本篇内容介绍了“短⽂本聚类的问题有哪些”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!

搜索是用户明确表达需求的场景,百度搜索每天承接海量请求,query的表达多种多样。大规模短文本聚类系统,核心目的就是对以query为代表的短文本进行总结归纳,**精准高效地将含义相同表达不同的短文本,凝练成含义内聚表达清晰的“需求”。**这种方式不仅可以压缩短文本量级,还能更好的满足用户需求,帮助内容提供方,提供更好的内容。目前已经辅助了百度UGC产品的内容生产。
在这一节中,我们先介绍短文本聚类问题,并介绍常用聚类算法,最后分析聚类算法在搜索场景下的难点和挑战。
聚类是一种常用的无监督算法,按照某个距离度量方式把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。
一般来说,搜索query以短文本为主。从大量的短文本中,尽可能地将含义一致的所有文本,聚合在一起,形成一个**“需求簇”**,就是短文本聚类问题。
举例来说: 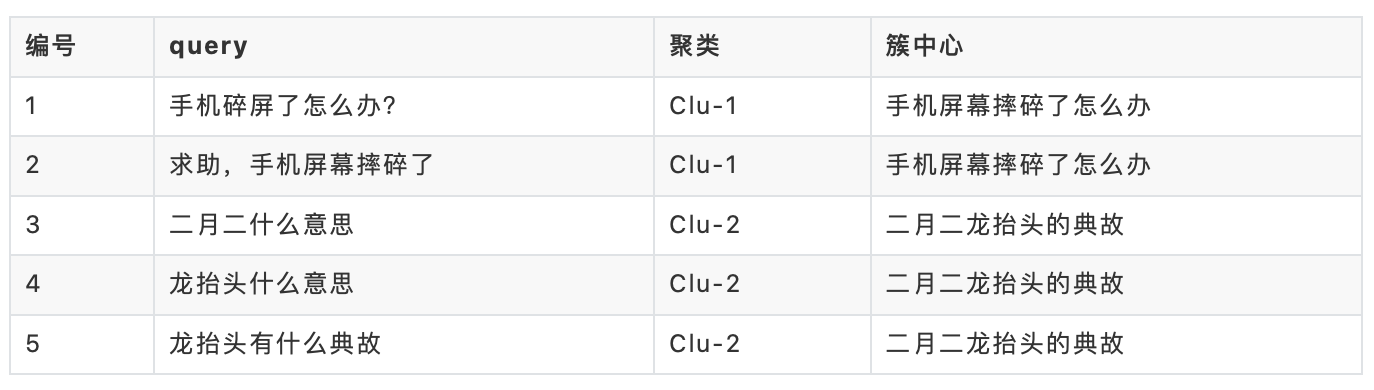
其中,query="⼿机碎屏了怎么办?" 和query=“求助,⼿机屏幕摔碎了”是相同的需求,可以聚合成为⼀个簇;query="⼆⽉⼆什么意思",query="⻰抬头什么意思" 和query="⻰抬头有什么典故"是相同的需求,可以聚合成为⼀个簇。
可以看出,搜索query场景下的短⽂本聚类问题,和常规聚类问题,有⼀个明显的区别:**“簇”的内涵相对集中,**也就是说,聚合完成后,簇的量级相对较⼤,同⼀个簇内的数据,距离较近。
在⽂本聚类领域,simhash是⼀种常⽤的局部敏感哈希算法,常常被⽤来作为搜索引擎中的⽹⻚去重算法。它⼒图以较⾼的概率,将相似的⽂档映射为相同的哈希值,从⽽起到聚类(去重)的⽬的。
simhash算法⼀般会将⽂档进⾏分词处理,并给出每个词的权重,再为每个词计算⼀个哈希值,将所有词的哈希值加权对位求和后,再采⽤对位⼆值化降维,产出最终⽂档的哈希值。过程中使⽤了词的重要性加权,所以重要的词对最终⽂档哈希值的影响会更⼤,⽽不重要的词,对最终⽂档哈希值的影响就会更⼩,从⽽相似的⽂档,产⽣相同哈希值的可能性就会更⼤。
在⻓⽂档聚类(去重)领域,simhash是⼀种⾼效的算法,但是,对短⽂本聚类⽽⾔,由于⽂本⻓度⼤幅度减少,simhash的有效性⼤⼤降低了,不能保证产出结果的准确性。
另⼀种常⽤的⽂本聚类⽅式,⾸先会将⽂本向量化,再采⽤常规聚类⽅法进⾏聚类。其中,⽂本向量化的⽅式很多,从早期的tf-idf,到⽅便快捷的word2vec,甚⾄是采⽤bert,ernie等预训练模型产出的⽂本向量,都可以作为⽂本的向量化表征。⼀般来说,向量化⽅法会暗含分布式假设,产出的文本向量,可以在⼀定程度上解决同义词的问题。
聚类的⽅式也多种多样,例如常⽤的kmeans,层级化聚簇,single-pass等。特别需要注意的是,在设计聚类算法的距离度量时,需要特别考虑向量化的⽅式,针对不同的向量化⽅式,设计不同的距离度量。
这类算法存在三点问题:
1、以kmeans为代表的聚类算法,存在超参数“簇数量”,只能借助经验和辅助指标进⾏判定; 2、对短⽂本聚类问题,簇的数量往往特别⼤,会导致聚类算法性能严重下降; 3、聚类结果准确率受向量化和聚类算法双重影响,难以表达数据的细粒度差异。
尽管短⽂本聚类算法,在业界具有较多应⽤场景,但是在研究领域,它仍是⼀个相对⼩众的分⽀,主要采⽤改进⽂本向量化表示的⽅案,例如句⼦向量被设计成词向量加权矩阵的第⼀主成分,⽽⾮直接加权;例如采⽤聚簇引导的向量迭代的⽅式,改进向量化表示,例如SIF+Aut。但不论是哪种改进,都会增加较⼤的计算开销,在⼯业界并不现实。

我们⾯对的问题是⼤规模短⽂本聚类,它还包含3个隐含的限制条件:
1、聚类结果的准确性要求⾮常严格; 2、短⽂本数量规模⾮常⼤; 3、数据产出时效要求高;
不难看出,常规算法在运算效率和准确性方面,很难同时满足上述三个要求;而工业界并没有成熟框架,可以解决这个问题;学术界算法距离工业场景应用还有一定距离;我们需要一种新的思路来解决问题。
在设计算法时,需要重点考虑如下问题:
1、数据量级⼤,系统吞吐高:搜索query的量级是不言而喻的,对于亿级别数据,进行高效计算,非常考验算法设计能力和工程架构能力;
2、聚类算法准确率要求高:首先,聚类算法是无监督算法,采用向量空间上的距离度量,衡量聚类结果的聚集程度,本质上并没有准确率的概念;但是,在搜索query场景下,聚类算法就有了明确的衡量指标:通过统一的文本相似性评估标准,可以后验评估出在同一个簇中,结果是否相似, 在不同的簇中,数据是否不相似,从而可以衡量出聚类准确率。这为短文本聚类算法戴上了“紧箍咒”:并不是任意聚类算法都适用,需要考虑和文本相似度结合更紧密的聚类算法。
“结合更紧密”是从向量空间中距离的定义来考虑的,例如,由相似度模型给出的相似度度量,并不一定是向量空间上“距离”。具体来说,向量空间上的一个定义良好的“距离”,需要满足三角不等式:distance(A,B)+distance(B,C)>=distance(A,C), 但是,对于相似度,similarity(A,B)+similarity(B,C)与similarity(A,C)并不一定有稳定的数量关系。因此,不能直接使用聚类模型,只能将相似度作为“场外指导”,实现相似度指导下的聚类算法。这导致一般的聚类算法不能直接用于短文本聚类。
3、文本相似度要求精度高,耗时短:文本相似度是一个场景依赖问题,对于同样的query对,在不同的场景下,可能有截然不同的判定结果。在搜索场景下,对相似度的精度要求非常高,往往一字之差,就是完全不同的需求,因此模型需要能够精确捕获文本的细粒度差异;另一方面,希望尽可能地将相同需求的query聚合成为一个簇,减少漏召回的情况;也就是说,**对于短文本聚类问题,对文本相似度的准确率和召回率都有很高要求;**除此之外,为了适应大规模的调用,文本相似度服务需要具有响应时长短、易扩展等特点。
4、文本表征复杂:文本表征指的是通过某种方式将文本转化为语义向量,用于后续文本聚类。文本向量的产出方式多种多样,例如在simhash中,采用加权hash函数表达文本信息;还可以用word2vec词向量加权产生文本的向量信息。除此之外,短文本的类别,关键词等信息,也是文本表征的重要组成部分;在文本向量化时,需要重点考虑如何在向量空间中体现相似度。文本表征是一项重要且基础的算法,选择不同的文本表征,决定了不同的相似度度量方式,直接影响聚类模型选型,间接影响最终结果。
5、误差的发现和修复:从文本表征到文本相似度,再到聚类算法,每一步都会积累误差,从而影响最终结果。对于大规模文本聚类,这个问题尤为明显,也是容易被忽略的环节。
考虑到以上难点,我们采⽤了多级拆分,逐个击破的总体思路。
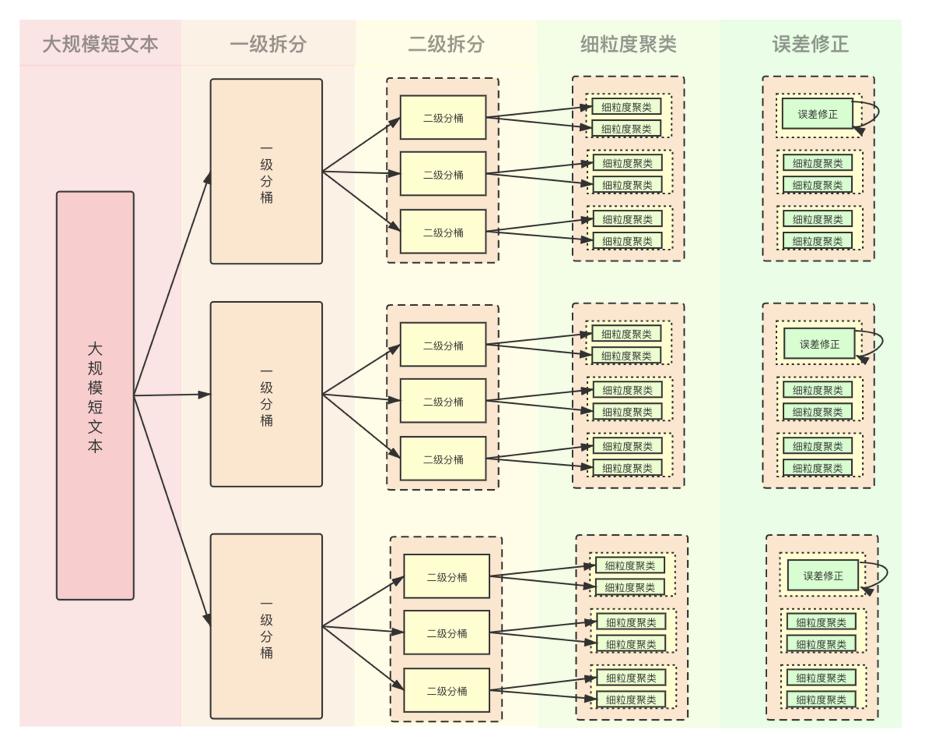
图1:⼤规模短⽂本聚类的总体思路
1.我们先将⼤规模短⽂本,进⾏多级拆分,基本保证相同含义的query,⼤概率进⼊同⼀个分桶中:
1.1⼀级拆分:需要保证拆分项在语义层⾯,含义互斥,也就是相同含义的query,必须进⼊相同的桶中;
1.2⼆级拆分:⼀级拆分后,每个桶内的query量级依然很⼤,还需要进⾏⼆级拆分,保证后续计算量级可控;
2.对同⼀个桶内的query进⾏精细化语义聚合,将含义相同的query,合并为⼀个簇;
3.对于同⼀个⼀级分桶中的语义簇,进⾏误差校验,将需要合并的簇合并;
说明:
1.为什么要拆分?假设我们的query数量量级为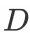 ,那么最差情况下,我们需要进⾏
,那么最差情况下,我们需要进⾏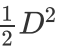 次相似度计算,才能完成⽂本聚类;然⽽,如果我们将数据进⾏拆分,并且以较⾼的概率保证拆分互斥,
次相似度计算,才能完成⽂本聚类;然⽽,如果我们将数据进⾏拆分,并且以较⾼的概率保证拆分互斥,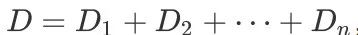 ,那么只需要进⾏
,那么只需要进⾏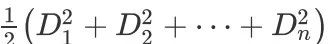 次相似度计算,量级是远⼩于的
次相似度计算,量级是远⼩于的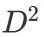 ;
;
2.为什么需要多级拆分?如果把原始数据平级拆分的较细,就会降低相似度调用次数;但是平级拆分的越细,就越不能保证语义互斥,这会导致需要进行误差校验的数量激增;如果我们采用多级拆分,保证顶部拆分的准确率,就会减少误差校验的数据量;
3.如何进⾏语义聚簇?数据拆分后,需要在每个桶内,进⾏⽂本聚类,这也是整个⽅案最核⼼的地⽅;⽬前,有三种办法可以解决:
3.1 基于⽂本字⾯的检索聚类:虽然分到同⼀个桶中的数据量已经⼤⼤减少了,但是如果两两进⾏相似度计算,数据量级依然很⼤;我们发现,常规的关键词搜索,可以保证召回⼤部分相似的query,只需要为召回的query计算相关性即可。
3.2 基于⽂本表征的聚类:虽然通过关键词搜索,可以覆盖⼤部分的相似query,但是召回并不全, 为了解决同义问题、句式变换等导致的关键词召回不全的问题,我们使用了基于文本表征的召回方式:将向量化后的query,进行细粒度的聚类,只需要对同一类中的query计算相似度即可;
3.3 基于⽂本表征的检索聚类:考虑细粒度的聚类算法控制力较弱,还可以引入向量检索,通过文本向量召回的方式,解决召回不全的问题。
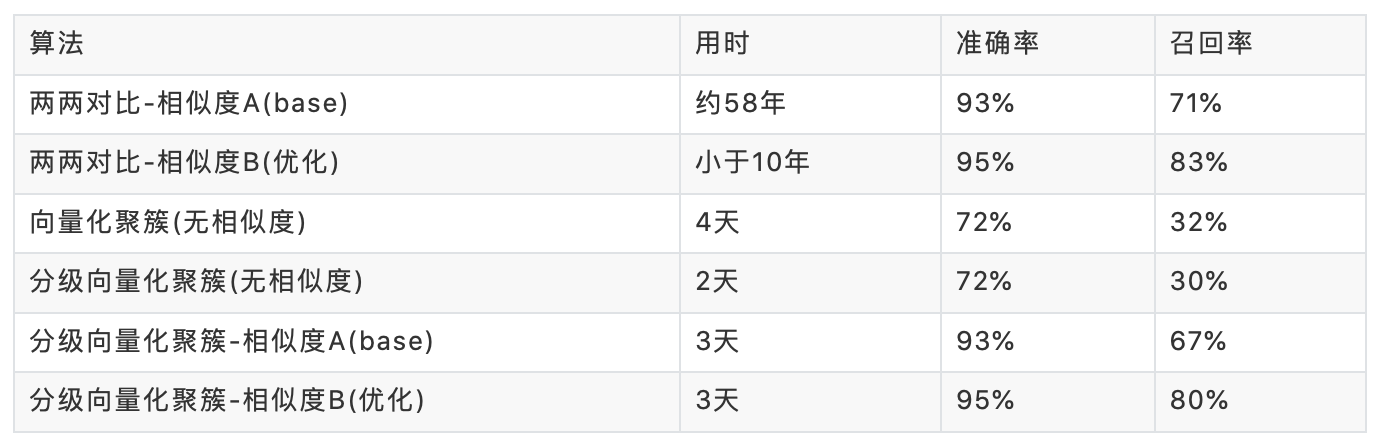
1. 解决了数据量级大,要求耗时短的问题:当前流程可以通过将数据进行二级拆分,可以把大规模数据,拆分为较小的数据块,分配给不同的计算单元进行计算,从而减少耗时;我们进行过估计,在1亿数据上,传统两两对比的方式,计算需要耗时58年;而采用分层的方式, 只需要4天;虽然采用分级向量化聚簇(无相似度)的方式,可以将耗时降低为2天, 但是准确率和召回率较低;
2. 优化相似度, 提高相似度服务计算性能:我们对短文本相似度进行了定制性优化,多实例部署,相似度服务的吞吐能力得到了100倍的提升;
3. 聚类算法准确率高:引入误差修正机制,整体短文本聚类算法准确率从93%提升到了95%,召回率从71%提升到了80%;
基于以上分析, 对计算性能和计算效果进行折中, 我们采用了分级向量化聚簇+优化后的相似度作为最后的方案;
以上是我们经过⼀段时间的探索后,总结出的⼤规模短⽂本聚类问题的解决⽅案。在过程中,我们进⾏了两个⼤版本的迭代。
在解决这个问题的初期,我们面对两种技术方案:一种是探索适合短文本的表征,将问题转化为特殊的向量聚类的问题,例如simhash;另一种是将数据集合进行拆分,减少数据规模,加速相似度计算,解决聚类问题;经过分析后,我们认为方案一,在选择合适的文本表征上,没有可以指导优化方向的中间指标,很难迭代优化,因此,明确了将数据集合进行拆分的思路。
首先,我们根据query的分类和其他业务要求,将query进行一级拆分,保证拆分结果语义互斥;
第二步,进行二级拆分:为了保证二级拆分后的同一个桶内,数据量级适中,便于进行精细化语义聚合,我们采用了层级化分桶的方式:
1. 对query计算高级语义特征,并进行二值化操作,产出一个256维度的由0、1组成的向量
2. 首先取前50维向量,进行hash粗聚;如果簇内的数量超过一定数量,则对其中的query,扩展维度到100维,重新进行hash粗聚,直到维数达到256或者簇内数量少于一定数量
第三步,对每一个桶内的query,进行精细化语义聚合,将含义相似的query,合并为一个簇中。
我们可以看出,由于采用了数据拆分的思路,将数据分桶后,进行精细化语义聚类时,每个分桶之间的数据语义互斥,只需要在每个桶内进行语义聚合, 就可以产出数据了。这种方式便于并行化计算,对缩短计算耗时有很大贡献。
在过程中, 我们也发现,一些需要改进的地方:
1. 聚类结果的准确性强依赖于相似度模型,并且是细粒度相似度模型,如果使用粗粒度相似度模型,会导致误召回,因此需要一套可以区分细粒度相似程度的模型。
2. 使用层级化分桶进行二级拆分,并不一定能保证语义相似的数据进入一个桶中,层次化拆分使用的query向量表征,暗含了向量在语义表达上,具有随维度增加逐渐细化的特点,但是在产出query向量表征的过程中,并没有施加此导向,不能保证这个假设成立;在v2.0中我们改动了二级拆分的方式,克服了这个缺陷;
3. 缺少误差发现和修正机制:不论相似度准确率有多高,不论短文本的分类有多准,都会有误差;我们需要有机制可以发现和修正误差。
针对v1.0 发现的问题,我们做了三点改动:
引入细粒度相似度
短文本文本聚类的一个典型使用场景,是对搜索query进行语义级别的合并,将相同需求不同表达的query,合并为一个“需求”,因此对于相似query的认定,标准是较为严格的。已有的相似度模型,已经不能适用了。经过对query的详细分析,我们发现句法分析,短语搭配等特征,能够对提升相似度模型的准确率和召回率有较大帮助,因此,我们自研了一套融合了句法分析,短语搭配和其他特征的相似度模型,取得了较好的收益。
在二级拆分中引入聚类模型
在v1.0 版本中,层次化分桶的准确率得不到保证,需要有一个更准确的二级拆分方式,达到数据分桶的目的。二级拆分只需要保证相似的短文本,大概率被分到同一个桶中,并不要求桶内任意两个短文本都是相似的,这样的设置非常适合采用向量化后聚类方法解决问题。一方面考虑到预训练模型的性能问题,我们采用了传统词向量加权的方式,产出短文本的词向量;通过kmeans聚类的方式,对一级桶的短文本进行聚类操作,从而保证了二级拆分的准确率。
这里可能会有疑问,为什么不使用向量召回的方式解决问题?其实,向量召回的本质是向量聚类,再辅以高效的向量查找,达到向量召回的目的。在二级拆分中,不需要进行向量查找,而且如果引入会增加额外的时间开销,因此我们并没有使用向量召回。
误差修正
在v1.0版本中,误差逐层累计且没有得到修正,为了克服这一点,我们在产出的最后一步,引入了误差修正操作。
主要存在两种形式的误差: 一种是聚类不全,应该聚合在一起的数据,没有聚合在一起,这类误差主要是由于多级拆分引起的,通过跨越层级的校验,可以解决这个问题;另一种误差是聚类不准,主要是由于相似度计算导致的。我们重点解决聚类不全的问题。
为了减少需要校验的数据量级,我们将误差检验的范围,限制在二级分桶内部。在二级分桶后,我们首先采用精细化语义聚合的方式,得到聚类结果。对处于同一个二级桶内的聚类中心,验证其相关性。如果相关性较高,则进一步验证后合并。
v2.0 的效果
v2.0上线后,能够在很短的时间内处理完成大规模短文本的精细化聚类,聚类准确率达到95%,召回率达到80%,已经服务于百度UGC业务线的内容生产。
持续优化
v2.0版本基本实现了大规模短文本精细化聚类的功能,但是仍有很多改动空间。例如聚类结果的持久化,重复计算问题,更高效的聚合算法等,后续我们也会持续优化,提供更高效稳定的算法支持。
“短⽂本聚类的问题有哪些”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





