪж•°пјҢеҸҜеҸҳзҡ„йғЁеҲҶд»ҘеҸӮж•°зҡ„еҪўејҸдј е…ҘпјҢеҫ—еҲ°дёӢйқўзҡ„д»Јз Ғпјҡ
def generic_process(topdir, filepat, processfunc):
for path, dirlist, filelist in os.walk(top):
for name in fnmatch.filter(filelist, filepat):
with open(name) f:
processfunc(f)
sum = 0
# еҫҲйҒ—жҶҫпјҢpython еҜ№ closure дёӯзҡ„еҸҳйҮҸдёҚиғҪиҝӣиЎҢиөӢеҖјж“ҚдҪңпјҢ
# еӣ жӯӨиҝҷйҮҢеҸӘиғҪдҪҝз”Ёе…ЁеұҖеҸҳйҮҸ
def add_count(f):
global sum
for line in f:
if line[-1] == '-':
continue
else:
sum += int(line.rsplit(None, 1)[1])
generic_process('logdir', 'access-log*', add_count) |
зңӢиө·жқҘдёҚеҸҳе’ҢеҸҜеҸҳзҡ„йғЁеҲҶеҲҶејҖдәҶпјҢ然иҖҢ generic_process зҡ„и®ҫ计并дёҚеҘҪгҖӮе®ғйҷӨдәҶеҜ»жүҫж–Ү件д»ҘеӨ–иҝҳи°ғз”ЁдәҶж—Ҙеҝ—ж–Ү件еӨ„зҗҶеҮҪж•°пјҢеӣ жӯӨеңЁе…¶д»–д»»еҠЎдёӯеҫҲеҸҜиғҪе°ұж— жі•дҪҝз”ЁгҖӮеҸҰеӨ– add_count зҡ„еҸӮж•°еҝ…йЎ»жҳҜ file like objectпјҢеӣ жӯӨжөӢиҜ•ж—¶дёҚиғҪз®ҖеҚ•зҡ„зӣҙжҺҘдҪҝз”Ёеӯ—з¬ҰдёІгҖӮ
з®ЎйҒ“йЈҺж јзҡ„зЁӢеәҸ
дёӢйқўиҖғиҷ‘з”Ё Unix зҡ„е·Ҙе…·е’Ңз®ЎйҒ“жҲ‘们дјҡеҰӮдҪ•е®ҢжҲҗиҝҷдёӘд»»еҠЎпјҡ
find logdir -name "access-log*" | \
xargs cat | \
grep '[^-]$' | \
awk '{ total += $NF } END { print total }' |
find ж №жҚ®ж–Ү件еҗҚ pattern жүҫеҲ°ж–Ү件пјҢcat жҠҠжүҖжңүж–Ү件еҶ…е®№еҗҲ并иҫ“еҮәеҲ° stdoutпјҢgrep д»Һ stdin иҜ»е…ҘпјҢиҝҮж»ӨжҺүиЎҢжң«дёә вҖҳ-вҖҷ зҡ„иЎҢпјҢawk жҸҗеҸ–жҜҸиЎҢ***дёҖеҲ—пјҢе°Ҷж•°еҖјзӣёеҠ пјҢ***жү“еҚ°еҮәз»“жһңгҖӮпјҲзңҒжҺү cat жҳҜеҸҜд»Ҙзҡ„пјҢдҪҶиҝҷж ·дёҖжқҘ grep е°ұйңҖиҰҒзӣҙжҺҘиҜ»ж–Ү件иҖҢдёҚжҳҜеҸӘд»Һж ҮеҮҶиҫ“е…ҘиҜ»гҖӮпјү
жҲ‘们еҸҜд»ҘеңЁ python д»Јз ҒдёӯжЁЎжӢҹиҝҷдәӣе·Ҙе…·пјҢUnix зҡ„е·Ҙе…·йҖҡиҝҮж–Үжң¬жқҘдј йҖ’з»“жһңпјҢеңЁ python дёӯеҸҜд»ҘдҪҝз”Ё listгҖӮ
def find(topdir, filepat, processfunc):
files = []
for path, dirlist, filelist in os.walk(top):
for name in fnmatch.filter(filelist, filepat):
files.append(name)
return files
def cat(files):
lines = []
for file in files:
with open(file) as f:
for line in f:
lines.append(line)
return lines
def grep(pattern, lines):
result = []
import re
pat = re.compile(pattern)
for line in lines:
if pat.search(line):
result.append(line)
resurn result
lines = grep('[^-]$', cat(find('logdir', 'access-log*')))
col = (line.rsplit(None, 1)[1] for line in lines)
print sum(int(c) for c in col) |
жңүдәҶ find, cat, grep иҝҷдёүдёӘеҮҪж•°пјҢеҸӘйңҖиҰҒиҝһз»ӯи°ғз”Ёе°ұеҸҜд»ҘеғҸ Unix зҡ„з®ЎйҒ“дёҖж ·е°ҶиҝҷдәӣеҮҪж•°з»„еҗҲиө·жқҘгҖӮж•°жҚ®еңЁз®ЎйҒ“дёӯзҡ„еҸҳеҢ–еҰӮдёӢеӣҫпјҲз®ҖжҙҒиө·и§ҒпјҢиҝҮж»ӨеҷЁзӣҙжҺҘж ҮеңЁз®ӯеӨҙдёҠ пјүпјҡ
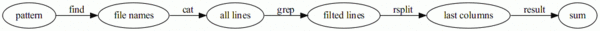
зңӢиө·жқҘзҺ°еңЁзҡ„д»Јз ҒиЎҢж•°жҜ”жңҖеҲқзӣҙжҺҘз”Ё for еҫӘзҺҜзҡ„д»Јз ҒиҰҒеӨҡпјҢдҪҶзҺ°еңЁзҡ„д»Јз Ғе°ұеғҸ Unix зҡ„йӮЈдәӣе°Ҹе·Ҙе…·дёҖж ·пјҢжҜҸдёҖдёӘйғҪжӣҙеҠ еҸҜиғҪиў«з”ЁеҲ°гҖӮжҲ‘们еҸҜд»ҘжҠҠжӣҙеӨҡеёёз”Ёзҡ„ Unix е·Ҙе…·з”Ё Python жқҘжЁЎжӢҹпјҢд»ҺиҖҢеңЁ Python д»Јз Ғдёӯд»Ҙ Unix з®ЎйҒ“зҡ„йЈҺж јжқҘзј–еҶҷд»Јз ҒгҖӮ
е…ідәҺPythonдёӯжҖҺд№Ҳзј–еҶҷUnixз®ЎйҒ“е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





