иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңKafkaе’ҢClickHouseдёӯзҡ„еә”з”ЁеҲҶжһҗвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁKafkaе’ҢClickHouseдёӯзҡ„еә”з”ЁеҲҶжһҗй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқKafkaе’ҢClickHouseдёӯзҡ„еә”з”ЁеҲҶжһҗвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
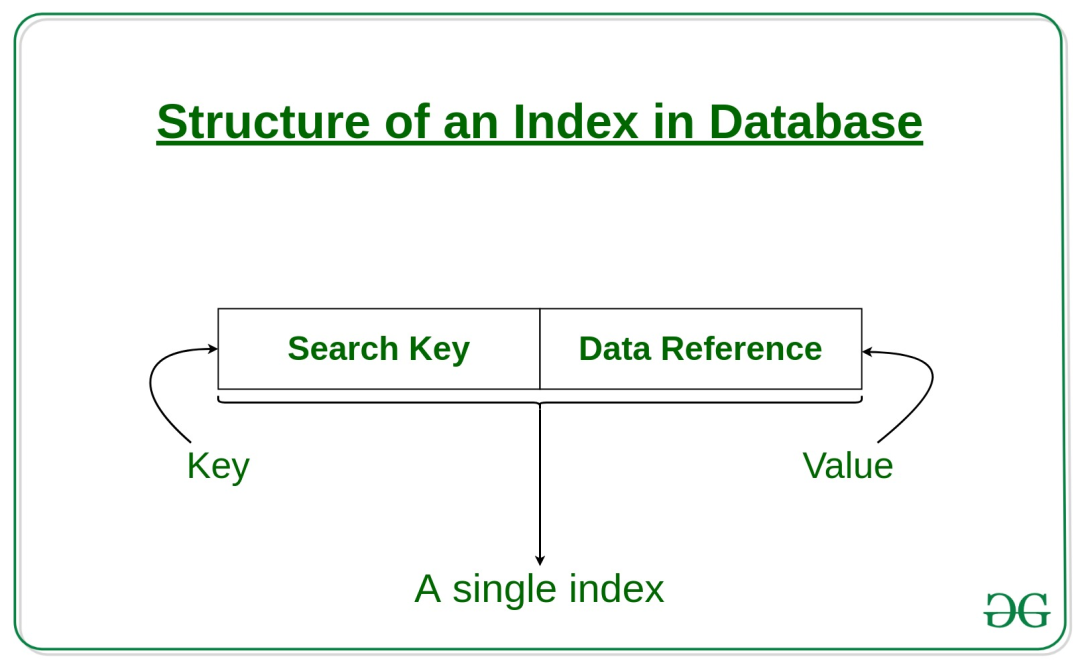
еңЁд»Ҙж•°жҚ®еә“дёәд»ЈиЎЁзҡ„еӯҳеӮЁзі»з»ҹдёӯпјҢзҙўеј•пјҲindexпјүжҳҜдёҖз§Қйҷ„еҠ дәҺеҺҹе§Ӣж•°жҚ®д№ӢдёҠзҡ„ж•°жҚ®з»“жһ„пјҢиғҪеӨҹйҖҡиҝҮеҮҸе°‘зЈҒзӣҳи®ҝй—®жқҘжҸҗеҚҮжҹҘиҜўйҖҹеәҰпјҢдёҺзҺ°е®һдёӯзҡ„д№ҰзұҚзӣ®еҪ•ејӮжӣІеҗҢе·ҘгҖӮзҙўеј•йҖҡеёёеҢ…еҗ«дёӨйғЁеҲҶпјҢеҚізҙўеј•й”®пјҲвүҲз« иҠӮпјүдёҺжҢҮеҗ‘еҺҹе§Ӣж•°жҚ®зҡ„жҢҮй’ҲпјҲвүҲйЎөз ҒпјүпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
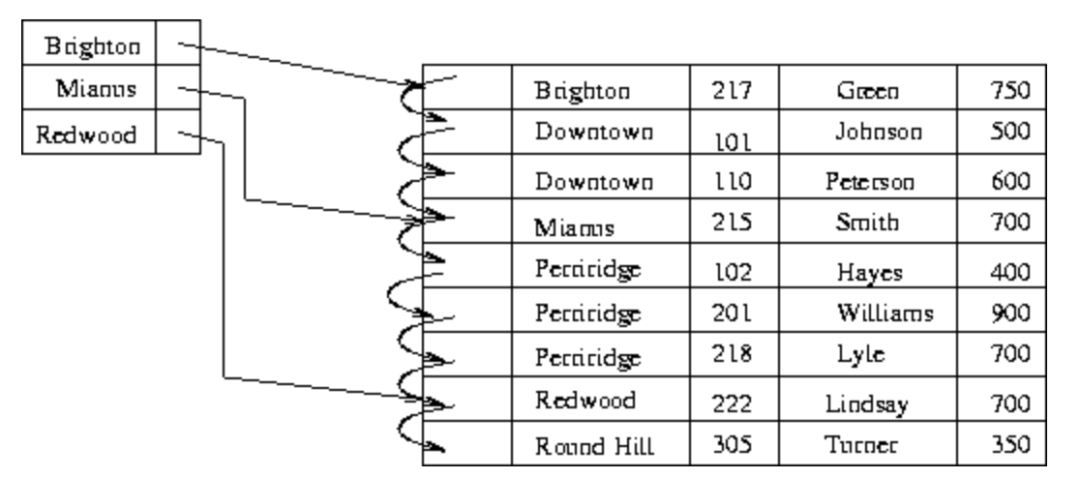
зҙўеј•зҡ„з»„з»ҮеҪўејҸеӨҡз§ҚеӨҡж ·пјҢжң¬ж–ҮиҰҒд»Ӣз»Қзҡ„зЁҖз–Ҹзҙўеј•пјҲsparse indexпјүжҳҜдёҖз§Қз®ҖеҚ•иҖҢеёёз”Ёзҡ„жңүеәҸзҙўеј•еҪўејҸвҖ”вҖ”еҚіеңЁж•°жҚ®дё»й”®жңүеәҸзҡ„еҹәзЎҖдёҠпјҢеҸӘдёәйғЁеҲҶпјҲйҖҡеёёжҳҜиҫғе°‘дёҖйғЁеҲҶпјүеҺҹе§Ӣж•°жҚ®е»әз«Ӣзҙўеј•пјҢд»ҺиҖҢеңЁжҹҘиҜўж—¶иғҪеӨҹеңҲе®ҡеҮәеӨ§иҮҙзҡ„иҢғеӣҙпјҢеҶҚеңЁиҢғеӣҙеҶ…еҲ©з”ЁйҖӮеҪ“зҡ„жҹҘжүҫз®—жі•жүҫеҲ°зӣ®ж Үж•°жҚ®гҖӮеҰӮдёӢеӣҫжүҖзӨәпјҢдёә3жқЎеҺҹе§Ӣж•°жҚ®е»әз«ӢдәҶзЁҖз–Ҹзҙўеј•гҖӮ
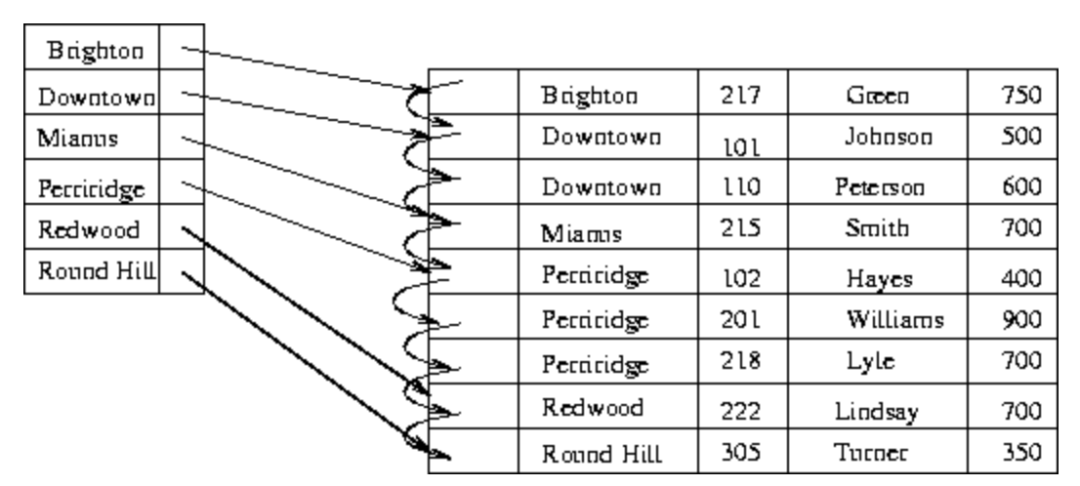
зӣёеҜ№ең°пјҢеҰӮжһңдёәжүҖжңүеҺҹе§Ӣж•°жҚ®е»әз«Ӣзҙўеј•пјҢе°ұз§°дёәзЁ еҜҶзҙўеј•пјҲdense indexпјүпјҢеҰӮдёӢеӣҫгҖӮ
зЁ еҜҶзҙўеј•е’ҢзЁҖз–Ҹзҙўеј•е…¶е®һе°ұжҳҜз©әй—ҙе’Ңж—¶й—ҙзҡ„trade-offгҖӮеңЁж•°жҚ®йҮҸе·ЁеӨ§ж—¶пјҢдёәжҜҸжқЎж•°жҚ®йғҪе»әз«Ӣзҙўеј•д№ҹдјҡиҖ—иҙ№еӨ§йҮҸз©әй—ҙпјҢжүҖд»ҘзЁҖз–Ҹзҙўеј•еңЁзү№е®ҡеңәжҷҜйқһеёёеҘҪз”ЁгҖӮд»ҘдёӢдёҫдёӨдёӘдҫӢеӯҗгҖӮ
Sparse Index in Kafka
жҲ‘们зҹҘйҒ“пјҢеҚ•дёӘKafkaзҡ„TopicPartitionдёӯпјҢж¶ҲжҒҜж•°жҚ®дјҡиў«еҲҮеҲҶжҲҗж®өпјҲsegmentпјүжқҘеӯҳеӮЁпјҢжү©еұ•еҗҚдёә.logгҖӮlogж–Ү件зҡ„еҲҮеҲҶж—¶жңәз”ұеӨ§е°ҸеҸӮж•°log.segment.bytesпјҲй»ҳи®ӨеҖј1Gпјүе’Ңж—¶й—ҙеҸӮж•°log.roll.hoursпјҲй»ҳи®ӨеҖј7еӨ©пјүе…ұеҗҢеҶіе®ҡгҖӮж•°жҚ®зӣ®еҪ•дёӯеӯҳеӮЁзҡ„йғЁеҲҶж–Ү件еҰӮдёӢгҖӮ
.
в”ңв”Җв”Җ 00000000000190089251.index
в”ңв”Җв”Җ 00000000000190089251.log
в”ңв”Җв”Җ 00000000000190089251.timeindex
в”ңв”Җв”Җ 00000000000191671269.index
в”ңв”Җв”Җ 00000000000191671269.log
в”ңв”Җв”Җ 00000000000191671269.timeindex
в”ңв”Җв”Җ 00000000000193246592.index
в”ңв”Җв”Җ 00000000000193246592.log
в”ңв”Җв”Җ 00000000000193246592.timeindex
в”ңв”Җв”Җ 00000000000194821538.index
в”ңв”Җв”Җ 00000000000194821538.log
в”ңв”Җв”Җ 00000000000194821538.timeindex
в”ңв”Җв”Җ 00000000000196397456.index
в”ңв”Җв”Җ 00000000000196397456.log
в”ңв”Җв”Җ 00000000000196397456.timeindex
в”ңв”Җв”Җ 00000000000197971543.index
в”ңв”Җв”Җ 00000000000197971543.log
в”ңв”Җв”Җ 00000000000197971543.timeindex
......
logж–Ү件зҡ„ж–Ү件еҗҚйғҪжҳҜ64дҪҚж•ҙеҪўпјҢиЎЁзӨәиҝҷдёӘlogж–Ү件еҶ…еӯҳеӮЁзҡ„第дёҖжқЎж¶ҲжҒҜзҡ„offsetеҖјеҮҸеҺ»1пјҲд№ҹе°ұжҳҜдёҠдёҖдёӘlogж–Ү件жңҖеҗҺдёҖжқЎж¶ҲжҒҜзҡ„offsetеҖјпјүгҖӮжҜҸдёӘlogж–Ү件йғҪдјҡй…ҚеӨҮдёӨдёӘзҙўеј•ж–Ү件вҖ”вҖ”indexе’ҢtimeindexпјҢеҲҶеҲ«еҜ№еә”еҒҸ移йҮҸзҙўеј•е’Ңж—¶й—ҙжҲізҙўеј•пјҢдё”еқҮдёәзЁҖз–Ҹзҙўеј•гҖӮ
еҸҜд»ҘйҖҡиҝҮKafkaжҸҗдҫӣзҡ„DumpLogSegmentsе°Ҹе·Ҙе…·жқҘжҹҘзңӢзҙўеј•ж–Ү件дёӯзҡ„дҝЎжҒҜгҖӮ
~ kafka-run-class kafka.tools.DumpLogSegments --files /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.index
Dumping /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.index
offset: 197971551 position: 5207
offset: 197971558 position: 9927
offset: 197971565 position: 14624
offset: 197971572 position: 19338
offset: 197971578 position: 23509
offset: 197971585 position: 28392
offset: 197971592 position: 33174
offset: 197971599 position: 38036
offset: 197971606 position: 42732
......
~ kafka-run-class kafka.tools.DumpLogSegments --files /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.timeindex
Dumping /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.timeindex
timestamp: 1593230317565 offset: 197971551
timestamp: 1593230317642 offset: 197971558
timestamp: 1593230317979 offset: 197971564
timestamp: 1593230318346 offset: 197971572
timestamp: 1593230318558 offset: 197971578
timestamp: 1593230318579 offset: 197971582
timestamp: 1593230318765 offset: 197971592
timestamp: 1593230319117 offset: 197971599
timestamp: 1593230319442 offset: 197971606
......
еҸҜи§ҒпјҢindexж–Ү件дёӯеӯҳеӮЁзҡ„жҳҜoffsetеҖјдёҺеҜ№еә”ж•°жҚ®еңЁlogж–Ү件дёӯеӯҳеӮЁдҪҚзҪ®зҡ„жҳ е°„пјҢиҖҢtimeindexж–Ү件дёӯеӯҳеӮЁзҡ„жҳҜж—¶й—ҙжҲідёҺеҜ№еә”ж•°жҚ®offsetеҖјзҡ„жҳ е°„гҖӮжңүдәҶе®ғ们пјҢе°ұеҸҜд»Ҙеҝ«йҖҹең°йҖҡиҝҮoffsetеҖјжҲ–ж—¶й—ҙжҲіе®ҡдҪҚеҲ°ж¶ҲжҒҜзҡ„е…·дҪ“дҪҚзҪ®дәҶгҖӮ并且з”ұдәҺзҙўеј•ж–Ү件зҡ„sizeйғҪдёҚеӨ§пјҢеӣ жӯӨеҫҲе®№жҳ“е°Ҷе®ғ们еҒҡеҶ…еӯҳжҳ е°„пјҲmmapпјүпјҢеӯҳеҸ–ж•ҲзҺҮеҫҲй«ҳгҖӮ
д»Ҙindexж–Ү件дёәдҫӢпјҢеҰӮжһңжҲ‘们жғіиҰҒжүҫеҲ°offset=197971577зҡ„ж¶ҲжҒҜпјҢжөҒзЁӢжҳҜпјҡ
йҖҡиҝҮдәҢеҲҶжҹҘжүҫпјҢеңЁindexж–Ү件еәҸеҲ—дёӯпјҢжүҫеҲ°еҢ…еҗ«иҜҘoffsetзҡ„ж–Ү件пјҲ00000000000197971543.indexпјүпјӣ
йҖҡиҝҮдәҢеҲҶжҹҘжүҫпјҢеңЁдёҠдёҖжӯҘе®ҡдҪҚеҲ°зҡ„indexж–Ү件дёӯпјҢжүҫеҲ°иҜҘoffsetжүҖеңЁеҢәй—ҙзҡ„иө·зӮ№пјҲ197971592пјүпјӣ
д»ҺдёҠдёҖжӯҘзҡ„иө·зӮ№ејҖе§ӢйЎәеәҸжҹҘжүҫпјҢзӣҙеҲ°жүҫеҲ°зӣ®ж ҮoffsetгҖӮ
жңҖеҗҺпјҢзЁҖз–Ҹзҙўеј•зҡ„зІ’еәҰз”ұlog.index.interval.bytesеҸӮж•°жқҘеҶіе®ҡпјҢй»ҳи®Өдёә4KBпјҢеҚіжҜҸйҡ”logж–Ү件дёӯ4KBзҡ„ж•°жҚ®йҮҸз”ҹжҲҗдёҖжқЎзҙўеј•ж•°жҚ®гҖӮи°ғеӨ§иҝҷдёӘеҸӮж•°дјҡдҪҝеҫ—зҙўеј•жӣҙеҠ зЁҖз–ҸпјҢеҸҚд№ӢеҲҷдјҡжӣҙзЁ еҜҶгҖӮ
Sparse Index in ClickHouse
еңЁClickHouseдёӯпјҢMergeTreeеј•ж“ҺиЎЁзҡ„зҙўеј•еҲ—еңЁе»әиЎЁж—¶дҪҝз”ЁORDER BYиҜӯжі•жқҘжҢҮе®ҡгҖӮиҖҢеңЁе®ҳж–№ж–ҮжЎЈдёӯпјҢз”ЁдәҶдёӢйқўдёҖе№…еӣҫжқҘиҜҙжҳҺгҖӮ

иҝҷеј еӣҫзӨәеҮәдәҶд»ҘCounterIDгҖҒDateдёӨеҲ—дёәзҙўеј•еҲ—зҡ„жғ…еҶөпјҢеҚіе…Ҳд»ҘCounterIDдёәдё»иҰҒе…ій”®еӯ—жҺ’еәҸпјҢеҶҚд»ҘDateдёәж¬ЎиҰҒе…ій”®еӯ—жҺ’еәҸпјҢжңҖеҗҺз”ЁдёӨеҲ—зҡ„з»„еҗҲдҪңдёәзҙўеј•й”®гҖӮmarksдёҺmark numbersе°ұжҳҜзҙўеј•ж Үи®°пјҢдё”marksд№Ӣй—ҙзҡ„й—ҙйҡ”е°ұз”ұе»әиЎЁж—¶зҡ„зҙўеј•зІ’еәҰеҸӮж•°index_granularityжқҘжҢҮе®ҡпјҢй»ҳи®ӨеҖјдёә8192гҖӮ
ClickHouse MergeTreeеј•ж“ҺиЎЁдёӯпјҢжҜҸдёӘpartзҡ„ж•°жҚ®еӨ§иҮҙд»ҘдёӢйқўзҡ„з»“жһ„еӯҳеӮЁгҖӮ
.
в”ңв”Җв”Җ business_area_id.bin
в”ңв”Җв”Җ business_area_id.mrk2
в”ңв”Җв”Җ coupon_money.bin
в”ңв”Җв”Җ coupon_money.mrk2
в”ңв”Җв”Җ groupon_id.bin
в”ңв”Җв”Җ groupon_id.mrk2
в”ңв”Җв”Җ is_new_order.bin
в”ңв”Җв”Җ is_new_order.mrk2
......
в”ңв”Җв”Җ primary.idx
......
е…¶дёӯпјҢbinж–Ү件еӯҳеӮЁзҡ„жҳҜжҜҸдёҖеҲ—зҡ„еҺҹе§Ӣж•°жҚ®пјҲеҸҜиғҪиў«еҺӢзј©еӯҳеӮЁпјүпјҢmrk2ж–Ү件еӯҳеӮЁзҡ„жҳҜеӣҫдёӯзҡ„mark numbersдёҺbinж–Ү件дёӯж•°жҚ®дҪҚзҪ®зҡ„жҳ е°„е…ізі»гҖӮеҸҰеӨ–пјҢиҝҳжңүдёҖдёӘprimary.idxж–Ү件еӯҳеӮЁиў«зҙўеј•еҲ—зҡ„е…·дҪ“ж•°жҚ®гҖӮеҸҰеӨ–пјҢжҜҸдёӘpartзҡ„ж•°жҚ®йғҪеӯҳеӮЁеңЁеҚ•зӢ¬зҡ„зӣ®еҪ•дёӯпјҢзӣ®еҪ•еҗҚеҪўеҰӮ20200708_92_121_7пјҢеҚіеҢ…еҗ«дәҶеҲҶеҢәй”®гҖҒиө·е§Ӣmark numberе’Ңз»“жқҹmark numberпјҢж–№дҫҝе®ҡдҪҚгҖӮ
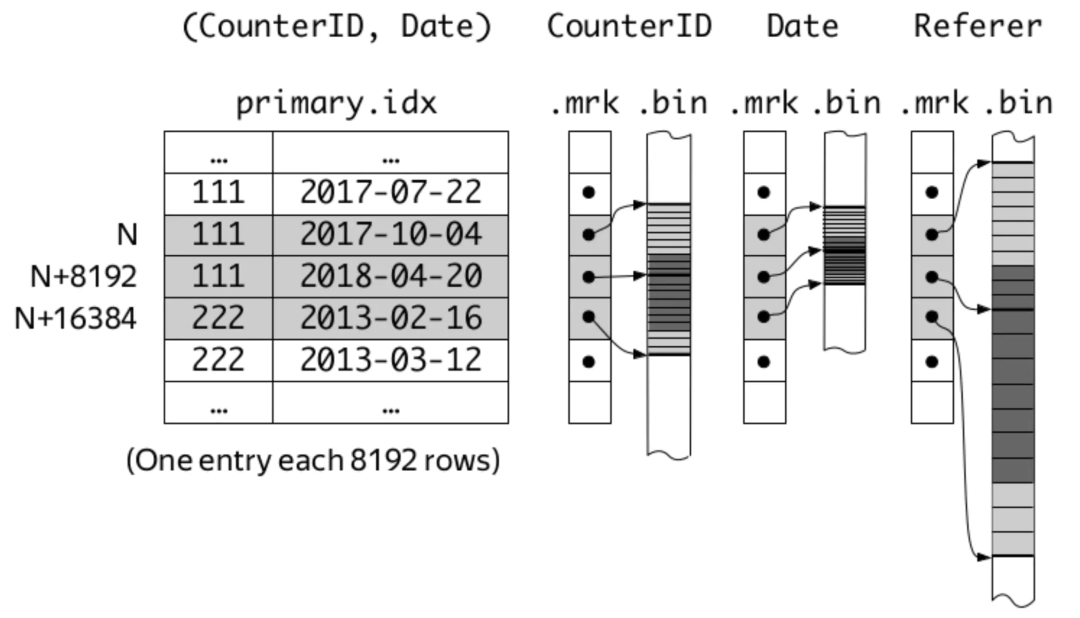
иҝҷж ·пјҢжҜҸдёҖеҲ—йғҪйҖҡиҝҮORDER BYеҲ—иҝӣиЎҢдәҶзҙўеј•гҖӮжҹҘиҜўж—¶пјҢе…ҲжҹҘжүҫеҲ°ж•°жҚ®жүҖеңЁзҡ„partsпјҢеҶҚйҖҡиҝҮmrk2ж–Ү件确е®ҡbinж–Ү件дёӯж•°жҚ®зҡ„иҢғеӣҙеҚіеҸҜгҖӮ
дёҚиҝҮпјҢClickHouseзҡ„зЁҖз–Ҹзҙўеј•дёҺKafkaзҡ„зЁҖз–Ҹзҙўеј•дёҚеҗҢпјҢеҸҜд»Ҙз”ұз”ЁжҲ·иҮӘз”ұз»„еҗҲеӨҡеҲ—пјҢеӣ жӯӨд№ҹиҰҒж јеӨ–жіЁж„ҸдёҚиҰҒеҠ е…ҘеӨӘеӨҡзҙўеј•еҲ—пјҢйҳІжӯўзҙўеј•ж•°жҚ®иҝҮдәҺзЁҖз–ҸпјҢеўһеӨ§еӯҳеӮЁе’ҢжҹҘжүҫжҲҗжң¬гҖӮеҸҰеӨ–пјҢеҹәж•°еӨӘе°ҸпјҲеҚіеҢәеҲҶеәҰеӨӘдҪҺпјүзҡ„еҲ—дёҚйҖӮеҗҲеҒҡзҙўеј•еҲ—пјҢеӣ дёәеҫҲеҸҜиғҪжЁӘи·ЁеӨҡдёӘmarkзҡ„еҖјд»Қ然зӣёеҗҢпјҢжІЎжңүзҙўеј•зҡ„ж„Ҹд№үдәҶгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңKafkaе’ҢClickHouseдёӯзҡ„еә”з”ЁеҲҶжһҗвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





