这篇文章给大家介绍SQL优化中SQLT的使用心得是怎样的,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
一、SQLT背景介绍
SQLTXPLAIN(简称SQLT)是ORACLE COE提供的一款SQL性能诊断工具,SQLT主要方法是通过输入的一个SQL语句,从而生成一组诊断文件,这些文件用于诊断性能较差的或产生错误结果(WRONG RESULTS)的SQL。
SQLT产生的诊断文件内容包括执行计划、统计信息、CBO的参数、10053文件、性能变化的历史等需要诊断SQL性能的一系列文件,而且SQLT还提供一系列工具,比如快速绑定SQL执行计划的工具。
SQLT主要使用场合是在需要快速绑定SQL执行计划,或者一些和参数、BUG等相关的疑难SQL分析中。
二、SQLT家族简介
SQLT主要包含下列方法:
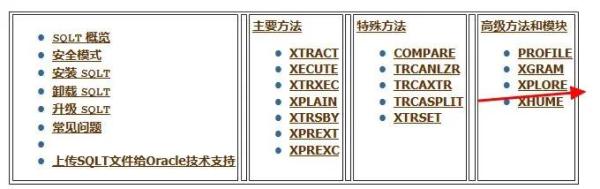
SQLT为一个SQL语句提供了下面 7种主要方法来生成诊断详细信息XTRACT,XECUTE,XTRXEC,XTRSBY,XPLAIN,XPREXT和XPREXC。XTRACT,XECUTE,XTRXEC,XTRSBY,XPREXT和XPREXC处理绑定变量和会做 bind peeking(绑定变量窥视),但是XPLAIN不会。这是因为XPLAIN是基于EXPLAIN PLAN FOR 命令执行的,该命令不做 bind peeking。
因此,如果可能请避免使用XPLAIN,除了XPLAIN的bind peeking限制外,所有这 7种主要方法都可以提供足够的诊断详细信息,对性能较差或产生错误结果集的SQL进行初步评估。如果该SQL仍位于内存中或者Automatic Workload Repository (AWR) 中,请使用XTRACT或XTRXEC,其他情况请使用XECUTE。对于Data Guard或备用只读数据库,请使用XTRSBY。仅当其他方法都不可行时,再考虑使用XPLAIN。XPREXT和XPREXC是类似于XTRACT和XECUTE,但为了提高SQLT的性能它们禁了一些SQLT的特性。
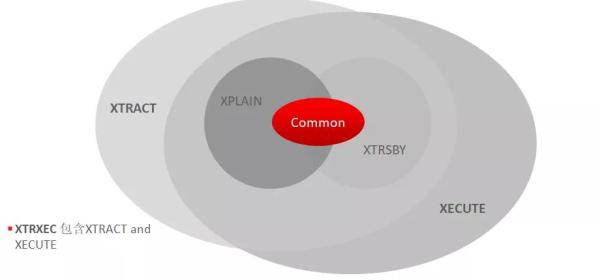
几种主要方法的关系如下:
其中XTRXEC包括了XTRACT和XECUTE方法,实际上它会同时执行这两个方法生成对应的文件。使用这些方法后,会生成文件,自动打包。
SQLT的详细内容请参考MOS文档:SQLT 使用指南 (Doc ID 1677588.1),本文重点说下SQLT里比较有用的方法(本文内容的环境是11.2.0.3)。
三、SQLT宝剑出鞘
1、SQLT生成诊断文件
生成诊断文件使用的是sqlt/run目录下的文件,此目录下还有SQLHC健康检查的脚本。这里看一个例子:
SQL text: select * from test1 where test1.status in (select test2.status from test2 where object_name like 'PRC_TEST%');
这是条简单的子查询SQL,其中test1的status有索引,而且status有倾斜分布如下:
dingjun123@ORADB> select status,count(*) 2 from test1 3 group by status; STATUS COUNT(*) ------- ---------- INVALID 6 VALID 76679 --子查询结果是INVALID dingjun123@ORADB> select test2.status from test2 2 where object_name like 'PRC_TEST%' 3 ; STATUS ------- INVALID INVALID
子查询中的语句返回的正好是INVALID,那么可以预测,此语句应该是用子查询结果驱动表test1,走test.status列的索引,正常的应该是走nested loops。OK,那么我们看看执行计划:
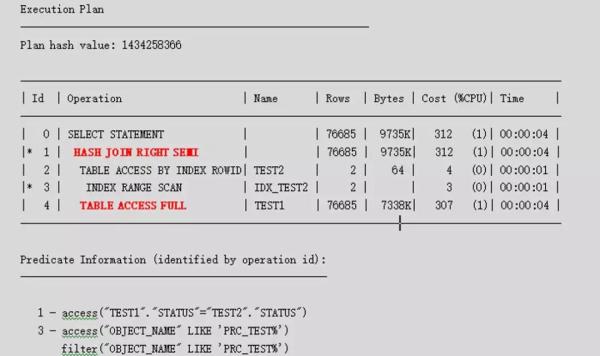
执行计划令人费解,要知道,对于表的统计信息是最新的且采样比例100%,而且也收集了STATUS列的直方图,为什么还走HASH JOIN,而且TEST1还走全表呢?先用SQLT诊断下,到sqlt/run目录下找到对应的脚本,然后输入SQLID,之后会将生成的文件打包。
dingjun123@ORADB> @sqltxtrxec PL/SQL procedure successfully completed. Elapsed: 00:00:00.00 Parameter 1: SQL_ID or HASH_VALUE of the SQL to be extracted (required) Enter value for 1: aak402j1r6zy3 Paremeter 2: SQLTXPLAIN password (required) Enter value for 2: XXXXXX PL/SQL procedure successfully completed. Elapsed: 00:00:00.00 Value passed to sqltxtrxec: SQL_ID_OR_HASH_VALUE: "aak402j1r6zy3"
解压文件,即可看到如下内容:
这里我们主要看main文件,这是主要内容以及10053等。
首先打开main文件,可以看到主要诊断内容:

可以看到,包括CBO的环境,执行计划以及历史执行信息,表,索引等对象统计信息都在这个main文件中,大部分时候可以通过此文件,了解SQL效率不佳的原因,比如执行计划变坏的时间段内正好收集了统计信息,那么可以快速定位可能是统计信息收集不正确导致的。
一般情况下,都是先看执行计划,通过Plans目录找到Execution Plans,可以点那些+,会显示对应的统计信息等内容:
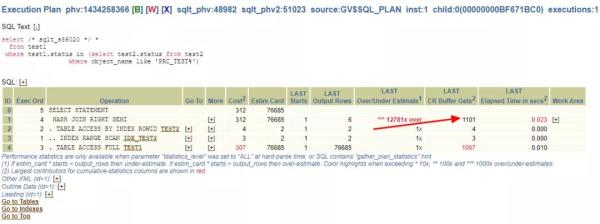
在统计信息正确的情况下,CBO估算的返回结果行是76685行,而实际结果是6行,估算是实际的12781倍,这显然是有问题的。可以点开对应的+,看看统计信息:

TEST1的STATUS列收集了直方图,而且是100%采样,没有任何问题。到此,这个简单的SQL很可能的情况就是:
CBO的缺陷,无法准确估算对应的结果集的cardinality;
CBO的BUG或参数设置原因。
针对以上两种情况,后面会介绍解决方法,这里先说下,为什么这里走了HASH JOIN,TEST1走了FULL TABLE SCAN,结果集的cardinality估算的结果正好是TEST1的行数呢,原因在于:
TEST1的STATUS有直方图;
子查询结果查询出STATUS,但是查询结果的STATUS值在没有执行之前是未知的,也就是可能是INVALID也可能是VALID。
综合以上因素,CBO无法在运行期之前预知结果的具体值,从而导致优化器缺陷,走了不佳的执行计划(12C的apative plan可以解决这个问题)。
既然知道是这个原因,那么,就采用SQL PROFILE绑定就可以了,详细内容见下节。
2、SQLT快速绑定执行计划
SQL PROFILE可以使用SQLT工具快速绑定,SQL PROFILE就是对SQL增加了一系列HINTS,好处是不需要改写SQL,可以在数据库里直接管理。
对于COE工具SQL PROFILE绑定有两类:
直接绑定:针对执行计划经常突变的,历史中有好的执行计划,当前走的执行计划差,直接绑定即可。
替换绑定:针对执行计划一直较差,没有好的执行计划作为参考,可通过添加hints让其走好的执行计划,然后通过coe工具手动修改文件或coe_load_sql_profile或者编写存储过程绑定到好的执行计划上。
注意:如果SQL没有绑定变量,则通过coe_xfr_sql_profile生成的文件需要修改force_match=>true,手动编写存储过程或者coe_load_sql_profile做替换绑定的也需要修改force_match=>true,以让所有SQL结构相同(字面量条件不同)的SQL都绑定上好的执行计划。
(对应的绑定计划的脚本在sqlt/utl目录下)
下面分别说说这两种绑定方式:
1)使用coe_xfr_sql_profile脚本直接绑定
针对SQL执行计划经常突变,当计划变差时候,快速绑定到效率高的执行计划中。如下例:运行code_xfr_sql_profile然后输入sql_id:
SQL> @coe_xfr_sql_profile.sql Parameter 1: SQL_ID (required) Enter value for 1: 0hzkb6xf08jhw PLAN_HASH_VALUE AVG_ET_SECS --------------- ----------- 3071332600 .006 --效率高的计划 40103161 653 Parameter 2: ---------------次数输入需要绑定的PLAN_HASH_VALUE,显然我们输入3071332600 PLAN_HASH_VALUE (required) Enter value for 2: 最后生成文件,执行。 注意:如果SQL没有使用绑定变量,需要将生成文件的force_match => FALSE中的FALSE改成TRUE。
2)使用coe_load_sql_profile做替换绑定
3.1中的例子是由于CBO的缺陷导致无法判定子查询结果,从而导致走错了执行计划,这里在12c之前需要绑定执行计划,因为没有现成的执行计划,所以需要自己写hints构造一条正确执行计划的SQL,然后通过SQLT的替换绑定,将正确执行计划绑定到原SQL中去。
先将原始SQL通过增加hints,让其执行计划正确,改造后的SQL如下:
select/*+ BEGIN_OUTLINE_DATA USE_NL(@"SEL$5DA710D3" "TEST1"@"SEL$1") LEADING(@"SEL$5DA710D3" "TEST2"@"SEL$2" "TEST1"@"SEL$1") INDEX_RS_ASC(@"SEL$5DA710D3" "TEST2"@"SEL$2" ("TEST2"."OBJECT_NAME")) INDEX_RS_ASC(@"SEL$5DA710D3" "TEST1"@"SEL$1" ("TEST1"."STATUS")) OUTLINE(@"SEL$2") OUTLINE(@"SEL$1") UNNEST(@"SEL$2") OUTLINE_LEAF(@"SEL$5DA710D3") ALL_ROWS DB_VERSION('11.2.0.3') OPTIMIZER_FEATURES_ENABLE('11.2.0.3') IGNORE_OPTIM_EMBEDDED_HINTS END_OUTLINE_DATA */ * from test1 where test1.status in (select test2.status from test2 where object_name like 'PRC_TEST%');然后使用coe_load_sql_profile脚本做替换绑定,输入原始的sql_id和替换的sql_id:
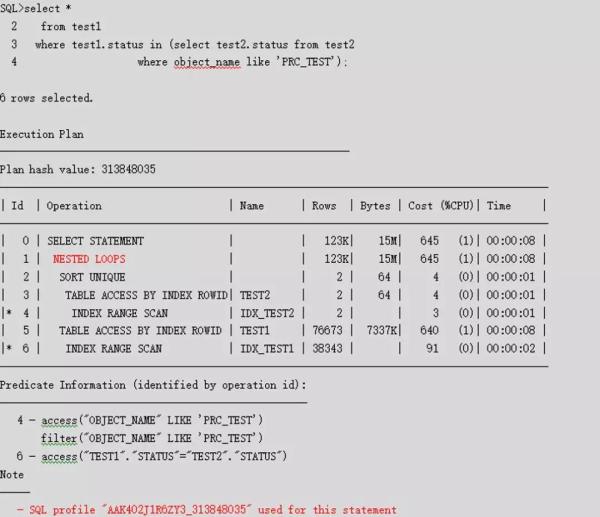
dingjun123@ORADB> @coe_load_sql_profile Parameter 1: ORIGINAL_SQL_ID (required) Enter value for 1: aak402j1r6zy3 Parameter 2: MODIFIED_SQL_ID (required) Enter value for 2: 6rbnw92d7djwk PLAN_HASH_VALUE AVG_ET_SECS -------------------- -------------------- 313848035 .001 Parameter 3: PLAN_HASH_VALUE (required) Enter value for 3: 313848035 Values passed to coe_load_sql_profile: ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ORIGINAL_SQL_ID: "aak402j1r6zy3" MODIFIED_SQL_ID: "6rbnw92d7djwk" PLAN_HASH_VALUE: "313848035" …
再次执行原始语句,可以看到,绑定执行计划成功,已经走了索引和NESTED LOOPS。
SQLT的快速绑定执行计划,在处理突发SQL性能问题中使用广泛,的确是一个非常好的工具,犹如宝剑出鞘,削铁如泥。
3、XPLORE快速诊断参数设置问题
某天晚上某系统一重要语句,迁移到新库后执行1小时都没有结果,原先很快(1s左右),业务人员焦急万分。对应的语句如下:
SELECT * FROM (SELECT A.ID, A.TEL_ID, A.PRE_CATE_ID, A.INSERT_TIME, A.REMARK1 FROM TAB_BN_TEST_LOG A, (SELECT TEL_ID, MIN(INSERT_TIME) AS INSERT_TIME FROM TAB_BN_TEST_LOG WHERE INSERT_TIME > '08-APR-19' AND ID NOT IN (SELECT IMEI FROM TX_MM_LOG_201907 WHERE TID = '10') GROUP BY TEL_ID) B WHERE A.TEL_ID = B.TEL_ID AND A.INSERT_TIME = B.INSERT_TIME AND A.ID NOT IN (SELECT IMEI FROM TX_MM_LOG_201907 WHERE TID = '10') ORDER BY INSERT_TIME) WHERE ROWNUM < 200
查看执行计划:
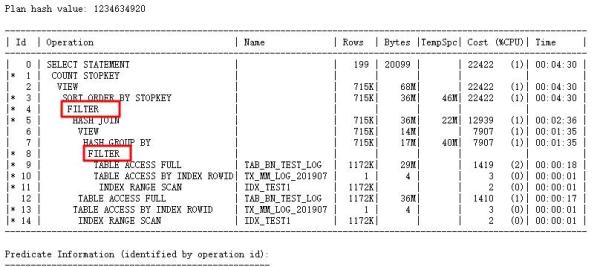
执行计划中出现FILTER,也就是子查询无法unnest,由于使用的是NOT IN,但是回头一想,这是11g,有null aware特性,应该不会出现FILTER才对,而且使用hints也无效。那么首先想到的就是检查null aware参数是否设置,经过检查:
完全没有问题,那么在收集统计信息、SQL PROFILE、可以想到的参数设置都没有问题情况下,如何解决呢?
由于查询转换受众多参数设置影响,虽然null aware已经开启,但是可能受其它参数或fix control设置影响,因此,这里可以使用SQLT的神器XPLORE分析,它会将已知参数、已知bug对应的fix control逐一重新设置一遍,然后生成对应的执行计划,最后生成一个html文件,通过查看执行计划,找到对应的参数或者BUG。
SQLT XPLORE中有XEXCUTE、XPLAIN等众多方法,对于慢的语句,建议使用XPLAIN方法。然后查看分析结果与目标计划匹配的设置,从而找出问题。
使用XPLORE,可以参考sqlt/utl/xplore中的readme.txt。这里需要将对应的SQL内容里加上:/* ^^unique_id */。
最终,生成的XPLORE文件内容如下:
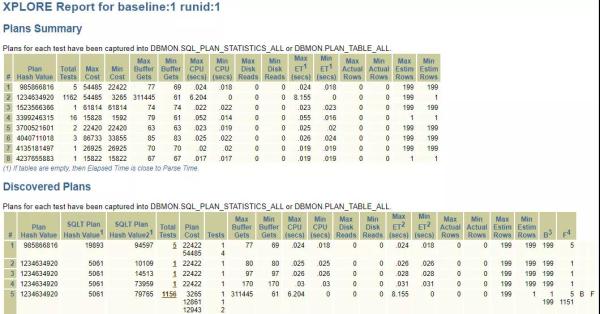
有8个执行计划的PLAN_HASH_VALUE,对应的点进去,找到正确的执行计划对应的参数设置:

最终找到,原来和_optimizer_squ_bottomup参数有关,这个参数,系统设置成FALSE,导致此子查询无法进行null aware查询转换,重新设置后语句执行恢复到正常时间。
针对这样的情况,如果一个个参数去对比分析,必然耗时很长,使用SQLT的XPLORE神器,可以快速找到对应的参数设置或已知BUG问题,比如一些新特性导致的SQL性能问题、SQL产生错误的结果等,都可以通过XPLORE分析,快速找到对应的参数,然后重新设置。
关于SQL优化中SQLT的使用心得是怎样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





