小编给大家分享一下爬虫的实现原理是什么,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
网络爬虫也被称作网络机器人、网络蜘蛛、网络蚂蚁、网络机器人等。
网络爬虫通常由控制节点、爬虫节点和资源库构成。
控制节点,也叫做爬虫的中央控制器,主要负责根据URL地址(URL:UniformResourceLocation,统一资源定位符,即Internet上用来描述信息资源的字符串,主要用在各种www客户程序和服务器程序上)分配线程,并调用爬虫节点进行具体的爬行任务。
爬虫节点,会按照相关算法对网页进行具体爬行(包括下载网页、对网页文本进行处理等),爬行后会将相应的结果存储到对应的资源库中。
从图中我们可以看到,网络爬虫中可以有多个控制节点,而每个控制节点下又可以有多个爬虫节点。
控制节点之间、控制节点和其下的各爬虫节点间、同一控制节点下的各爬虫节点间都可以相互通信。
了解了网络爬虫的组成,那么,网络爬虫具体有哪些类型呢?
根据实现的技术和结构,网络爬虫可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫和深度网络爬虫等几种类型。
在实际的网络爬虫中,通常都是这几类爬虫的组合体。
对于不同类型的网络爬虫,其实现原理也是不同的,但这些实现原理中,会存在很多共性。
下面将以通用网络爬虫和聚焦网络爬虫为主,对网络爬虫的实现原理进行介绍。
通用网络爬虫的实现原理及过程可简要概括如下图:
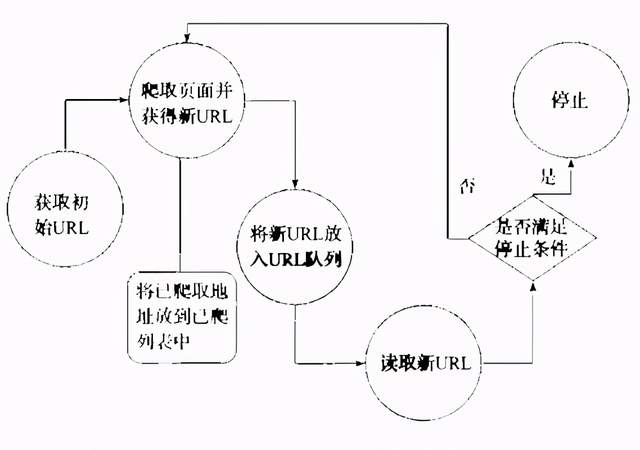
图:通用网络爬虫的实现原理及过程
1. 获取初始URL
初始URL地址可以由用户人为指定,也可以由用户指定的某个或某几个初始爬取网页决定。
2. 根据初始URL爬取页面并获得新的URL
获得初始URL地址之后,需要对对应的网页进行爬取,并将网页存储到原始数据库中,同时将已爬取的URL地址存放到一个URL列表中,并发现新的URL地址,以此来用于去重及判断爬取的进程。
3. 将新的URL放到URL队列中
在第2步中,会将新获取的URL地址放到URL队列中。
4. 重复爬取过程
从URL队列中读取新的URL,并依据新的URL爬取网页,同时再从新网页中获取新URL,并重复上述的爬取过程。
*在编写爬虫的时候,一般会设置相应的停止条件,当过程满足爬虫系统设置的停止条件时就停止爬取。相对地,如果没有设置停止条件,爬虫则会一直爬取下去,直到无法获取新的URL地址为止。
由于聚焦网络爬虫需要有目的地进行爬取,所以相对于通用网络爬虫来说,聚焦网络爬虫还必须要增加目标定义及过滤机制,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选取等。
整个过程如下图所示:
图:聚焦网络爬虫的基本原理及其实现过程
1. 对爬取目标的定义和描述
首先依据爬取需求定义好该聚焦网络爬虫爬取的目标及进行相关描述。
2.获取初始的URL。
3.根据初始的URL爬取页面,并获得新的URL。
4.从新的URL中过滤掉与爬取目标无关的链接
因为聚焦网络爬虫对网页的爬取是有目的性的,所以与目标无关的网页将会被过滤掉。同时,也需要将已爬取的URL地址存放到一个URL列表中,用于去重和判断爬取的进程。
5.将过滤后的链接放到URL队列中。
6.根据搜索算法,从URL队列中确定URL的优先级及下一步要爬取的URL地址
对聚焦网络爬虫来说,不同的爬取顺序可能导致爬虫的执行效率不同,因此需要依据搜索策略来确定下一步需要爬取哪些URL地址。
7.从下一步要爬取的URL地址中,读取新的URL,然后依据新的URL地址爬取网页,并重复上述爬取过程。满足系统中设置的停止条件时,或无法获取新的URL地址时,停止爬行。
增量式网络爬虫是指对已下载网页采取增量式更新并且只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。
网页按存在方式可以分为表层网页和深层网页。
表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主。
而深层网页则是指那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的、只有用户提交一些关键词才能获得的网页。
深层网络爬虫主要用于针对深层网络,其主要的体系结构包含6个基本功能模块:
爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器和两个爬虫内部数据结构(URL列表和LVS表)。其中,LVS(Label Value Set)表示标签和数值集合,用来表示填充表单的数据源。
在深度网络爬虫的爬取过程中,最重要的部分就是表单填写,包含基于领域知识的表单填写和基于网页结构分析的表单填写两种。
以上是“爬虫的实现原理是什么”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





