小编给大家分享一下网易数据湖Iceberg的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
痛点一:
我们凌晨一些大的离线任务经常会因为一些原因出现延迟,这种延迟会导致核心报表的产出时间不稳定,有些时候会产出比较早,但是有时候就可能会产出比较晚,业务很难接受。
为什么会出现这种现象的发生呢?目前来看大致有这么几点要素:
任务本身要请求的数据量会特别大。通常来说一天原始的数据量可能在几十TB。几百个分区,甚至上千个分区,五万+的文件数这样子。如果说全量读取这些文件的话,几百个分区就会向NameNode发送几百次请求,我们知道离线任务在凌晨运行的时候,NameNode的压力是非常大的。所以就很有可能出现Namenode响应很慢的情况,如果请求响应很慢就会导致任务初始化时间很长。
任务本身的ETL效率是相对低效的,这个低效并不是说Spark引擎低效,而是说我们的存储在这块支持的不是特别的好。比如目前我们查一个分区的话是需要将所有文件都扫描一遍然后进行分析,而实际上我可能只对某些文件感兴趣。所以相对而言这个方案本身来说就是相对低效的。
这种大的离线任务一旦遇到磁盘坏盘或者机器宕机,就需要重试,重试一次需要耗费很长的时间比如几十分钟。如果说重试一两次的话这个延迟就会比较大了。
痛点二:
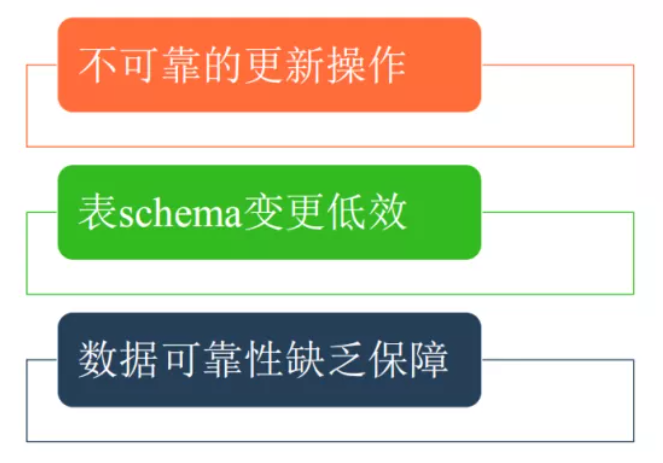
针对一些细琐的一些问题而言的。这里简单列举了三个场景来分析:
不可靠的更新操作。我们经常在ETL过程中执行一些insert overwrite之类的操作,这类操作会先把相应分区的数据删除,再把生成的文件加载到分区中去。在我们移除文件的时候,很多正在读取这些文件的任务就会发生异常,这就是不可靠的更新操作。
表Schema变更低效。目前我们在对表做一些加字段、更改分区的操作其实是非常低效的操作,我们需要把所有的原始数据读出来,然后在重新写回去。这样就会非常耗时,并且低效。
数据可靠性缺乏保障。主要是我们对于分区的操作,我们会把分区的信息分为两个地方,HDFS和Metastore,分别存储一份。在这种情况下,如果进行更新操作,就可能会出现一个更新成功而另一个更新失败,会导致数据不可靠。
痛点三:
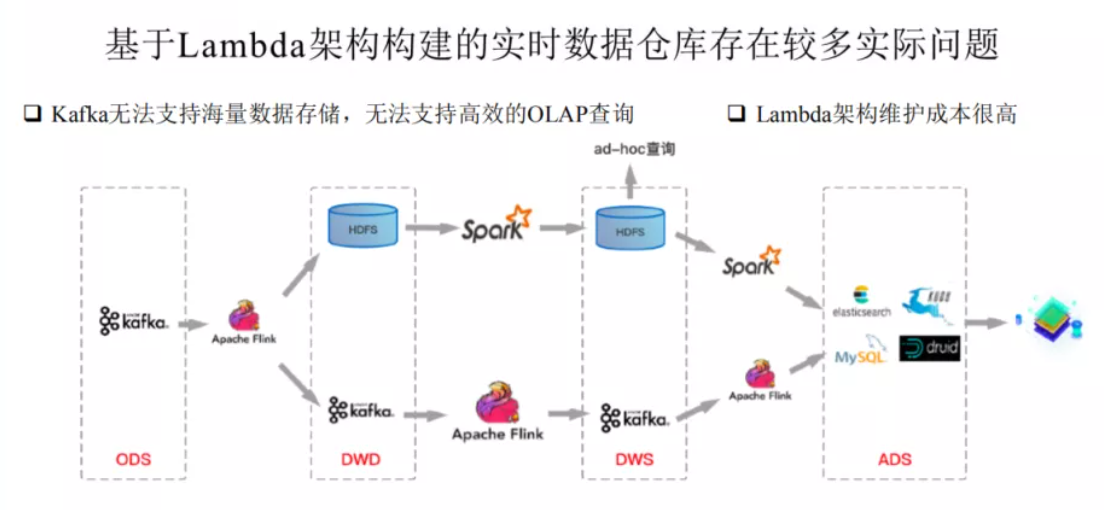
基于Lambda架构建设的实时数仓存在较多的问题。如上图的这个架构图,第一条链路是基于kafka中转的一条实时链路(延迟要求小于5分钟),另一条是离线链路(延迟大于1小时),甚至有些公司会有第三条准实时链路(延迟要求5分钟~一小时),甚至更复杂的场景。
两条链路对应两份数据,很多时候实时链路的处理结果和离线链路的处理结果对不上。
Kafka无法存储海量数据, 无法基于当前的OLAP分析引擎高效查询Kafka中的数据。
Lambda维护成本高。代码、数据血缘、Schema等都需要两套。运维、监控等成本都非常高。
痛点四:
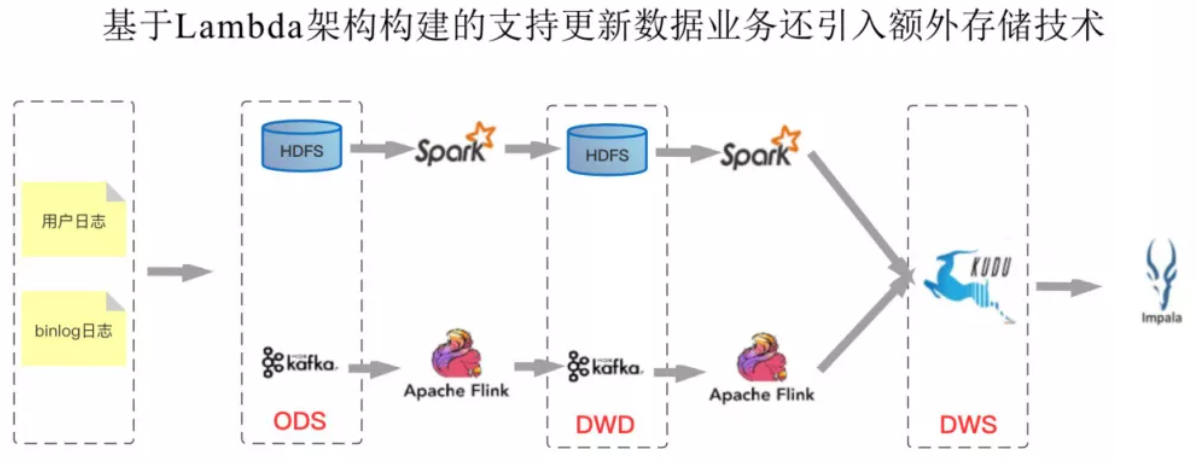
不能友好地支持高效更新场景。大数据的更新场景一般有两种,一种是CDC ( Change Data Capture ) 的更新,尤其在电商的场景下,将binlog中的更新删除同步到HDFS上。另一种是延迟数据带来的聚合后结果的更新。目前HDFS只支持追加写,不支持更新。因此业界很多公司引入了Kudu。但是Kudu本身是有一些局限的,比如计算存储没有做到分离。这样整个数仓系统中引入了HDFS、Kafka以及Kudu,运维成本不可谓不大。
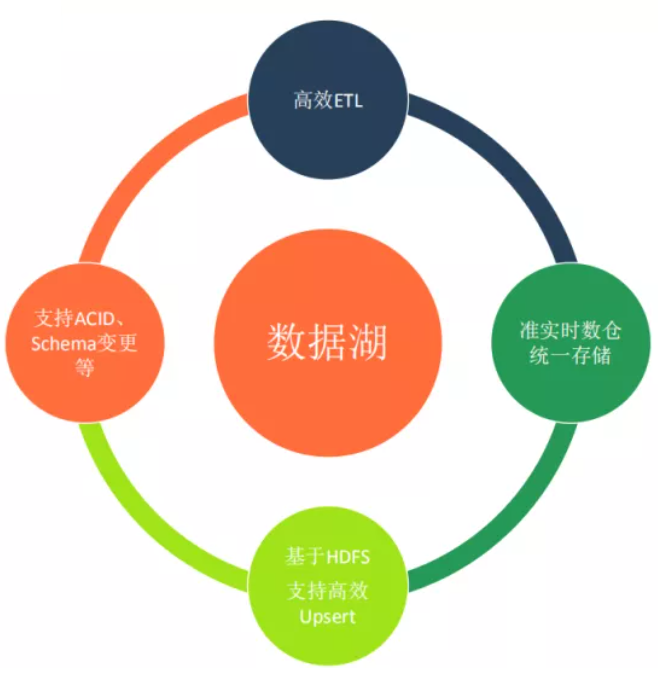
上面就是针对目前数仓所涉及到的四个痛点的大致介绍,因此我们也是通过对数据湖的调研和实践,希望能在这四个方面对数仓建设有所帮助。接下来重点讲解下对数据湖的一些思考。
1. 数据湖开源产品调研
数据湖大致是从19年开始慢慢火起来的,目前市面上核心的数据湖开源产品大致有这么几个:
DELTA LAKE,在17年的时候DataBricks就做了DELTA LAKE的商业版。主要想解决的也是基于Lambda架构带来的存储问题,它的初衷是希望通过一种存储来把Lambda架构做成kappa架构。
Hudi ( Uber开源 ) 可以支持快速的更新以及增量的拉取操作。这是它最大的卖点之一。
Iceberg的初衷是想做标准的Table Format以及高效的ETL。
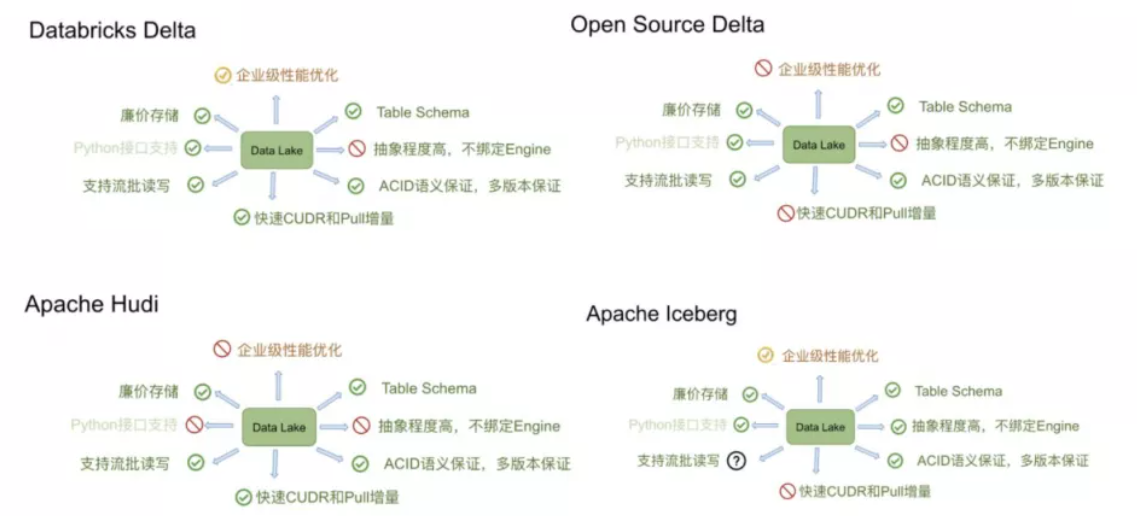
上图是来自阿里Flink团体针对数据湖方案的一些调研对比,总体来看这些方案的基础功能相对都还是比较完善的。我说的基础功能主要包括:
高效Table Schema的变更,比如针对增减分区,增减字段等功能
ACID语义保证
同时支持流批读写,不会出现脏读等现象
支持OSS这类廉价存储
2. 当然还有一些不同点:
Hudi的特性主要是支持快速的更新删除和增量拉取。
Iceberg的特性主要是代码抽象程度高,不绑定任何的Engine。它暴露出来了非常核心的表层面的接口,可以非常方便的与Spark/Flink对接。然而Delta和Hudi基本上和spark的耦合很重。如果想接入flink,相对比较难。
3. 我们选择Iceberg的原因:
现在国内的实时数仓建设围绕flink的情况会多一点。所以能够基于flink扩展生态,是我们选择iceberg一个比较重要的点。
国内也有很多基于Iceberg开发的重要力量,比如腾讯团队、阿里Flink官方团队,他们的数据湖选型也是Iceberg。目前他们在社区分别主导update以及flink的生态对接。
4. 接下来我们重点介绍一下Iceberg:
这是来自官方对于Iceberg的一段介绍,大致就是Iceberg是一个开源的基于表格式的数据湖。关于table format再给大家详细介绍下:
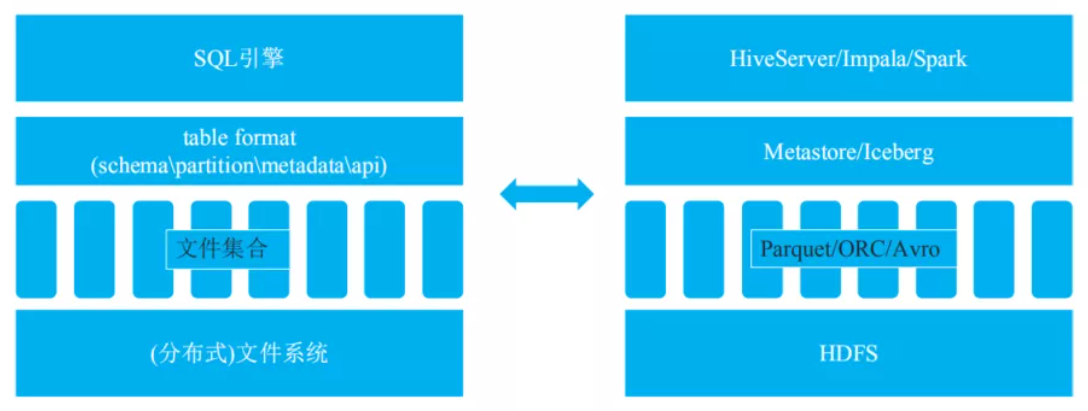
左侧图是一个抽象的数据处理系统,分别由SQL引擎、table format、文件集合以及分布式文件系统构成。右侧是对应的现实中的组件,SQL引擎比如HiveServer、Impala、Spark等等,table format比如Metastore或者Iceberg,文件集合主要有Parquet文件等,而分布式文件系统就是HDFS。
对于table format,我认为主要包含4个层面的含义,分别是表schema定义(是否支持复杂数据类型),表中文件的组织形式,表相关统计信息、表索引信息以及表的读写API实现。详述如下:
表schema定义了一个表支持字段类型,比如int、string、long以及复杂数据类型等。
表中文件组织形式最典型的是Partition模式,是Range Partition还是Hash Partition。
Metadata数据统计信息。
封装了表的读写API。上层引擎通过对应的API读取或者写入表中的数据。
和Iceberg差不多相当的一个组件是Metastore。不过Metastore是一个服务,而Iceberg就是一个jar包。这里就Metastore 和 Iceberg在表格式的4个方面分别进行一下对比介绍:
① 在schema层面上没有任何区别:
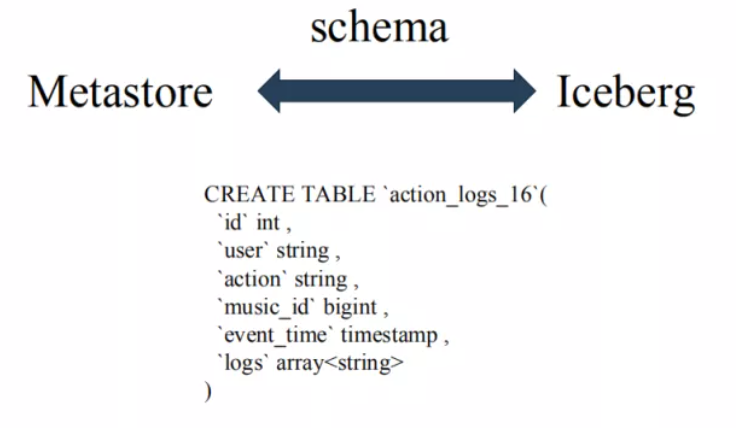
都支持int、string、bigint等类型。
② partition实现完全不同:
两者在partition上有很大的不同:
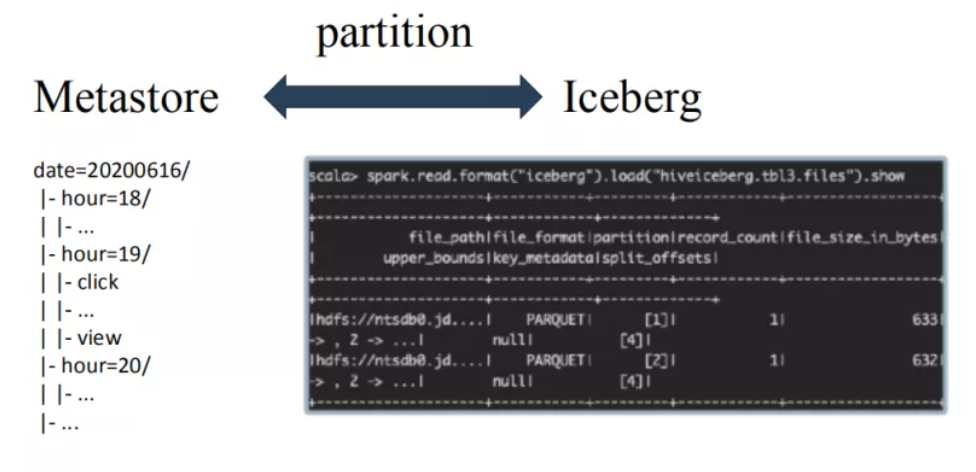
metastore中partition字段不能是表字段,因为partition字段本质上是一个目录结构,不是用户表中的一列数据。基于metastore,用户想定位到一个partition下的所有数据,首先需要在metastore中定位出该partition对应的所在目录位置信息,然后再到HDFS上执行list命令获取到这个分区下的所有文件,对这些文件进行扫描得到这个partition下的所有数据。
iceberg中partition字段就是表中的一个字段。Iceberg中每一张表都有一个对应的文件元数据表,文件元数据表中每条记录表示一个文件的相关信息,这些信息中有一个字段是partition字段,表示这个文件所在的partition。
很明显,iceberg表根据partition定位文件相比metastore少了一个步骤,就是根据目录信息去HDFS上执行list命令获取分区下的文件。
试想,对于一个二级分区的大表来说,一级分区是小时时间分区,二级分区是一个枚举字段分区,假如每个一级分区下有30个二级分区,那么这个表每天就会有24 * 30 = 720个分区。基于Metastore的partition方案,如果一个SQL想基于这个表扫描昨天一天的数据的话,就需要向Namenode下发720次list请求,如果扫描一周数据或者一个月数据,请求数就更是相当夸张。这样,一方面会导致Namenode压力很大,一方面也会导致SQL请求响应延迟很大。而基于Iceberg的partition方案,就完全没有这个问题。
③ 表统计信息实现粒度不同:
Metastore中一张表的统计信息是表/分区级别粒度的统计信息,比如记录一张表中某一列的记录数量、平均长度、为null的记录数量、最大值\最小值等。
Iceberg中统计信息精确到文件粒度,即每个数据文件都会记录所有列的记录数量、平均长度、最大值\最小值等。
很明显,文件粒度的统计信息对于查询中谓词(即where条件)的过滤会更有效果。
④ 读写API实现不同:
metastore模式下上层引擎写好一批文件,调用metastore的add partition接口将这些文件添加到某个分区下。
Iceberg模式下上层业务写好一批文件,调用iceberg的commit接口提交本次写入形成一个新的snapshot快照。这种提交方式保证了表的ACID语义。同时基于snapshot快照提交可以实现增量拉取实现。
总结下Iceberg相对于Metastore的优势:
新partition模式:避免了查询时n次调用namenode的list方法,降低namenode压力,提升查询性能
新metadata模式:文件级别列统计信息可以用来根据where字段进行文件过滤,很多场景下可以大大减少扫描文件数,提升查询性能
新API模式:存储批流一体
1. 流式写入-增量拉取(基于Iceberg统一存储模式可以同时满足业务批量读取以及增量订阅需求)
2. 支持批流同时读写同一张表,统一表schema,任务执行过程中不会出现FileNotFoundException
Iceberg的提升体现在:
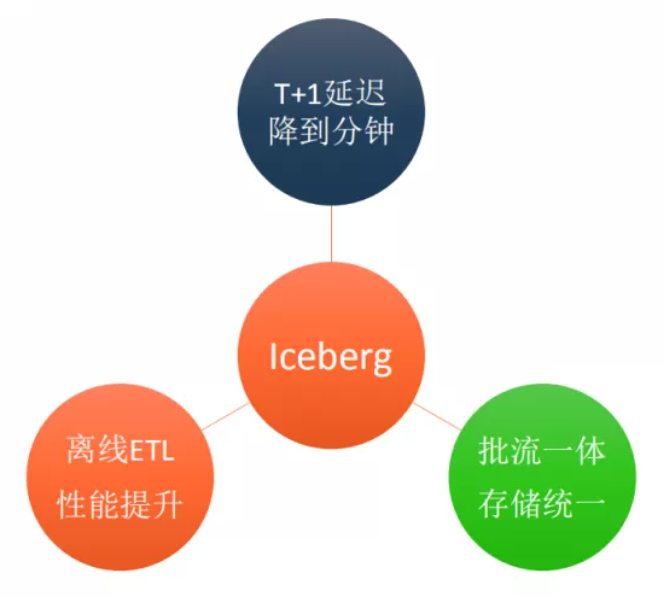
目前Iceberg主要支持的计算引擎包括Spark2.4.5、Spark 3.x以及Presto。同时,一些运维工作比如snapshot过期、小文件合并、增量订阅消费等功能都可以实现。
在此基础上,目前社区正在开发的功能主要有Hive集成、Flink集成以及支持Update/Delete功能。相信下一个版本就可以看到Hive/Flink集成的相关功能。
Iceberg针对目前的大数量的情况下,可以大大提升ETL任务执行的效率,这主要得益于新Partition模式下不再需要请求NameNode分区信息,同时得益于文件级别统计信息模式下可以过滤很多不满足条件的数据文件。
当前iceberg社区仅支持Spark2.4.5,我们在这个基础上做了更多计算引擎的适配工作。主要包括如下:
集成Hive。可以通过Hive创建和删除iceberg表,通过HiveSQL查询Iceberg表中的数据。
集成Impala。用户可以通过Impala新建iceberg内表\外表,并通过Impala查询Iceberg表中的数据。目前该功能已经贡献给Impala社区。
集成Flink。已经实现了Flink到Iceberg的sink实现,业务可以消费kafka中的数据将结果写入到Iceberg中。同时我们基于Flink引擎实现了小文件异步合并的功能,这样可以实现Flink一边写数据文件,一边执行小文件的合并。基于Iceberg的小文件合并通过commit的方式提交,不需要删除合并前的小文件,也就不会引起读取任务的任何异常。
以上是“网易数据湖Iceberg的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





