这篇文章主要介绍“Kafka生产者消息分区机制原理”,在日常操作中,相信很多人在Kafka生产者消息分区机制原理问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Kafka生产者消息分区机制原理”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
为什么分区?
Topic的概念,它是承载真实数据的逻辑容器,而在主题之下还分为若干个分区,也就是说Kafka的消息组织方式实际上是三级结构:主题-分区-消息。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。官网上的这张图非常清晰地展示了。
Kafka的三级结构,如下所示:
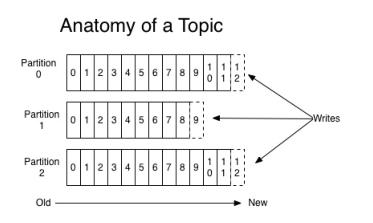
看到了这张图,我有几个问题,为什么Kafka要做这样的设计?为什么使用分区而不是直接使用多个Topic呢?
分区的作用
其实,分区的作用就是提供负载均衡的能力,或者说对数据进行分区的主要原因,就是为了实现系统的高伸缩性(Scalability)
不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处理,并且,我们还可以通过添加新的节点机器来增加整体系统的吞吐量
实际上分区的概念以及分区数据库早在1980年就已经有大牛们在做了,比如那时候有个叫Teradata的数据库就引入了分区的概念
在不同的分布式系统对分区的叫法也不尽相同:比如在Kafka中叫分区,在MongoDB和Elasticsearch中就叫分片Shard,而在HBase中则叫Region,在Cassandra中又被称作vnode
从表面看起来,它们实现原理可能不尽相同,但对底层分区(Partitioning)的整体思想却从未改变
除了提供负载均衡这种最核心的功能之外,利用分区也可以实现其他一些业务级别的需求,比如实现业务级别的消息顺序的问题
Kafka中的分区策略
Kafka中的分区策略,就是决定生产者将消息发送到哪个分区的算法
Kafka提供了默认的分区策略,同时,也支持自定义分区策略
默认分区策略
自定义分区策略
默认分区策略
轮询策略(Round-robin)
随机策略(Randomness)(已过时)
消息键策略(Key-ordering)
地理分区策略
轮询策略
也称Round-robin策略,即顺序分配
比如一个主题下有3个分区,那么第一条消息被发送到分区0,第二条被发送到分区1,第三条被发送到分区2,以此类推。当生产第4条消息时又会重新开始,即将其分配到分区0,如下图所示
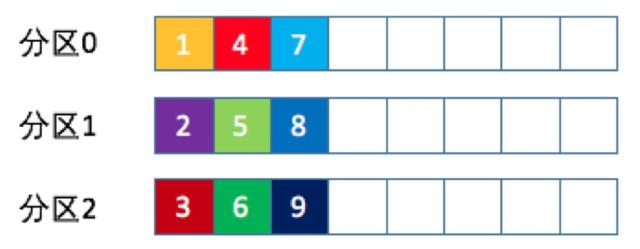
如果你未指定partitioner.class参数,那么你的生产者程序会按照轮询的方式在Topic的所有分区间均匀地“存放”消息
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一
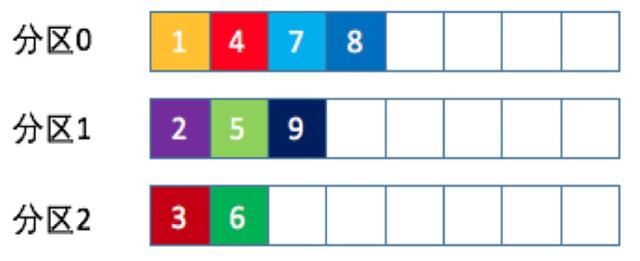
随机策略
也称Randomness策略,所谓随机就是我们随意地将消息放置到任意一个分区上,如下图所示
如果要实现随机策略版的partition方法,很简单,只需要两行代码即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); return ThreadLocalRandom.current().nextInt(partitions.size());
先计算出该Topic总的分区数,然后随机地返回一个小于它的正整数
本质上看随机策略也是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好
事实上,随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了
消息键策略
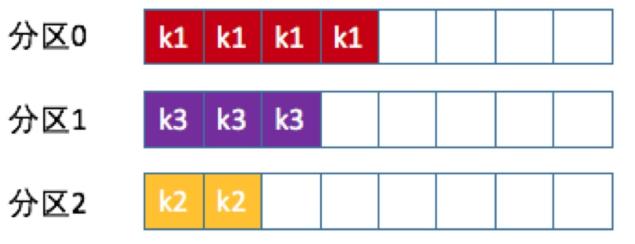
也称Key-ordering策略,Kafka允许为每条消息定义消息键,简称为Key
这个Key的作用非常大,它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务ID等;也可以用来表征消息元数据
特别是在Kafka不支持时间戳的年代,在一些场景中,工程师们都是直接将消息创建时间封装进Key里面的
一旦消息被定义了Key,那么你就可以保证同一个Key的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键策略,如下图所示
实现这个策略的partition方法同样简单,只需要下面两行代码即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); return Math.abs(key.hashCode()) % partitions.size();
先计算出该Topic总的分区数,然后计算出key的hashCode与分区数取模的绝对值
Kafka在默认分区策略的选择:如果指定了Key,那么默认实现按消息键策略;如果没有指定Key,则使用轮询策略
地理分区策略
上面这几种分区策略都是比较基础的策略,其实还有一种比较常见的,即所谓的基于地理位置的分区策略
当然这种策略一般只针对那些大规模的Kafka集群,特别是跨城市、跨国家甚至是跨大洲的集群
自定义分区策略
说完了默认分区,来说说自定义分区
Kafka中如果要自定义分区策略,你需要显式地配置生产者端的参数partitioner.class
这个参数该怎么设定呢?方法很简单,在编写生产者程序时,你可以编写一个具体的类实现org.apache.kafka.clients.producer.Partitioner接口
这个接口也很简单,只定义了两个方法:partition()和close(),通常你只需要实现最重要的partition方法,代码如下所示
/** * Compute the partition for the given record. * * @param topic The topic name * @param key The key to partition on (or null if no key) * @param keyBytes The serialized key to partition on( or null if no key) * @param value The value to partition on or null * @param valueBytes The serialized value to partition on or null * @param cluster The current cluster metadata */ public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); /** * This is called when partitioner is closed. */ public void close();
这里的topic、key、keyBytes、value和valueBytes都属于消息数据,cluster则是集群信息(比如当前Kafka集群共有多少主题、多少Broker等)
Kafka给你这么多信息,就是希望让你能够充分地利用这些信息对消息进行分区,计算出它要被发送到哪个分区中
只要你自己的实现类定义好了partition方法,同时设置partitioner.class参数为你自己实现类的Full Qualified Name,那么生产者程序就会按照你的代码逻辑对消息进行分区。
到此,关于“Kafka生产者消息分区机制原理”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





