Flinkз®ҖеҚ•йЎ№зӣ®ж•ҙдҪ“жөҒзЁӢжҳҜжҖҺж ·зҡ„
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңFlinkз®ҖеҚ•йЎ№зӣ®ж•ҙдҪ“жөҒзЁӢжҳҜжҖҺж ·зҡ„вҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁFlinkз®ҖеҚ•йЎ№зӣ®ж•ҙдҪ“жөҒзЁӢжҳҜжҖҺж ·зҡ„й—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқFlinkз®ҖеҚ•йЎ№зӣ®ж•ҙдҪ“жөҒзЁӢжҳҜжҖҺж ·зҡ„вҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
йЎ№зӣ®жҰӮиҝ°
CDNзғӯй—ЁеҲҶеҸ‘зҪ‘з»ңпјҢж—Ҙеҝ—ж•°жҚ®еҲҶжһҗпјҢж—Ҙеҝ—ж•°жҚ®еҶ…е®№еҢ…жӢ¬
aliyun
CN
E
[17/Jul/2018:17:07:50 +0800]
223.104.18.110
v2.go2yd.com
17168
жҺҘе…Ҙзҡ„ж•°жҚ®зұ»еһӢе°ұжҳҜж—Ҙеҝ—
зҰ»зәҝпјҡFlume==>HDFS
е®һж—¶: Kafka==>жөҒеӨ„зҗҶеј•ж“Һ==>ES==>Kibana
ж•°жҚ®жҹҘиҜў
| жҺҘеҸЈеҗҚ | еҠҹиғҪжҸҸиҝ° |
|---|
| жұҮжҖ»з»ҹи®ЎжҹҘиҜў | еі°еҖјеёҰе®Ҫ жҖ»жөҒйҮҸ жҖ»иҜ·жұӮж•° |
йЎ№зӣ®еҠҹиғҪ
з»ҹи®ЎдёҖеҲҶй’ҹеҶ…жҜҸдёӘеҹҹеҗҚи®ҝй—®дә§з”ҹзҡ„жөҒйҮҸпјҢFlinkжҺҘ收Kafkaзҡ„ж•°жҚ®иҝӣиЎҢеӨ„зҗҶ
з»ҹи®ЎдёҖеҲҶй’ҹеҶ…жҜҸдёӘз”ЁжҲ·дә§з”ҹзҡ„жөҒйҮҸпјҢеҹҹеҗҚе’Ңз”ЁжҲ·жҳҜжңүеҜ№еә”е…ізі»зҡ„пјҢFlinkжҺҘ收Kafkaзҡ„ж•°жҚ®иҝӣиЎҢеӨ„зҗҶ+FlinkиҜ»еҸ–еҹҹеҗҚе’Ңз”ЁжҲ·зҡ„й…ҚзҪ®ж•°жҚ®(еңЁMySQLдёӯ)иҝӣиЎҢеӨ„зҗҶ
йЎ№зӣ®жһ¶жһ„
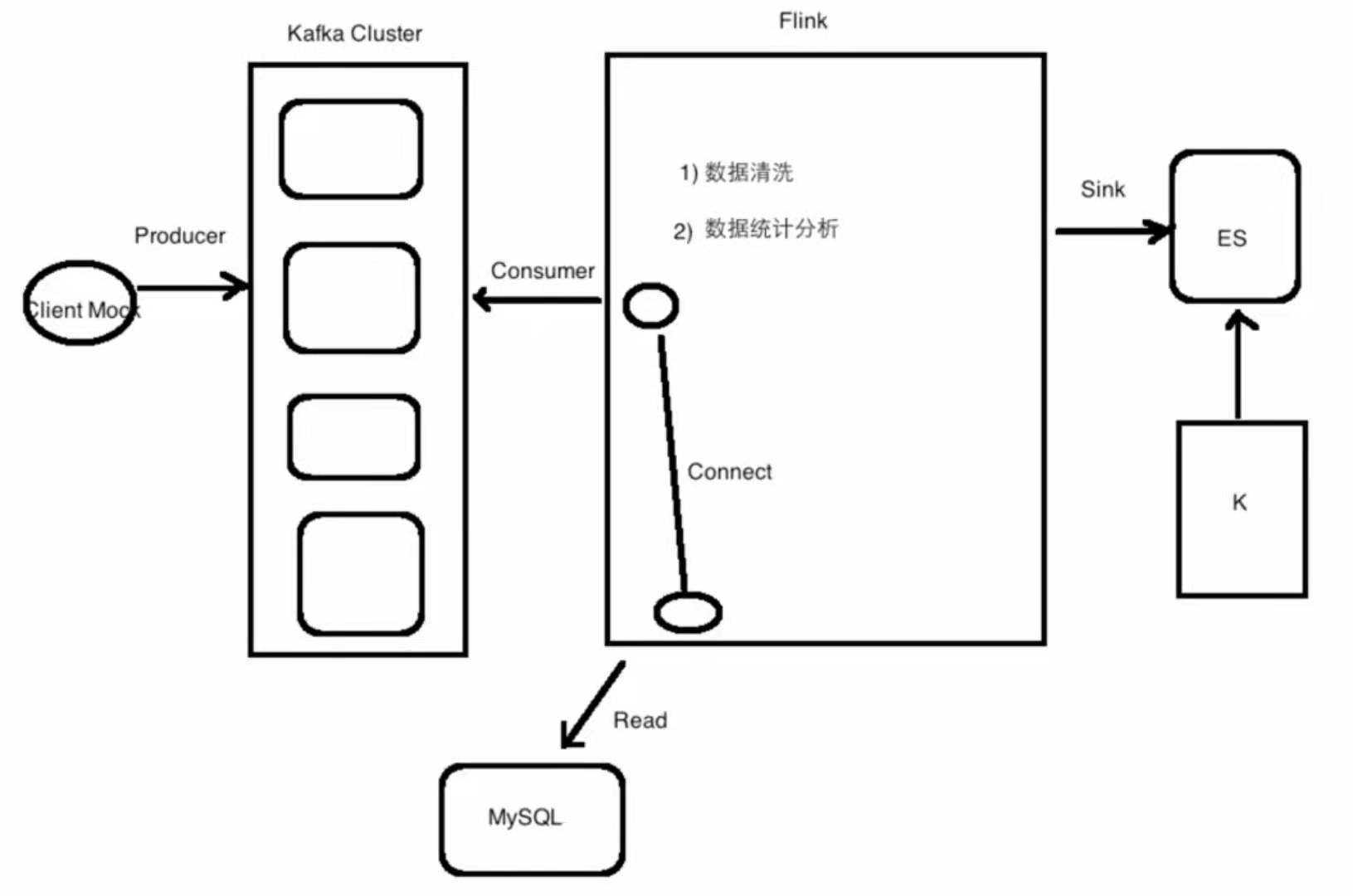
Mockж•°жҚ®
@Component@Slf4jpublic class KafkaProducer {private static final String TOPIC = "pktest"; @Autowired private KafkaTemplate<String,String> kafkaTemplate; @SuppressWarnings("unchecked")public void produce(String message) {try {
ListenableFuture future = kafkaTemplate.send(TOPIC, message); SuccessCallback<SendResult<String,String>> successCallback = new SuccessCallback<SendResult<String, String>>() {@Override public void onSuccess(@Nullable SendResult<String, String> result) {log.info("еҸ‘йҖҒж¶ҲжҒҜжҲҗеҠҹ"); }
}; FailureCallback failureCallback = new FailureCallback() {@Override public void onFailure(Throwable ex) {log.error("еҸ‘йҖҒж¶ҲжҒҜеӨұиҙҘ",ex); produce(message); }
}; future.addCallback(successCallback,failureCallback); } catch (Exception e) {log.error("еҸ‘йҖҒж¶ҲжҒҜејӮеёё",e); }
}@Scheduled(fixedRate = 1000 * 2)public void send() {
StringBuilder builder = new StringBuilder(); builder.append("aliyun").append("\t")
.append("CN").append("\t")
.append(getLevels()).append("\t")
.append(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
.format(new Date())).append("\t")
.append(getIps()).append("\t")
.append(getDomains()).append("\t")
.append(getTraffic()).append("\t"); log.info(builder.toString()); produce(builder.toString()); }/** * з”ҹдә§Levelж•°жҚ® * @return */ private String getLevels() {
List<String> levels = Arrays.asList("M","E"); return levels.get(new Random().nextInt(levels.size())); }/** * з”ҹдә§IPж•°жҚ® * @return */ private String getIps() {
List<String> ips = Arrays.asList("222.104.18.111", "223.101.75.185", "27.17.127.133", "183.225.121.16", "112.1.65.32", "175.147.222.190", "183.227.43.68", "59.88.168.87", "117.28.44.29", "117.59.34.167"); return ips.get(new Random().nextInt(ips.size())); }/** * з”ҹдә§еҹҹеҗҚж•°жҚ® * @return */ private String getDomains() {
List<String> domains = Arrays.asList("v1.go2yd.com", "v2.go2vd.com", "v3.go2yd.com", "v4.go2yd.com", "vmi.go2yd.com"); return domains.get(new Random().nextInt(domains.size())); }/** * з”ҹдә§жөҒйҮҸж•°жҚ® * @return */ private int getTraffic() {return new Random().nextInt(10000); }
}е…ідәҺSpringboot Kafkaе…¶д»–й…ҚзҪ®иҜ·еҸӮиҖғSpringboot2ж•ҙеҗҲKafka
жү“ејҖKafkaжңҚеҠЎеҷЁж¶Ҳиҙ№иҖ…пјҢеҸҜд»ҘзңӢеҲ°
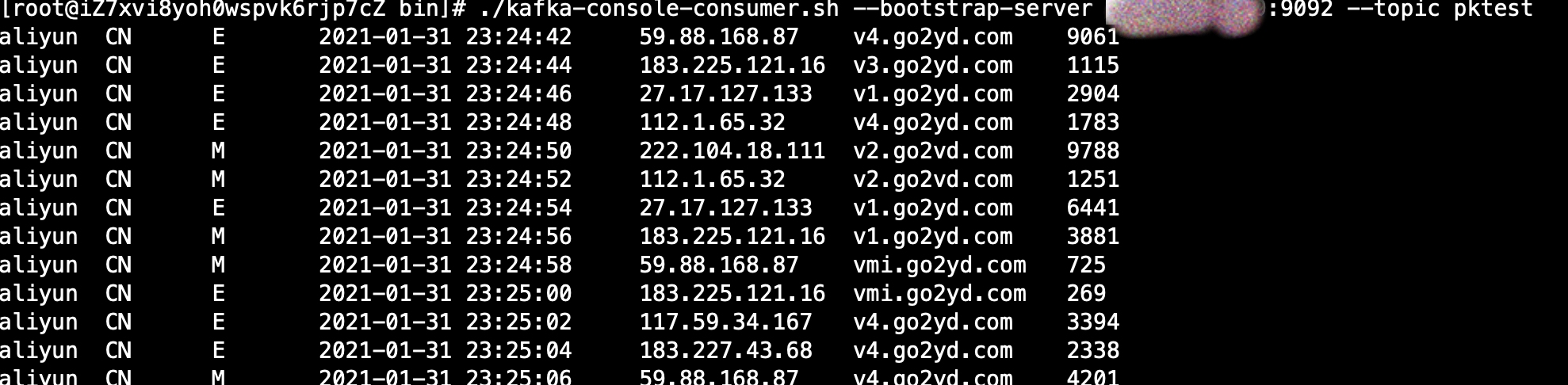
иҜҙжҳҺKafkaж•°жҚ®еҸ‘йҖҒжҲҗеҠҹ
Flinkж¶Ҳиҙ№иҖ…
public class LogAnalysis {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","еӨ–зҪ‘ip:9092"); properties.setProperty("group.id","test"); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); data.print().setParallelism(1); env.execute("LogAnalysis"); }
}жҺҘ收еҲ°зҡ„ж¶ҲжҒҜ
aliyun CN M 2021-01-31 23:43:07 222.104.18.111 v1.go2yd.com 4603
aliyun CN E 2021-01-31 23:43:09 222.104.18.111 v4.go2yd.com 6313
aliyun CN E 2021-01-31 23:43:11 222.104.18.111 v2.go2vd.com 4233
aliyun CN E 2021-01-31 23:43:13 222.104.18.111 v4.go2yd.com 2691
aliyun CN E 2021-01-31 23:43:15 183.225.121.16 v1.go2yd.com 212
aliyun CN E 2021-01-31 23:43:17 183.225.121.16 v4.go2yd.com 7744
aliyun CN M 2021-01-31 23:43:19 175.147.222.190 vmi.go2yd.com 1318
ж•°жҚ®жё…жҙ—
ж•°жҚ®жё…жҙ—е°ұжҳҜжҢүз…§жҲ‘们зҡ„дёҡеҠЎи§„еҲҷжҠҠеҺҹе§Ӣиҫ“е…Ҙзҡ„ж•°жҚ®иҝӣиЎҢдёҖе®ҡдёҡеҠЎи§„еҲҷзҡ„еӨ„зҗҶпјҢдҪҝеҫ—ж»Ўи¶іжҲ‘们дёҡеҠЎйңҖжұӮдёәеҮҶ
@Slf4jpublic class LogAnalysis {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","еӨ–зҪ‘ip:9092"); properties.setProperty("group.id","test"); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("timeиҪ¬жҚўй”ҷиҜҜ:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level,time,domain,traffic); }
}).filter(x -> (Long) x.getField(1) != 0) //жӯӨеӨ„жҲ‘们еҸӘйңҖиҰҒLevelдёәEзҡ„ж•°жҚ® .filter(x -> x.getField(0).equals("E")) //жҠӣејғlevel .map(new MapFunction<Tuple4<String,Long,String,String>, Tuple3<Long,String,Long>>() { @Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception { return new Tuple3<>(value.getField(1),value.getField(2),Long.parseLong(value.getField(3))); }
}) .print().setParallelism(1); env.execute("LogAnalysis"); }
}иҝҗиЎҢз»“жһң
(1612130315000,v1.go2yd.com,533)
(1612130319000,v4.go2yd.com,8657)
(1612130321000,vmi.go2yd.com,4353)
(1612130327000,v1.go2yd.com,9566)
(1612130329000,v2.go2vd.com,1460)
(1612130331000,vmi.go2yd.com,1444)
(1612130333000,v3.go2yd.com,6955)
(1612130337000,v1.go2yd.com,9612)
(1612130341000,vmi.go2yd.com,1732)
(1612130345000,v3.go2yd.com,694)
Scalaд»Јз Ғ
import java.text.SimpleDateFormatimport java.util.Propertiesimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.slf4j.LoggerFactoryimport org.apache.flink.api.scala._object LogAnalysis { val log = LoggerFactory.getLogger(LogAnalysis.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "еӨ–зҪ‘ip:9092")
properties.setProperty("group.id","test")val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))
data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"timeиҪ¬жҚўй”ҷиҜҜ: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))
.print().setParallelism(1)
env.execute("LogAnalysis")
}
}ж•°жҚ®еҲҶжһҗ
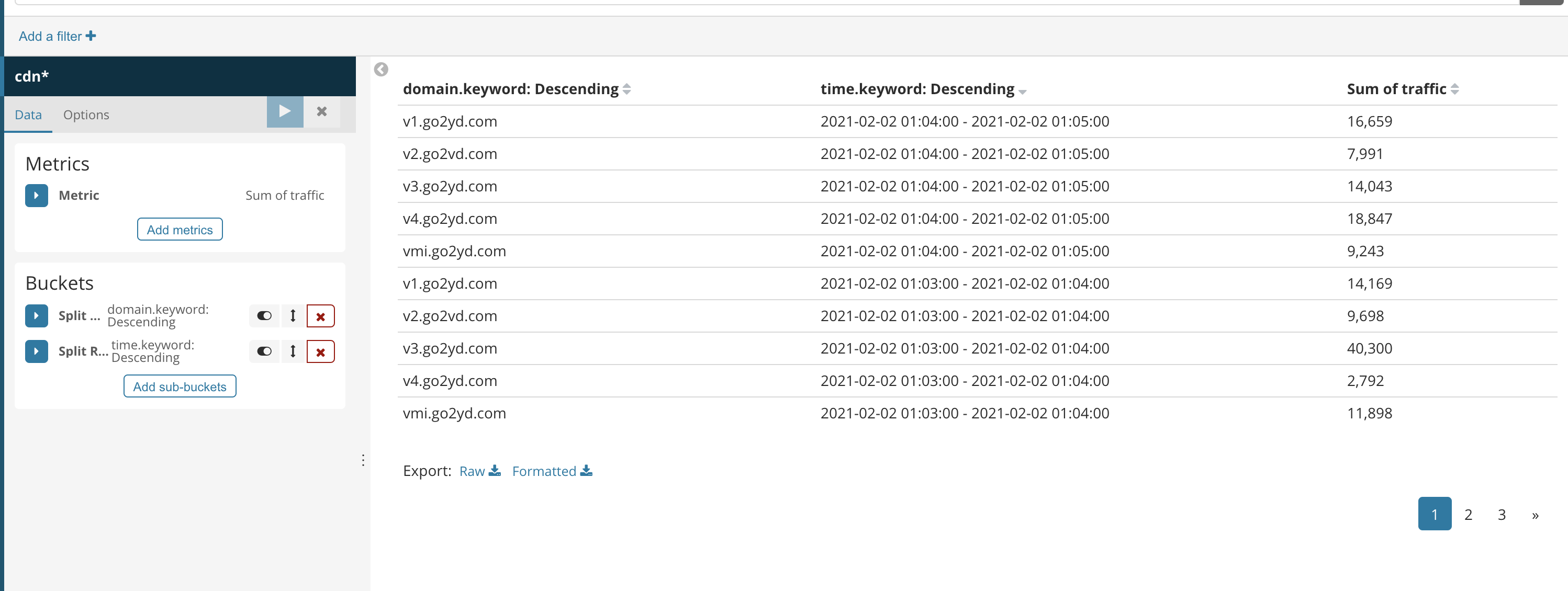
зҺ°еңЁжҲ‘们иҰҒеҲҶжһҗзҡ„жҳҜеңЁдёҖеҲҶй’ҹеҶ…зҡ„еҹҹеҗҚжөҒйҮҸ
@Slf4jpublic class LogAnalysis {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","еӨ–зҪ‘ip:9092"); properties.setProperty("group.id","test"); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("timeиҪ¬жҚўй”ҷиҜҜ:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level,time,domain,traffic); }
}).filter(x -> (Long) x.getField(1) != 0) //жӯӨеӨ„жҲ‘们еҸӘйңҖиҰҒLevelдёәEзҡ„ж•°жҚ® .filter(x -> x.getField(0).equals("E")) //жҠӣејғlevel .map(new MapFunction<Tuple4<String,Long,String,String>, Tuple3<Long,String,Long>>() { @Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception { return new Tuple3<>(value.getField(1),value.getField(2),Long.parseLong(value.getField(3))); }
})
.setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple3<Long, String, Long>>() {private Long maxOutOfOrderness = 10000L; private Long currentMaxTimestamp = 0L; @Nullable @Override public Watermark getCurrentWatermark() {return new Watermark(currentMaxTimestamp - maxOutOfOrderness); }@Override public long extractTimestamp(Tuple3<Long, String, Long> element, long previousElementTimestamp) {
Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; }
}).keyBy(x -> (String) x.getField(1))
.timeWindow(Time.minutes(1)) //иҫ“еҮәж јејҸпјҡдёҖеҲҶй’ҹзҡ„ж—¶й—ҙй—ҙйҡ”пјҢеҹҹеҗҚпјҢиҜҘеҹҹеҗҚеңЁдёҖеҲҶй’ҹеҶ…зҡ„жҖ»жөҒйҮҸ .apply(new WindowFunction<Tuple3<Long,String,Long>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple3<Long, String, Long>> input, Collector<Tuple3<String, String, Long>> out) throws Exception {
List<Tuple3<Long,String,Long>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()),s,sum)); }
})
.print().setParallelism(1); env.execute("LogAnalysis"); }
}иҝҗиЎҢз»“жһң
(2021-02-01 07:14:00 - 2021-02-01 07:15:00,vmi.go2yd.com,6307)
(2021-02-01 07:15:00 - 2021-02-01 07:16:00,v4.go2yd.com,15474)
(2021-02-01 07:15:00 - 2021-02-01 07:16:00,v2.go2vd.com,9210)
(2021-02-01 07:15:00 - 2021-02-01 07:16:00,v3.go2yd.com,190)
(2021-02-01 07:15:00 - 2021-02-01 07:16:00,v1.go2yd.com,12787)
(2021-02-01 07:15:00 - 2021-02-01 07:16:00,vmi.go2yd.com,14250)
(2021-02-01 07:16:00 - 2021-02-01 07:17:00,v4.go2yd.com,33298)
(2021-02-01 07:16:00 - 2021-02-01 07:17:00,v1.go2yd.com,37140)
Scalaд»Јз Ғ
import java.text.SimpleDateFormatimport java.util.Propertiesimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.slf4j.LoggerFactoryimport org.apache.flink.api.scala._import org.apache.flink.streaming.api.TimeCharacteristicimport org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarksimport org.apache.flink.streaming.api.scala.function.WindowFunctionimport org.apache.flink.streaming.api.watermark.Watermarkimport org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindowimport org.apache.flink.util.Collectorobject LogAnalysis { val log = LoggerFactory.getLogger(LogAnalysis.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "еӨ–зҪ‘ip:9092")
properties.setProperty("group.id","test")val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))
data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"timeиҪ¬жҚўй”ҷиҜҜ: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))
.setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(Long, String, Long)] { var maxOutOfOrderness: Long = 10000l var currentMaxTimestamp: Long = _ override def getCurrentWatermark: Watermark = {new Watermark(currentMaxTimestamp - maxOutOfOrderness)
} override def extractTimestamp(element: (Long, String, Long), previousElementTimestamp: Long): Long = {val timestamp = element._1currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp)
timestamp
}
}).keyBy(_._2)
.timeWindow(Time.minutes(1))
.apply(new WindowFunction[(Long,String,Long),(String,String,Long),String,TimeWindow] { override def apply(key: String, window: TimeWindow, input: Iterable[(Long, String, Long)], out: Collector[(String, String, Long)]): Unit = {val list = input.toListval sum = list.map(_._3).sumval format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " + format.format(window.getEnd),key,sum))
}
})
.print().setParallelism(1)
env.execute("LogAnalysis")
}
}SinkеҲ°Elasticsearch
е®үиЈ…ES
жҲ‘们иҝҷйҮҢдҪҝз”Ёзҡ„зүҲжң¬дёә6.2.4
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz
и§ЈеҺӢзј©еҗҺиҝӣе…Ҙconfigзӣ®еҪ•пјҢзј–иҫ‘elasticsearch.ymlпјҢдҝ®ж”№
network.host: 0.0.0.0
еўһеҠ дёҖдёӘйқһrootз”ЁжҲ·
useradd es
е°ҶESзӣ®еҪ•дёӢзҡ„жүҖжңүж–Ү件жӣҙж”№дёәesжүҖжңүиҖ…
chown -R es:es elasticsearch-6.2.4
дҝ®ж”№/etc/security/limits.confпјҢе°ҶжңҖдёӢж–№зҡ„еҶ…е®№ж”№дёә
es soft nofile 65536
es hard nofile 65536
дҝ®ж”№/etc/sysctl.confпјҢеўһеҠ
vm.max_map_count=655360
жү§иЎҢе‘Ҫд»Ө
sysctl -p
иҝӣе…Ҙesзҡ„binж–Ү件еӨ№пјҢ并еҲҮжҚўз”ЁжҲ·es
su es
еңЁesз”ЁжҲ·дёӢжү§иЎҢ
./elasticsearch -d
жӯӨж—¶еҸҜд»ҘеңЁWebз•ҢйқўдёӯзңӢеҲ°ESзҡ„дҝЎжҒҜ(еӨ–зҪ‘ip:9200)

з»ҷFlinkж·»еҠ ES Sink,е…Ҳж·»еҠ дҫқиө–
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-elasticsearch7_2.11</artifactId> <version>${flink.version}</version></dependency>@Slf4jpublic class LogAnalysis {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","еӨ–зҪ‘ip:9092"); properties.setProperty("group.id","test"); List<HttpHost> httpHosts = new ArrayList<>(); httpHosts.add(new HttpHost("еӨ–зҪ‘ip",9200,"http")); ElasticsearchSink.Builder<Tuple3<String,String,Long>> builder = new ElasticsearchSink.Builder<>(httpHosts, new ElasticsearchSinkFunction<Tuple3<String, String, Long>>() {@Override public void process(Tuple3<String, String, Long> value, RuntimeContext runtimeContext, RequestIndexer indexer) {
Map<String,Object> json = new HashMap<>(); json.put("time",value.getField(0)); json.put("domain",value.getField(1)); json.put("traffic",value.getField(2)); String id = value.getField(0) + "-" + value.getField(1); indexer.add(Requests.indexRequest()
.index("cdn")
.type("traffic")
.id(id)
.source(json)); }
}); //и®ҫзҪ®жү№йҮҸеҶҷж•°жҚ®зҡ„зј“еҶІеҢәеӨ§е°Ҹ builder.setBulkFlushMaxActions(1); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("timeиҪ¬жҚўй”ҷиҜҜ:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level,time,domain,traffic); }
}).filter(x -> (Long) x.getField(1) != 0) //жӯӨеӨ„жҲ‘们еҸӘйңҖиҰҒLevelдёәEзҡ„ж•°жҚ® .filter(x -> x.getField(0).equals("E")) //жҠӣејғlevel .map(new MapFunction<Tuple4<String,Long,String,String>, Tuple3<Long,String,Long>>() { @Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception { return new Tuple3<>(value.getField(1),value.getField(2),Long.parseLong(value.getField(3))); }
})
.setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple3<Long, String, Long>>() {private Long maxOutOfOrderness = 10000L; private Long currentMaxTimestamp = 0L; @Nullable @Override public Watermark getCurrentWatermark() {return new Watermark(currentMaxTimestamp - maxOutOfOrderness); }@Override public long extractTimestamp(Tuple3<Long, String, Long> element, long previousElementTimestamp) {
Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; }
}).keyBy(x -> (String) x.getField(1))
.timeWindow(Time.minutes(1)) //иҫ“еҮәж јејҸпјҡдёҖеҲҶй’ҹзҡ„ж—¶й—ҙй—ҙйҡ”пјҢеҹҹеҗҚпјҢиҜҘеҹҹеҗҚеңЁдёҖеҲҶй’ҹеҶ…зҡ„жҖ»жөҒйҮҸ .apply(new WindowFunction<Tuple3<Long,String,Long>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple3<Long, String, Long>> input, Collector<Tuple3<String, String, Long>> out) throws Exception {
List<Tuple3<Long,String,Long>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()),s,sum)); }
})
.addSink(builder.build()); env.execute("LogAnalysis"); }
}жү§иЎҢеҗҺеҸҜд»ҘеңЁESдёӯжҹҘиҜўеҲ°ж•°жҚ®
http://еӨ–зҪ‘ip:9200/cdn/traffic/_search

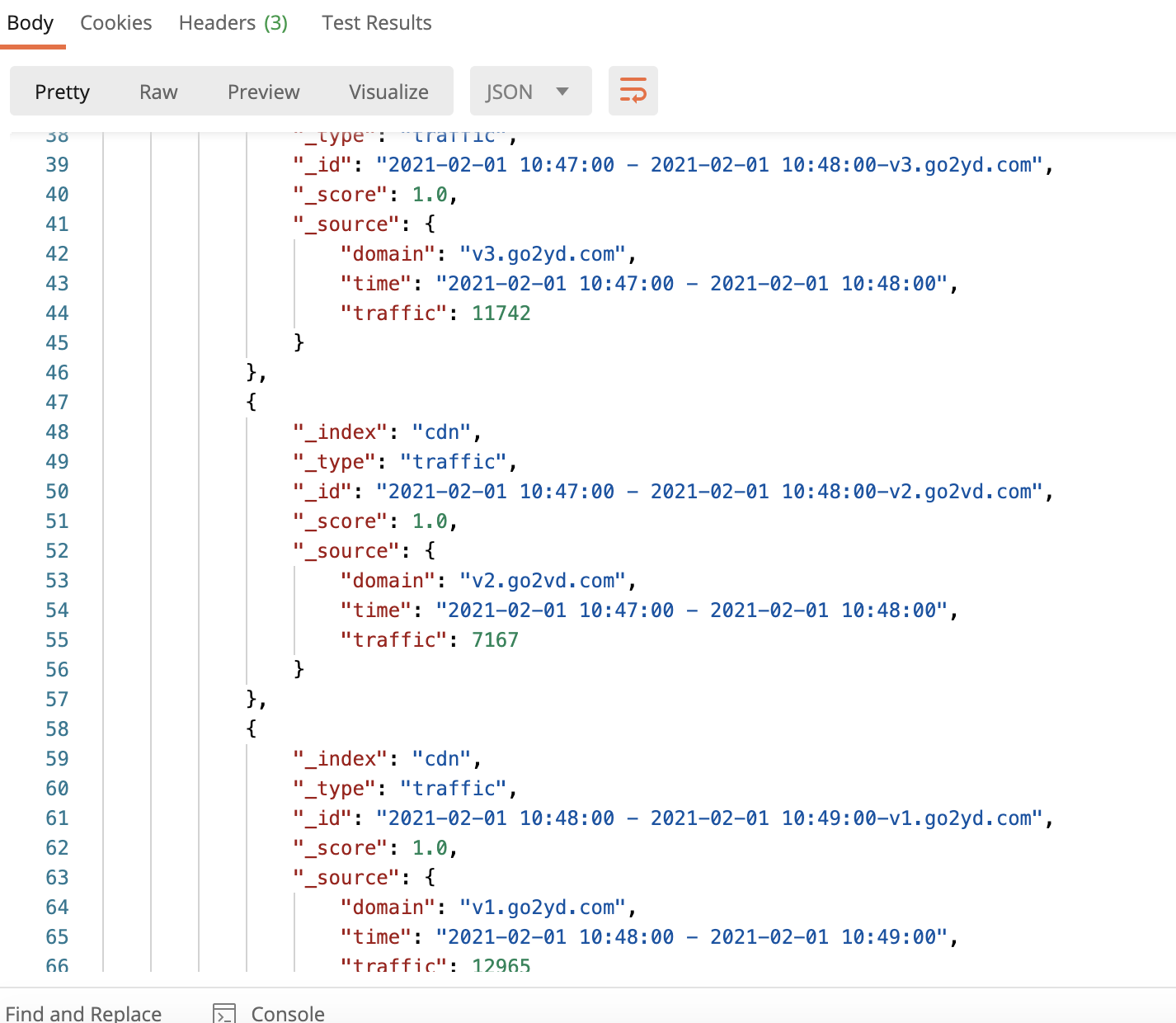
Scalaд»Јз Ғ
import java.text.SimpleDateFormatimport java.utilimport java.util.Propertiesimport org.apache.flink.api.common.functions.RuntimeContextimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.slf4j.LoggerFactoryimport org.apache.flink.api.scala._import org.apache.flink.streaming.api.TimeCharacteristicimport org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarksimport org.apache.flink.streaming.api.scala.function.WindowFunctionimport org.apache.flink.streaming.api.watermark.Watermarkimport org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindowimport org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSinkimport org.apache.flink.util.Collectorimport org.apache.http.HttpHostimport org.elasticsearch.client.Requestsobject LogAnalysis { val log = LoggerFactory.getLogger(LogAnalysis.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "еӨ–зҪ‘ip:9092")
properties.setProperty("group.id","test")val httpHosts = new util.ArrayList[HttpHost]
httpHosts.add(new HttpHost("еӨ–зҪ‘ip",9200,"http"))val builder = new ElasticsearchSink.Builder[(String,String,Long)](httpHosts,new ElasticsearchSinkFunction[(String, String, Long)] { override def process(t: (String, String, Long), runtimeContext: RuntimeContext, indexer: RequestIndexer): Unit = {val json = new util.HashMap[String,Any]
json.put("time",t._1)
json.put("domain",t._2)
json.put("traffic",t._3)val id = t._1 + "-" + t._2
indexer.add(Requests.indexRequest()
.index("cdn")
.`type`("traffic")
.id(id)
.source(json))
}
})
builder.setBulkFlushMaxActions(1)val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))
data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"timeиҪ¬жҚўй”ҷиҜҜ: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))
.setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(Long, String, Long)] { var maxOutOfOrderness: Long = 10000l var currentMaxTimestamp: Long = _ override def getCurrentWatermark: Watermark = {new Watermark(currentMaxTimestamp - maxOutOfOrderness)
} override def extractTimestamp(element: (Long, String, Long), previousElementTimestamp: Long): Long = {val timestamp = element._1currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp)
timestamp
}
}).keyBy(_._2)
.timeWindow(Time.minutes(1))
.apply(new WindowFunction[(Long,String,Long),(String,String,Long),String,TimeWindow] { override def apply(key: String, window: TimeWindow, input: Iterable[(Long, String, Long)], out: Collector[(String, String, Long)]): Unit = {val list = input.toListval sum = list.map(_._3).sumval format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " + format.format(window.getEnd),key,sum))
}
})
.addSink(builder.build)
env.execute("LogAnalysis")
}
}KibanaеӣҫеҪўеұ•зӨә
е®үиЈ…kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz
kibanaиҰҒи·ҹESдҝқжҢҒзүҲжң¬зӣёеҗҢпјҢи§ЈеҺӢзј©еҗҺиҝӣе…Ҙconfigзӣ®еҪ•пјҢзј–иҫ‘kibana.yml
server.host: "host2"
elasticsearch.url: "http://host2:9200"
иҝҷйҮҢйқўзҡ„еҶ…е®№дјҡж №жҚ®зүҲжң¬дёҚеҗҢдјҡжңүдёҖдәӣдёҚеҗҢпјҢдҝқеӯҳеҗҺпјҢиҝӣе…Ҙbinзӣ®еҪ•
еҲҮжҚўesз”ЁжҲ·пјҢжү§иЎҢ
./kibana &
и®ҝй—®WebйЎөйқўпјҢеӨ–зҪ‘ip:5601
иҝҷйҮҢжҲ‘еҒҡдәҶдёҖдёӘиЎЁпјҢдёҖдёӘжҹұзҠ¶еӣҫ
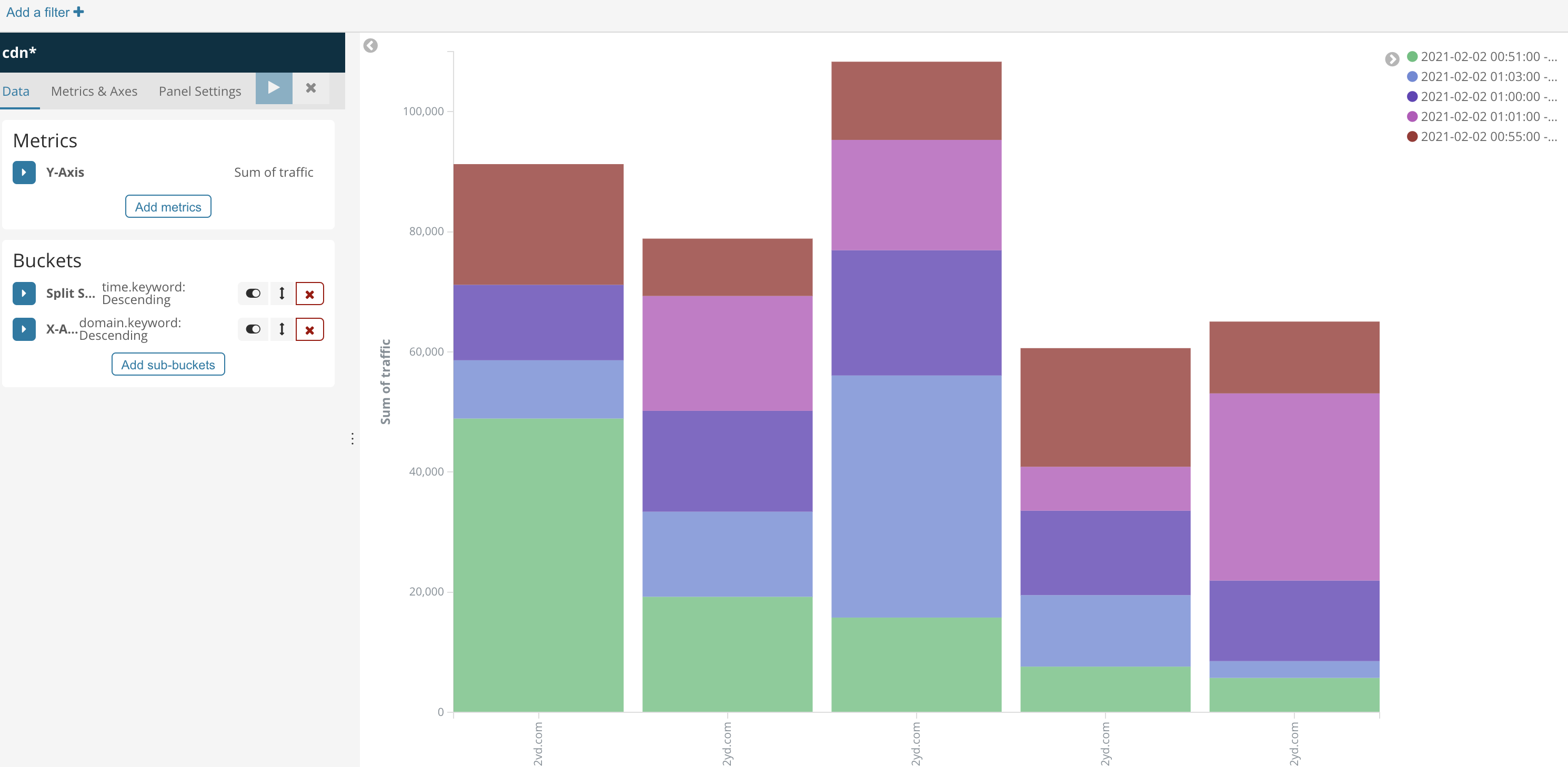
第дәҢдёӘйңҖжұӮпјҢз»ҹи®ЎдёҖеҲҶй’ҹеҶ…жҜҸдёӘз”ЁжҲ·дә§з”ҹзҡ„жөҒйҮҸ
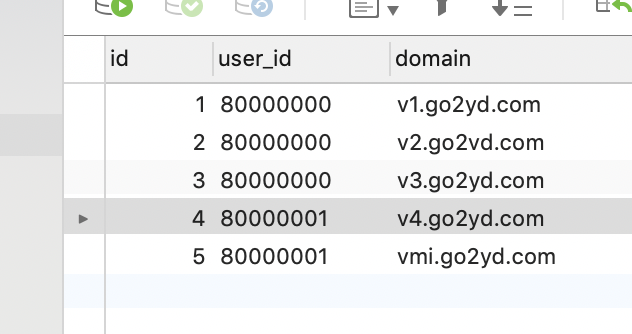
еңЁMySQLж•°жҚ®еә“дёӯж–°еўһдёҖеј иЎЁuser_domain_config,еӯ—ж®өеҰӮдёӢ

иЎЁдёӯеҶ…е®№еҰӮдёӢ
ж•°жҚ®жё…жҙ—
/** * иҮӘе®ҡд№үMySQLж•°жҚ®жәҗ */public class MySQLSource extends RichParallelSourceFunction<Tuple2<String,String>> {private Connection connection; private PreparedStatement pstmt; private Connection getConnection() {
Connection conn = null; try {
Class.forName("com.mysql.cj.jdbc.Driver"); String url = "jdbc:mysql://еӨ–зҪ‘ip:3306/flink"; conn = DriverManager.getConnection(url,"root","******"); }catch (Exception e) {
e.printStackTrace(); }return conn; }@Override public void open(Configuration parameters) throws Exception {super.open(parameters); connection = getConnection(); String sql = "select user_id,domain from user_domain_config"; pstmt = connection.prepareStatement(sql); }@Override @SuppressWarnings("unchecked")public void run(SourceContext<Tuple2<String,String>> ctx) throws Exception {
ResultSet rs = pstmt.executeQuery(); while (rs.next()) {
Tuple2 tuple2 = new Tuple2(rs.getString("domain"),rs.getString("user_id")); ctx.collect(tuple2); }pstmt.close(); }@Override public void cancel() {
}@Override public void close() throws Exception {super.close(); if (pstmt != null) {pstmt.close(); }if (connection != null) {connection.close(); }
}
}@Slf4jpublic class LogAnalysisWithMySQL {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","еӨ–зҪ‘ip:9092"); properties.setProperty("group.id","test"); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); SingleOutputStreamOperator<Tuple3<Long, String, Long>> logData = data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("timeиҪ¬жҚўй”ҷиҜҜ:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level, time, domain, traffic); }
}).filter(x -> (Long) x.getField(1) != 0)//жӯӨеӨ„жҲ‘们еҸӘйңҖиҰҒLevelдёәEзҡ„ж•°жҚ® .filter(x -> x.getField(0).equals("E"))//жҠӣејғlevel .map(new MapFunction<Tuple4<String, Long, String, String>, Tuple3<Long, String, Long>>() {@Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception {return new Tuple3<>(value.getField(1), value.getField(2), Long.parseLong(value.getField(3))); }
}); DataStreamSource<Tuple2<String, String>> mysqlData = env.addSource(new MySQLSource()); //еҸҢжөҒжұҮиҒҡ logData.connect(mysqlData).flatMap(new CoFlatMapFunction<Tuple3<Long,String,Long>, Tuple2<String,String>, Tuple4<Long,String,Long,String>>() {private Map<String,String> userDomainMap = new HashMap<>(); @Override public void flatMap1(Tuple3<Long, String, Long> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {
String domain = value.getField(1); String userId = userDomainMap.getOrDefault(domain,""); out.collect(new Tuple4<>(value.getField(0),value.getField(1),value.getField(2),userId)); }@Override public void flatMap2(Tuple2<String, String> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {userDomainMap.put(value.getField(0),value.getField(1)); }
}).print().setParallelism(1); env.execute("LogAnalysisWithMySQL"); }
}иҝҗиЎҢз»“жһң
(1612239325000,vmi.go2yd.com,7115,80000001)
(1612239633000,v4.go2yd.com,8412,80000001)
(1612239635000,v3.go2yd.com,3527,80000000)
(1612239639000,v1.go2yd.com,7385,80000000)
(1612239643000,vmi.go2yd.com,8650,80000001)
(1612239645000,vmi.go2yd.com,2642,80000001)
(1612239647000,vmi.go2yd.com,1525,80000001)
(1612239649000,v2.go2vd.com,8832,80000000)
Scalaд»Јз Ғ
import java.sql.{Connection, DriverManager, PreparedStatement}import org.apache.flink.configuration.Configurationimport org.apache.flink.streaming.api.functions.source.{RichParallelSourceFunction, SourceFunction}class MySQLSource extends RichParallelSourceFunction[(String,String)]{ var connection: Connection = null var pstmt: PreparedStatement = null def getConnection:Connection = {var conn: Connection = null Class.forName("com.mysql.cj.jdbc.Driver")val url = "jdbc:mysql://еӨ–зҪ‘ip:3306/flink" conn = DriverManager.getConnection(url, "root", "******")
conn
} override def open(parameters: Configuration): Unit = {connection = getConnectionval sql = "select user_id,domain from user_domain_config" pstmt = connection.prepareStatement(sql)
} override def cancel() = {} override def run(ctx: SourceFunction.SourceContext[(String, String)]) = {val rs = pstmt.executeQuery()while (rs.next) { val tuple2 = (rs.getString("domain"),rs.getString("user_id"))
ctx.collect(tuple2)
}pstmt.close()
} override def close(): Unit = {if (pstmt != null) { pstmt.close()
}if (connection != null) { connection.close()
}
}
}import java.text.SimpleDateFormatimport java.util.Propertiesimport com.guanjian.flink.scala.until.MySQLSourceimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.api.scala._import org.apache.flink.streaming.api.functions.co.CoFlatMapFunctionimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.apache.flink.util.Collectorimport org.slf4j.LoggerFactoryimport scala.collection.mutableobject LogAnalysisWithMySQL { val log = LoggerFactory.getLogger(LogAnalysisWithMySQL.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "еӨ–зҪ‘ip:9092")
properties.setProperty("group.id","test")val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))val logData = data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"timeиҪ¬жҚўй”ҷиҜҜ: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))val mysqlData = env.addSource(new MySQLSource)
logData.connect(mysqlData).flatMap(new CoFlatMapFunction[(Long,String,Long),(String,String),(Long,String,Long,String)] { var userDomainMap = mutable.HashMap[String,String]() override def flatMap1(value: (Long, String, Long), out: Collector[(Long, String, Long, String)]) = {val domain = value._2val userId = userDomainMap.getOrElse(domain,"")
out.collect((value._1,value._2,value._3,userId))
} override def flatMap2(value: (String, String), out: Collector[(Long, String, Long, String)]) = {userDomainMap += value._1 -> value._2
}
}).print().setParallelism(1)
env.execute("LogAnalysisWithMySQL")
}
}ж•°жҚ®еҲҶжһҗ
@Slf4jpublic class LogAnalysisWithMySQL {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","еӨ–зҪ‘ip:9092"); properties.setProperty("group.id","test"); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); SingleOutputStreamOperator<Tuple3<Long, String, Long>> logData = data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("timeиҪ¬жҚўй”ҷиҜҜ:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level, time, domain, traffic); }
}).filter(x -> (Long) x.getField(1) != 0)//жӯӨеӨ„жҲ‘们еҸӘйңҖиҰҒLevelдёәEзҡ„ж•°жҚ® .filter(x -> x.getField(0).equals("E"))//жҠӣејғlevel .map(new MapFunction<Tuple4<String, Long, String, String>, Tuple3<Long, String, Long>>() {@Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception {return new Tuple3<>(value.getField(1), value.getField(2), Long.parseLong(value.getField(3))); }
}); DataStreamSource<Tuple2<String, String>> mysqlData = env.addSource(new MySQLSource()); //еҸҢжөҒжұҮиҒҡ logData.connect(mysqlData).flatMap(new CoFlatMapFunction<Tuple3<Long,String,Long>, Tuple2<String,String>, Tuple4<Long,String,Long,String>>() {private Map<String,String> userDomainMap = new HashMap<>(); @Override public void flatMap1(Tuple3<Long, String, Long> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {
String domain = value.getField(1); String userId = userDomainMap.getOrDefault(domain,""); out.collect(new Tuple4<>(value.getField(0),value.getField(1),value.getField(2),userId)); }@Override public void flatMap2(Tuple2<String, String> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {userDomainMap.put(value.getField(0),value.getField(1)); }
}).setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple4<Long, String, Long,String>>() {private Long maxOutOfOrderness = 10000L; private Long currentMaxTimestamp = 0L; @Nullable @Override public Watermark getCurrentWatermark() {return new Watermark(currentMaxTimestamp - maxOutOfOrderness); }@Override public long extractTimestamp(Tuple4<Long, String, Long,String> element, long previousElementTimestamp) {
Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; }
}).keyBy(x -> (String) x.getField(3))
.timeWindow(Time.minutes(1)) //иҫ“еҮәж јејҸпјҡдёҖеҲҶй’ҹзҡ„ж—¶й—ҙй—ҙйҡ”пјҢз”ЁжҲ·пјҢиҜҘз”ЁжҲ·еңЁдёҖеҲҶй’ҹеҶ…зҡ„жҖ»жөҒйҮҸ .apply(new WindowFunction<Tuple4<Long,String,Long,String>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple4<Long, String, Long, String>> input, Collector<Tuple3<String, String, Long>> out) throws Exception {
List<Tuple4<Long, String, Long,String>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()), s, sum)); }
}).print().setParallelism(1); env.execute("LogAnalysisWithMySQL"); }
}иҝҗиЎҢз»“жһң
(2021-02-02 13:58:00 - 2021-02-02 13:59:00,80000000,20933)
(2021-02-02 13:58:00 - 2021-02-02 13:59:00,80000001,6928)
(2021-02-02 13:59:00 - 2021-02-02 14:00:00,80000001,38202)
(2021-02-02 13:59:00 - 2021-02-02 14:00:00,80000000,39394)
(2021-02-02 14:00:00 - 2021-02-02 14:01:00,80000001,23070)
(2021-02-02 14:00:00 - 2021-02-02 14:01:00,80000000,41701)
Scalaд»Јз Ғ
import java.text.SimpleDateFormatimport java.util.Propertiesimport com.guanjian.flink.scala.until.MySQLSourceimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.api.scala._import org.apache.flink.streaming.api.TimeCharacteristicimport org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarksimport org.apache.flink.streaming.api.functions.co.CoFlatMapFunctionimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.api.scala.function.WindowFunctionimport org.apache.flink.streaming.api.watermark.Watermarkimport org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindowimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.apache.flink.util.Collectorimport org.slf4j.LoggerFactoryimport scala.collection.mutableobject LogAnalysisWithMySQL { val log = LoggerFactory.getLogger(LogAnalysisWithMySQL.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "еӨ–зҪ‘ip:9092")
properties.setProperty("group.id","test")val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))val logData = data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"timeиҪ¬жҚўй”ҷиҜҜ: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))val mysqlData = env.addSource(new MySQLSource)
logData.connect(mysqlData).flatMap(new CoFlatMapFunction[(Long,String,Long),(String,String),(Long,String,Long,String)] { var userDomainMap = mutable.HashMap[String,String]() override def flatMap1(value: (Long, String, Long), out: Collector[(Long, String, Long, String)]) = {val domain = value._2val userId = userDomainMap.getOrElse(domain,"")
out.collect((value._1,value._2,value._3,userId))
} override def flatMap2(value: (String, String), out: Collector[(Long, String, Long, String)]) = {userDomainMap += value._1 -> value._2
}
}).setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(Long, String, Long, String)] { var maxOutOfOrderness: Long = 10000l var currentMaxTimestamp: Long = _ override def getCurrentWatermark: Watermark = {new Watermark(currentMaxTimestamp - maxOutOfOrderness)
} override def extractTimestamp(element: (Long, String, Long, String), previousElementTimestamp: Long): Long = {val timestamp = element._1currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp)
timestamp
}
}).keyBy(_._4)
.timeWindow(Time.minutes(1))
.apply(new WindowFunction[(Long,String,Long,String),(String,String,Long),String,TimeWindow] {override def apply(key: String, window: TimeWindow, input: Iterable[(Long, String, Long, String)], out: Collector[(String, String, Long)]): Unit = { val list = input.toList val sum = list.map(_._3).sum val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " + format.format(window.getEnd),key,sum))
}
}).print().setParallelism(1)
env.execute("LogAnalysisWithMySQL")
}
}SinkеҲ°ES
@Slf4jpublic class LogAnalysisWithMySQL {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","еӨ–зҪ‘ip:9092"); properties.setProperty("group.id","test"); List<HttpHost> httpHosts = new ArrayList<>(); httpHosts.add(new HttpHost("еӨ–зҪ‘ip",9200,"http")); ElasticsearchSink.Builder<Tuple3<String,String,Long>> builder = new ElasticsearchSink.Builder<>(httpHosts, new ElasticsearchSinkFunction<Tuple3<String, String, Long>>() {@Override public void process(Tuple3<String, String, Long> value, RuntimeContext runtimeContext, RequestIndexer indexer) {
Map<String,Object> json = new HashMap<>(); json.put("time",value.getField(0)); json.put("userId",value.getField(1)); json.put("traffic",value.getField(2)); String id = value.getField(0) + "-" + value.getField(1); indexer.add(Requests.indexRequest()
.index("user")
.type("traffic")
.id(id)
.source(json)); }
}); //и®ҫзҪ®жү№йҮҸеҶҷж•°жҚ®зҡ„зј“еҶІеҢәеӨ§е°Ҹ builder.setBulkFlushMaxActions(1); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); SingleOutputStreamOperator<Tuple3<Long, String, Long>> logData = data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("timeиҪ¬жҚўй”ҷиҜҜ:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level, time, domain, traffic); }
}).filter(x -> (Long) x.getField(1) != 0)//жӯӨеӨ„жҲ‘们еҸӘйңҖиҰҒLevelдёәEзҡ„ж•°жҚ® .filter(x -> x.getField(0).equals("E"))//жҠӣејғlevel .map(new MapFunction<Tuple4<String, Long, String, String>, Tuple3<Long, String, Long>>() {@Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception {return new Tuple3<>(value.getField(1), value.getField(2), Long.parseLong(value.getField(3))); }
}); DataStreamSource<Tuple2<String, String>> mysqlData = env.addSource(new MySQLSource()); //еҸҢжөҒжұҮиҒҡ logData.connect(mysqlData).flatMap(new CoFlatMapFunction<Tuple3<Long,String,Long>, Tuple2<String,String>, Tuple4<Long,String,Long,String>>() {private Map<String,String> userDomainMap = new HashMap<>(); @Override public void flatMap1(Tuple3<Long, String, Long> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {
String domain = value.getField(1); String userId = userDomainMap.getOrDefault(domain,""); out.collect(new Tuple4<>(value.getField(0),value.getField(1),value.getField(2),userId)); }@Override public void flatMap2(Tuple2<String, String> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {userDomainMap.put(value.getField(0),value.getField(1)); }
}).setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple4<Long, String, Long,String>>() {private Long maxOutOfOrderness = 10000L; private Long currentMaxTimestamp = 0L; @Nullable @Override public Watermark getCurrentWatermark() {return new Watermark(currentMaxTimestamp - maxOutOfOrderness); }@Override public long extractTimestamp(Tuple4<Long, String, Long,String> element, long previousElementTimestamp) {
Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; }
}).keyBy(x -> (String) x.getField(3))
.timeWindow(Time.minutes(1)) //иҫ“еҮәж јејҸпјҡдёҖеҲҶй’ҹзҡ„ж—¶й—ҙй—ҙйҡ”пјҢз”ЁжҲ·пјҢиҜҘз”ЁжҲ·еңЁдёҖеҲҶй’ҹеҶ…зҡ„жҖ»жөҒйҮҸ .apply(new WindowFunction<Tuple4<Long,String,Long,String>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple4<Long, String, Long, String>> input, Collector<Tuple3<String, String, Long>> out) throws Exception {
List<Tuple4<Long, String, Long,String>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()), s, sum)); }
}).addSink(builder.build()); env.execute("LogAnalysisWithMySQL"); }
}иҝҗиЎҢз»“жһң
и®ҝй—®http://еӨ–зҪ‘ip:9200/user/traffic/_search
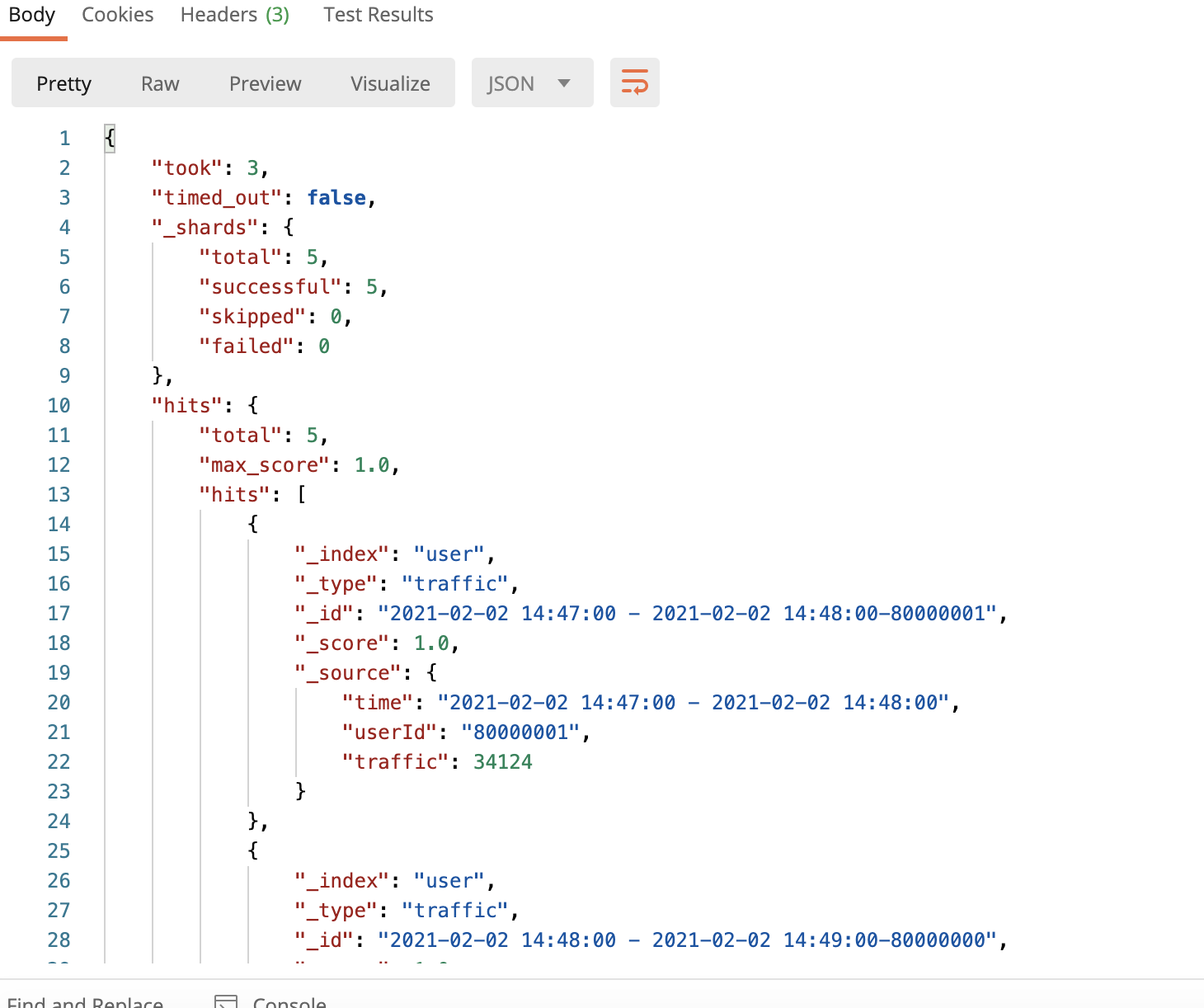

Scalaд»Јз Ғ
port java.text.SimpleDateFormatimport java.utilimport java.util.Propertiesimport com.guanjian.flink.scala.until.MySQLSourceimport org.apache.flink.api.common.functions.RuntimeContextimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.api.scala._import org.apache.flink.streaming.api.TimeCharacteristicimport org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarksimport org.apache.flink.streaming.api.functions.co.CoFlatMapFunctionimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.api.scala.function.WindowFunctionimport org.apache.flink.streaming.api.watermark.Watermarkimport org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindowimport org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSinkimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.apache.flink.util.Collectorimport org.apache.http.HttpHostimport org.elasticsearch.client.Requestsimport org.slf4j.LoggerFactoryimport scala.collection.mutableobject LogAnalysisWithMySQL { val log = LoggerFactory.getLogger(LogAnalysisWithMySQL.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "еӨ–зҪ‘ip:9092")
properties.setProperty("group.id","test")val httpHosts = new util.ArrayList[HttpHost]
httpHosts.add(new HttpHost("еӨ–зҪ‘ip",9200,"http"))val builder = new ElasticsearchSink.Builder[(String,String,Long)](httpHosts,new ElasticsearchSinkFunction[(String, String, Long)] { override def process(t: (String, String, Long), runtimeContext: RuntimeContext, indexer: RequestIndexer): Unit = {val json = new util.HashMap[String,Any]
json.put("time",t._1)
json.put("userId",t._2)
json.put("traffic",t._3)val id = t._1 + "-" + t._2
indexer.add(Requests.indexRequest()
.index("user")
.`type`("traffic")
.id(id)
.source(json))
}
})
builder.setBulkFlushMaxActions(1)val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))val logData = data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"timeиҪ¬жҚўй”ҷиҜҜ: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))val mysqlData = env.addSource(new MySQLSource)
logData.connect(mysqlData).flatMap(new CoFlatMapFunction[(Long,String,Long),(String,String),(Long,String,Long,String)] { var userDomainMap = mutable.HashMap[String,String]() override def flatMap1(value: (Long, String, Long), out: Collector[(Long, String, Long, String)]) = {val domain = value._2val userId = userDomainMap.getOrElse(domain,"")
out.collect((value._1,value._2,value._3,userId))
} override def flatMap2(value: (String, String), out: Collector[(Long, String, Long, String)]) = {userDomainMap += value._1 -> value._2
}
}).setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(Long, String, Long, String)] { var maxOutOfOrderness: Long = 10000l var currentMaxTimestamp: Long = _ override def getCurrentWatermark: Watermark = {new Watermark(currentMaxTimestamp - maxOutOfOrderness)
} override def extractTimestamp(element: (Long, String, Long, String), previousElementTimestamp: Long): Long = {val timestamp = element._1currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp)
timestamp
}
}).keyBy(_._4)
.timeWindow(Time.minutes(1))
.apply(new WindowFunction[(Long,String,Long,String),(String,String,Long),String,TimeWindow] {override def apply(key: String, window: TimeWindow, input: Iterable[(Long, String, Long, String)], out: Collector[(String, String, Long)]): Unit = { val list = input.toList val sum = list.map(_._3).sum val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " + format.format(window.getEnd),key,sum))
}
}).addSink(builder.build)
env.execute("LogAnalysisWithMySQL")
}
}KibanaеӣҫиЎЁеұ•зӨә
иҝҷйҮҢжҲ‘们е°ұз”»дёҖдёӘзҺҜзҠ¶еӣҫеҗ§
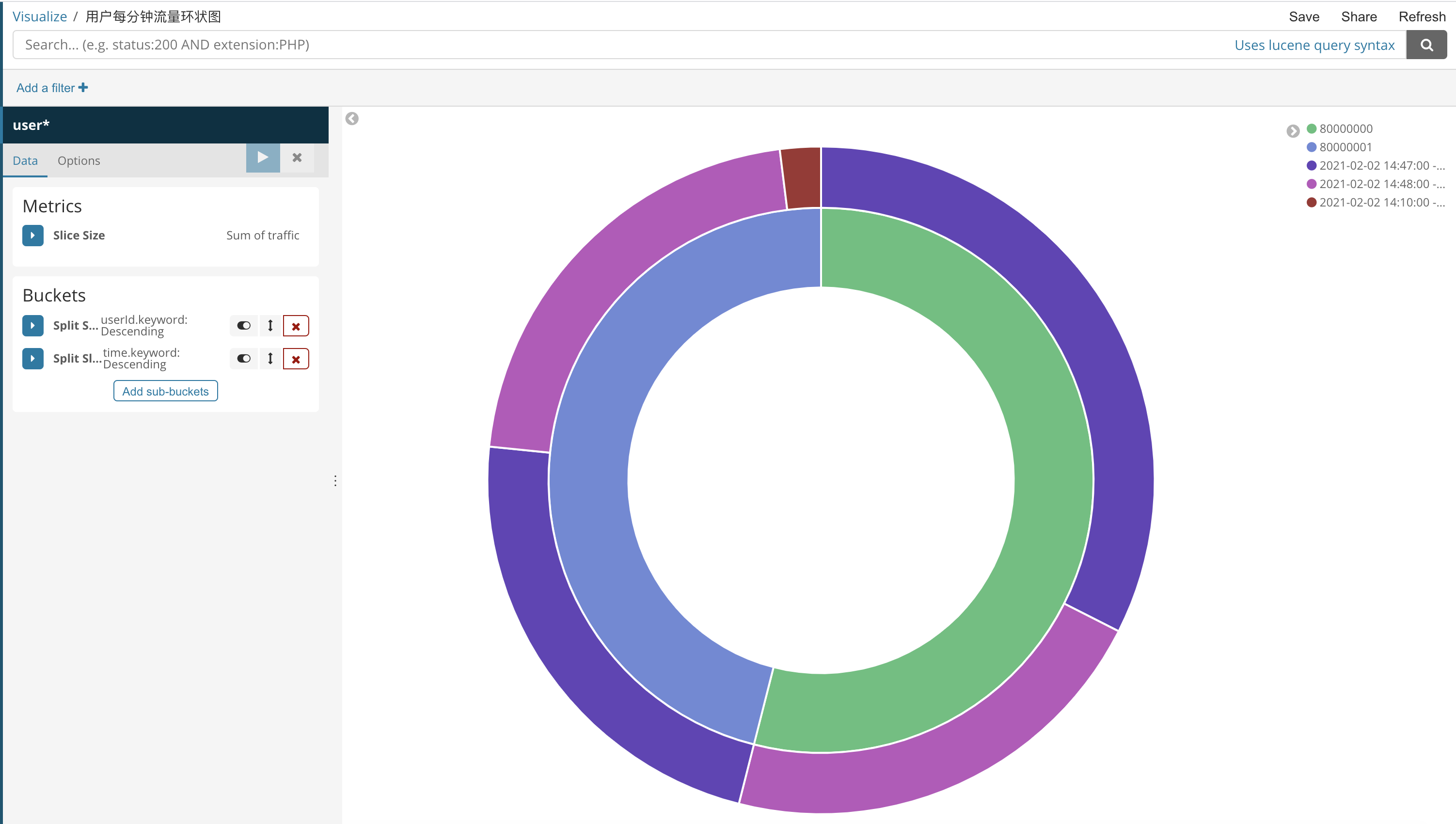
еҲ°жӯӨпјҢе…ідәҺвҖңFlinkз®ҖеҚ•йЎ№зӣ®ж•ҙдҪ“жөҒзЁӢжҳҜжҖҺж ·зҡ„вҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





