今天就跟大家聊聊有关详解Kubernetes存储体系,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
先思考一个问题,为什么会引入Volume这样一个概念?
“答案很简单,为了实现数据持久化,数据的生命周期不随着容器的消亡而消亡。
”
在没有介绍Kubernetes Volume之前,先来回顾下Docker Volume,Docker Volume常用使用方式有两种,
volumes通过这种方式,
Docker管理宿主机文件系统的一部分,默认位于
/var/lib/docker/volumes目录中,由于在创建时没有创建指定数据卷,
docker自身会创建默认数据卷;bind mounts通过这种方式,可以把容器内文件挂载到宿主机任意目录。既然有了Docker Volume,为啥Kubernetes又搞出了自己的Volume?谷歌的标新立异?
“答案是否定的,
”Kubernetes Volume和Docker Volume概念相似,但是又有不同的地方,Kubernetes Volume与Pod的生命周期相同,但与容器的生命周期不相关。当容器终止或重启时,Volume中的数据也不会丢失。当Pod被删除时,Volume才会被清理。并且数据是否丢失取决于Volume的具体类型,比如emptyDir类型的Volume数据会丢失,而持久化类型的数据则不会丢失。另外Kubernetes提供了将近20种Volume类型。
现在有了Kubernetes的Volume,我们就可以完全可以在Yaml编排文件中填写上Volume是字段,如下nfs所示:
....
volumes:
- name: static-nfs
nfs:
server: 12.18.17.240
path: /nfs/data/static
如果你使用ceph作为存储插件,你可以在编排文件中这样定义:
volumes:
- name: ceph-vol
cephfs:
monitors:
- 12.18.17.241:6789
- 12.18.17.242:6789
user: admin
secretRef:
name: ceph-secret
readOnly: true
当然只要是Kubernetes已经实现的数据卷类型,你都可以按照如上方式进行直接在Yaml编排文件中定义使用。
看到这里其实已经完成了80%的工作,那么为什么还要设计多此一举的PV呢?这个问题先搁置下,后面会有说明。
在没有说明为什么要设计多此一举的PV PVC之前,先来看看什么是PV PVC?
“”
PV是对持久化存储数据卷的一种描述。
PV通常是由运维人员提前在集群里面创建等待使用的一种数据卷。如下所示:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
nfs:
server: 10.244.1.4
path: "/nfs"
“”
PVC描述的是持久化存储的属性,比如大小、读写权限等。
PVC通常由开发人员创建,如下所示:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
而用户创建的PV PVC必须绑定完成之后才能被利用起来。而PV PVC绑定起来的前提是PV中spec中声明字段大小、权限等必须满足PVC的要求。
成功绑定之后,就可以在Pod Yaml编排文件中定义和使用。如下所示:
apiVersion: v1
kind: Pod
metadata:
labels:
role: web
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
volumeMounts:
- name: nfs
mountPath: "/usr/share/nginx/html"
volumes:
- name: nfs
persistentVolumeClaim:
claimName: nfs
看到这里,我们还会认为仅仅是PV对Volume多了一层抽象,并不见得比直接在Yaml中声明Volume高明多少。仔细思考下,我们为什么能够直接在Yaml中直接定义Volume?因为Kubernetes已经帮助我们实现了这种Volume类型,如果我们有自己的存储类型,而Kubernetes中并没有实现,这种是没有办法直接在Yaml编排文件中直接定义Volume的。这个时候PV PVC面向对象的设计就体现出其价值了。这也是在软件开发领域经常碰到的问题,开源软件无法满足要求,但也没有提供出可扩展的接口,没办法,只能重新造轮子。
我们在开发过程中经常碰到这样一个问题,在Pod中声明一个PVC之后,发现Pod不能被调度成功,原因是因为PVC没有绑定到合适的PV,这个时候要求运维人员创建一个PV,紧接着Pod调度成功。刚才上在介绍PV PVC,它们的创建过程都是手动,如果集群中需要成千上万的PV,那么运维人员岂不累死?在实际操作中,这种方式根本行不通。所以Kubernetes给我们提供了一套自动创建PV的机制Dynamic Provisioning.在没有介绍这套自动创建机制之前,先看看Static Provisioning,什么是Static Provisioning?刚才人工创建PV PVC的方式就是Static Provisioning。你可以在PV PVC编排文件中声明StorageClass,如果没有声明,那么默认为"".具体交互流程如下所示:
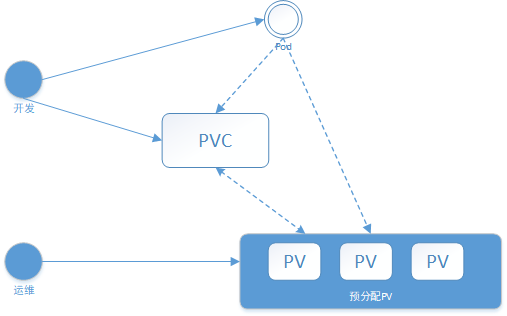
首先由集群管理员事先去规划这个集群中的用户会怎样使用存储,它会先预分配一些存储,也就是预先创建一些 PV;然后用户在提交自己的存储需求(PVC)的时候,Kubernetes内部相关组件会帮助它把PVC PV 做绑定;最后pod使用存储的时候,就可以通过PVC找到相应的PV,它就可以使用了。不足之处也非常清楚,首先繁琐,然后运维人员无法预知开发人员的真实存储需求,比如运维人员创建了多个100Gi的PV存储,但是在实际开发过程中,开发人员只能使用10Gi,这就造成了资源的浪费。当然Kubernetes也为我们提供更好的使用方式,即Dynamic Provisioning它是什么呢?
“”
Dynamic Provisioning包含了创建某种PV所需要的参数信息,类似于一个创建PV的模板。具体交互流程如下所示:
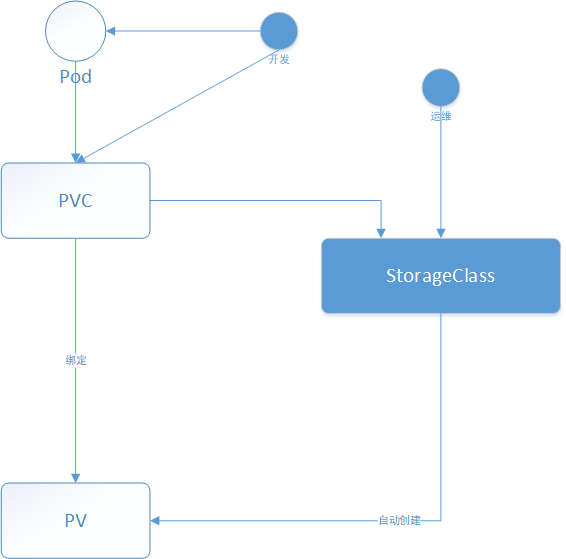
Kubernetes集群中的控制器,会结合PVC和StorageClass的信息动态生成用户所需要的PV,将PVC PV进行绑定后,pod就可以使用PV了。通过 StorageClass配置生成存储所需要的存储模板,再结合用户的需求动态创建PV对象,做到按需分配,在没有增加用户使用难度的同时也解放了集群管理员的运维工作。
Dynamic Provisioning上面提到过,运维人员不再预分配PV,而只是创建一个模板文件,这个模板文件正是StorageClass。下面以NFS为例进行说明,动态PV的整个使用过程。
#安装nfs
yum -y install nfs-utils rpcbind
#开机自启动
systemctl enable rpcbind nfs-server
#配置nfs 文件
echo "/nfs/data *(rw,no_root_squash,sync)" >/etc/exports
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["watch", "create", "update", "patch"]
- apiGroups: [""]
resources: ["services", "endpoints"]
verbs: ["get","create","list", "watch","update"]
- apiGroups: ["extensions"]
resources: ["podsecuritypolicies"]
resourceNames: ["nfs-provisioner"]
verbs: ["use"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-provisioner
subjects:
- kind: ServiceAccount
name: nfs-provisioner
namespace: logging
roleRef:
kind: ClusterRole
name: nfs-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
spec:
selector:
matchLabels:
app: nfs-client-provisioner
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccount: nfs-provisioner
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:latest
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-client
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 12.18.7.20
- name: NFS_PATH
value: /nfs/data
volumes:
- name: nfs-client
nfs:
server: 12.18.7.20
path: /nfs/data
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storage
provisioner: fuseim.pri/ifs
reclaimPolicy: Retain
这些参数是通过Kubernetes创建存储的时候,需要指定的一些细节参数。对于这些参数,用户是不需要关心的,像这里provisioner指的是使用nfs的置备程序。ReclaimPolicy就是说动态创建出来的PV,当使用方使用结束、Pod 及 PVC被删除后,这块PV应该怎么处理,我们这个地方写的是Retain,意思就是说当使用方pod PVC被删除之后,这个PV会保留。
Pod yaml文件定义
PVC,即可自动创建
PV和
PVC。apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es
spec:
........
template:
metadata:
labels:
app: elasticsearch
spec:
.........
initContainers:
........
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
.......
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: nfs-storage
resources:
requests:
storage: 50Gi`
Capacity:存储对象的大小;
AccessModes:也是用户需要关心的,就是说使用这个PV的方式。它有三种使用方式:ReadWriteOnce是单node读写访问;ReadOnlyMany是多个node只读访问,常见的一种数据共享方式;ReadWriteMany是多个node上读写访问;
StorageClassName:StorageClassName这个我们刚才说了,动态Provisioning时必须指定的一个字段,就是说我们要指定到底用哪一个模板文件来生成PV。
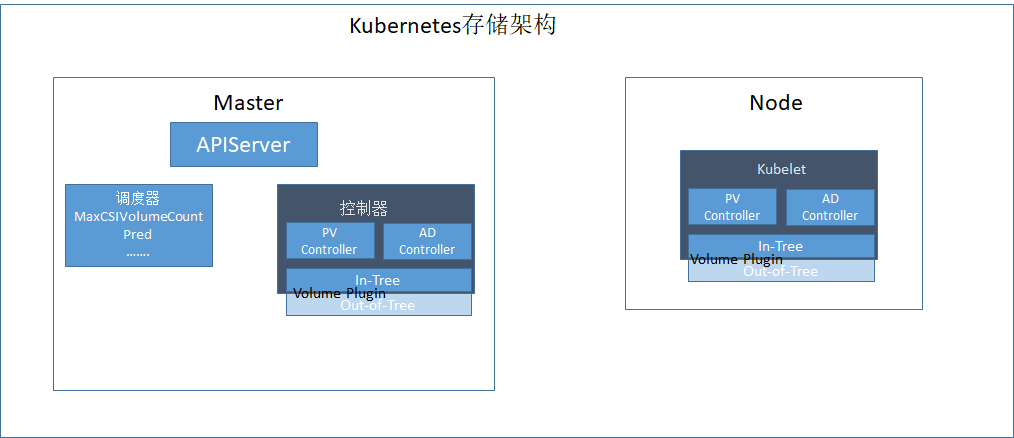
PV Controller: 负责
PV PVC的绑定、生命周期管理,并根据需求进行数据卷的
Provision Delete操作AD Controller:负责存储设备的
Attach Detach操作,将设备挂载到目标节点Volume Manager:管理卷的
Mount Unmount操作、卷设备的格式化以及挂载到一些公用目录上的操作Volume Plugins:它主要是对上面所有挂载功能的实现。
PV Controller、AD Controller、Volume Manager 主要是进行操作的调用,而具体操作则是由
Volume Plugins实现的。根据源码的位置可将
Volume Plugins分为
In-Tree和
Out-of-Tree两类:
In-Tree表示源码是放在
Kubernetes内部的(常见的
NFS、cephfs等),和
Kubernetes一起发布、管理与迭代,缺点是迭代速度慢、灵活性差;
Out-of-Tree的
Volume Plugins的代码独立于
Kubernetes,它是由存储
提供商实现的,目前主要有
Flexvolume CSI两种实现机制,可以根据存储类型实现不同的存储插件Scheduler:实现对
Pod的调度能力,会根据一些存储相关的的定义去做存储相关的调度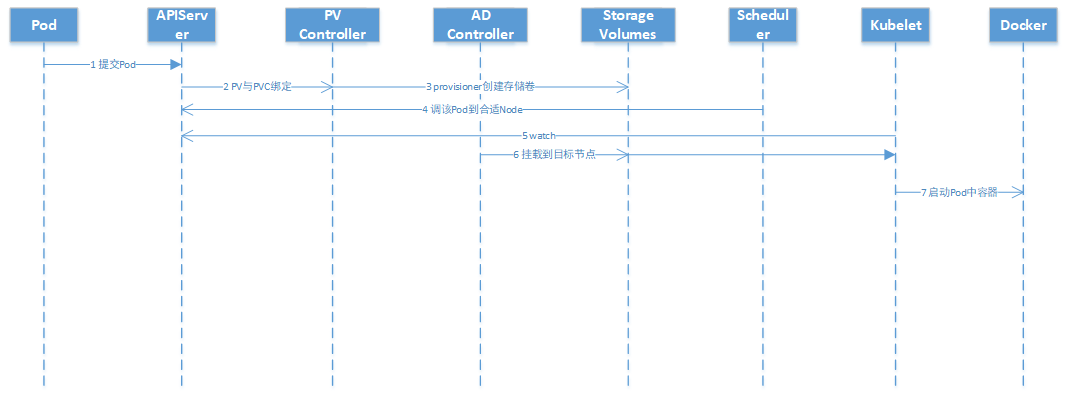
PVC的
PodPV Controller会观察
ApiServer,如果它发现一个
PVC已经创建完毕但仍然是未绑定的状态,它就会试图把一个
PV和
PVC绑定Provision就是从远端上一个具体的存储介质创建一个
Volume,并且在集群中创建一个
PV对象,然后将此
PV和
PVC进行绑定Scheduler进行多个维度考量完成后,把
Pod调度到一个合适的
NodeKubelet不断
watch APIServer是否有
Pod要调度到当前所在节点Pod调度到某个节点之后,它所定义的
PV还没有被挂载(
Attach),此时
AD Controller就会调用
VolumePlugin,把远端的
Volume挂载到目标节点中的设备上(
/dev/vdb);当
Volum Manager 发现一个
Pod调度到自己的节点上并且
Volume已经完成了挂载,它就会执行
mount操作,将本地设备(也就是刚才得到的
/dev/vdb)挂载到
Pod在节点上的一个子目录中Volume映射到容器中看完上述内容,你们对详解Kubernetes存储体系有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





