еҰӮдҪ•жһ„е»әApache Flinkеә”з”Ё
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶеҰӮдҪ•жһ„е»әApache Flinkеә”з”ЁпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
1гҖҒејҖеҸ‘зҺҜеўғеҮҶеӨҮ
Flink еҸҜд»ҘиҝҗиЎҢеңЁ Linux, Max OS X, жҲ–иҖ…жҳҜ Windows дёҠгҖӮдёәдәҶејҖеҸ‘ Flink еә”з”ЁзЁӢеәҸпјҢеңЁжң¬ең°жңәеҷЁдёҠйңҖиҰҒжңү Java 8.x е’Ң maven зҺҜеўғгҖӮ
еҰӮжһңжңү Java 8 зҺҜеўғпјҢиҝҗиЎҢдёӢйқўзҡ„е‘Ҫд»Өдјҡиҫ“еҮәеҰӮдёӢзүҲжң¬дҝЎжҒҜпјҡ
$ java -version
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
еҰӮжһңжңү maven зҺҜеўғпјҢиҝҗиЎҢдёӢйқўзҡ„е‘Ҫд»Өдјҡиҫ“еҮәеҰӮдёӢзүҲжң¬дҝЎжҒҜпјҡ
$ mvn -version
Apache Maven 3.5.4 (1edded0938998edf8bf061f1ceb3cfdeccf443fe; 2018-06-18T02:33:14+08:00)
Maven home: /Users/wuchong/dev/maven
Java version: 1.8.0_65, vendor: Oracle Corporation, runtime: /Library/Java/JavaVirtualMachines/jdk1.8.0_65.jdk/Contents/Home/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "mac os x", version: "10.13.6", arch: "x86_64", family: "mac"
еҸҰеӨ–жҲ‘们жҺЁиҚҗдҪҝз”Ё ItelliJ IDEA пјҲзӨҫеҢәе…Қиҙ№зүҲе·ІеӨҹз”ЁпјүдҪңдёә Flink еә”з”ЁзЁӢеәҸзҡ„ејҖеҸ‘ IDEгҖӮEclipse иҷҪ然д№ҹеҸҜд»ҘпјҢдҪҶжҳҜ Eclipse еңЁ Scala е’Ң Java ж··еҗҲеһӢйЎ№зӣ®дёӢдјҡжңүдәӣе·ІзҹҘй—®йўҳпјҢжүҖд»ҘдёҚеӨӘжҺЁиҚҗ EclipseгҖӮдёӢдёҖз« иҠӮпјҢжҲ‘们дјҡд»Ӣз»ҚеҰӮдҪ•еҲӣе»әдёҖдёӘ Flink е·ҘзЁӢ并е°Ҷе…¶еҜје…Ҙ ItelliJ IDEAгҖӮ
2гҖҒзј–еҶҷ Flink зЁӢеәҸ
еҗҜеҠЁ IntelliJ IDEAпјҢйҖүжӢ© вҖңImport ProjectвҖқпјҲеҜје…ҘйЎ№зӣ®пјүпјҢйҖүжӢ© my-flink-project ж №зӣ®еҪ•дёӢзҡ„ pom.xmlгҖӮж №жҚ®еј•еҜјпјҢе®ҢжҲҗйЎ№зӣ®еҜје…ҘгҖӮ
еңЁ src/main/java/myflink дёӢеҲӣе»ә SocketWindowWordCount.java ж–Ү件пјҡ
package myflink;
public class SocketWindowWordCount {
public static void main(String[] args) throws Exception {
}
}зҺ°еңЁиҝҷзЁӢеәҸиҝҳеҫҲеҹәзЎҖпјҢжҲ‘们дјҡдёҖжӯҘжӯҘеҫҖйҮҢйқўеЎ«д»Јз ҒгҖӮжіЁж„ҸдёӢж–ҮдёӯжҲ‘们дёҚдјҡе°Ҷ import иҜӯеҸҘд№ҹеҶҷеҮәжқҘпјҢеӣ дёә IDE дјҡиҮӘеҠЁе°Ҷ他们添еҠ дёҠеҺ»гҖӮеңЁжң¬иҠӮжң«е°ҫпјҢжҲ‘дјҡе°Ҷе®Ңж•ҙзҡ„д»Јз Ғеұ•зӨәеҮәжқҘпјҢеҰӮжһңдҪ жғіи·іиҝҮдёӢйқўзҡ„жӯҘйӘӨпјҢеҸҜд»ҘзӣҙжҺҘе°ҶжңҖеҗҺзҡ„е®Ңж•ҙд»Јз ҒзІҳеҲ°зј–иҫ‘еҷЁдёӯгҖӮ
Flink зЁӢеәҸзҡ„第дёҖжӯҘжҳҜеҲӣе»әдёҖдёӘ StreamExecutionEnvironment гҖӮиҝҷжҳҜдёҖдёӘе…ҘеҸЈзұ»пјҢеҸҜд»Ҙз”ЁжқҘи®ҫзҪ®еҸӮж•°е’ҢеҲӣе»әж•°жҚ®жәҗд»ҘеҸҠжҸҗдәӨд»»еҠЎгҖӮжүҖд»Ҙи®©жҲ‘们жҠҠе®ғж·»еҠ еҲ° main еҮҪж•°дёӯпјҡ
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
дёӢдёҖжӯҘжҲ‘们е°ҶеҲӣе»әдёҖдёӘд»Һжң¬ең°з«ҜеҸЈеҸ· 9000 зҡ„ socket дёӯиҜ»еҸ–ж•°жҚ®зҡ„ж•°жҚ®жәҗпјҡ
DataStream text = env.socketTextStream("localhost", 9000, "\n");иҝҷеҲӣе»әдәҶдёҖдёӘеӯ—з¬ҰдёІзұ»еһӢзҡ„ DataStreamгҖӮDataStream жҳҜ Flink дёӯеҒҡжөҒеӨ„зҗҶзҡ„ж ёеҝғ APIпјҢдёҠйқўе®ҡд№үдәҶйқһеёёеӨҡеёёи§Ғзҡ„ж“ҚдҪңпјҲеҰӮпјҢиҝҮж»ӨгҖҒиҪ¬жҚўгҖҒиҒҡеҗҲгҖҒзӘ—еҸЈгҖҒе…іиҒ”зӯүпјүгҖӮеңЁжң¬зӨәдҫӢдёӯпјҢжҲ‘们ж„ҹе…ҙи¶Јзҡ„жҳҜжҜҸдёӘеҚ•иҜҚеңЁзү№е®ҡж—¶й—ҙзӘ—еҸЈдёӯеҮәзҺ°зҡ„ж¬Ўж•°пјҢжҜ”еҰӮиҜҙ5з§’зӘ—еҸЈгҖӮдёәжӯӨпјҢжҲ‘们йҰ–е…ҲиҰҒе°Ҷеӯ—з¬ҰдёІж•°жҚ®и§ЈжһҗжҲҗеҚ•иҜҚе’Ңж¬Ўж•°пјҲдҪҝз”ЁTuple2<String, Integer>иЎЁзӨәпјүпјҢ第дёҖдёӘеӯ—ж®өжҳҜеҚ•иҜҚпјҢ第дәҢдёӘеӯ—ж®өжҳҜж¬Ўж•°пјҢж¬Ўж•°еҲқе§ӢеҖјйғҪи®ҫзҪ®жҲҗдәҶ1гҖӮжҲ‘们е®һзҺ°дәҶдёҖдёӘ flatmap жқҘеҒҡи§Јжһҗзҡ„е·ҘдҪңпјҢеӣ дёәдёҖиЎҢж•°жҚ®дёӯеҸҜиғҪжңүеӨҡдёӘеҚ•иҜҚгҖӮ
DataStream> wordCounts = text
.flatMap(new FlatMapFunction>() {
@Override
public void flatMap(String value, Collector> out) {
for (String word : value.split("\\s")) {
out.collect(Tuple2.of(word, 1));
}
}
});жҺҘзқҖжҲ‘们е°Ҷж•°жҚ®жөҒжҢүз…§еҚ•иҜҚеӯ—ж®өпјҲеҚі0еҸ·зҙўеј•еӯ—ж®өпјүеҒҡеҲҶз»„пјҢиҝҷйҮҢеҸҜд»Ҙз®ҖеҚ•ең°дҪҝз”Ё keyBy(int index) ж–№жі•пјҢеҫ—еҲ°дёҖдёӘд»ҘеҚ•иҜҚдёә key зҡ„Tuple2<String, Integer>ж•°жҚ®жөҒгҖӮ然еҗҺжҲ‘们еҸҜд»ҘеңЁжөҒдёҠжҢҮе®ҡжғіиҰҒзҡ„зӘ—еҸЈпјҢе№¶ж №жҚ®зӘ—еҸЈдёӯзҡ„ж•°жҚ®и®Ўз®—з»“жһңгҖӮеңЁжҲ‘们зҡ„дҫӢеӯҗдёӯпјҢжҲ‘们жғіиҰҒжҜҸ5з§’иҒҡеҗҲдёҖж¬ЎеҚ•иҜҚж•°пјҢжҜҸдёӘзӘ—еҸЈйғҪжҳҜд»Һйӣ¶ејҖе§Ӣз»ҹи®Ўзҡ„пјҡ
DataStream> windowCounts = wordCounts
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
第дәҢдёӘи°ғз”Ёзҡ„ .timeWindow() жҢҮе®ҡжҲ‘们жғіиҰҒ5з§’зҡ„зҝ»ж»ҡзӘ—еҸЈпјҲTumbleпјүгҖӮ第дёүдёӘи°ғз”ЁдёәжҜҸдёӘkeyжҜҸдёӘзӘ—еҸЈжҢҮе®ҡдәҶsumиҒҡеҗҲеҮҪж•°пјҢеңЁжҲ‘们зҡ„дҫӢеӯҗдёӯжҳҜжҢүз…§ж¬Ўж•°еӯ—ж®өпјҲеҚі1еҸ·зҙўеј•еӯ—ж®өпјүзӣёеҠ гҖӮеҫ—еҲ°зҡ„з»“жһңж•°жҚ®жөҒпјҢе°ҶжҜҸ5з§’иҫ“еҮәдёҖж¬Ўиҝҷ5з§’еҶ…жҜҸдёӘеҚ•иҜҚеҮәзҺ°зҡ„ж¬Ўж•°гҖӮ
жңҖеҗҺдёҖ件дәӢе°ұжҳҜе°Ҷж•°жҚ®жөҒжү“еҚ°еҲ°жҺ§еҲ¶еҸ°пјҢ并ејҖе§Ӣжү§иЎҢпјҡ
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");жңҖеҗҺзҡ„ env.execute и°ғз”ЁжҳҜеҗҜеҠЁе®һйҷ…FlinkдҪңдёҡжүҖеҝ…йңҖзҡ„гҖӮжүҖжңүз®—еӯҗж“ҚдҪңпјҲдҫӢеҰӮеҲӣе»әжәҗгҖҒиҒҡеҗҲгҖҒжү“еҚ°пјүеҸӘжҳҜжһ„е»әдәҶеҶ…йғЁз®—еӯҗж“ҚдҪңзҡ„еӣҫеҪўгҖӮеҸӘжңүеңЁexecute()иў«и°ғз”Ёж—¶жүҚдјҡеңЁжҸҗдәӨеҲ°йӣҶзҫӨдёҠжҲ–жң¬ең°и®Ўз®—жңәдёҠжү§иЎҢгҖӮ
дёӢйқўжҳҜе®Ңж•ҙзҡ„д»Јз ҒпјҢйғЁеҲҶд»Јз Ғз»ҸиҝҮз®ҖеҢ–пјҲд»Јз ҒеңЁ GitHub дёҠд№ҹиғҪи®ҝй—®еҲ°пјүпјҡ
package myflink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class SocketWindowWordCount {
public static void main(String[] args) throws Exception {
// еҲӣе»ә execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// йҖҡиҝҮиҝһжҺҘ socket иҺ·еҸ–иҫ“е…Ҙж•°жҚ®пјҢиҝҷйҮҢиҝһжҺҘеҲ°жң¬ең°9876з«ҜеҸЈпјҢеҰӮжһң9876з«ҜеҸЈе·Іиў«еҚ з”ЁпјҢиҜ·жҚўдёҖдёӘз«ҜеҸЈ
DataStream<String> text = env.socketTextStream("localhost", 9876, "\n");
// и§Јжһҗж•°жҚ®пјҢжҢү word еҲҶз»„пјҢејҖзӘ—пјҢиҒҡеҗҲ
DataStream<Tuple2<String, Integer>> windowCounts = text
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
for (String word : value.split("\\s")) {
out.collect(Tuple2.of(word, 1));
}
}
})
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
// е°Ҷз»“жһңжү“еҚ°еҲ°жҺ§еҲ¶еҸ°пјҢжіЁж„ҸиҝҷйҮҢдҪҝз”Ёзҡ„жҳҜеҚ•зәҝзЁӢжү“еҚ°пјҢиҖҢйқһеӨҡзәҝзЁӢ
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
}3гҖҒиҝҗиЎҢзЁӢеәҸ
иҰҒиҝҗиЎҢзӨәдҫӢзЁӢеәҸпјҢйҰ–е…ҲжҲ‘们еңЁз»Ҳз«ҜеҗҜеҠЁ netcat иҺ·еҫ—иҫ“е…ҘжөҒпјҡ
nc -lk 9000
еҰӮжһңжҳҜ Windows е№іеҸ°пјҢеҸҜд»ҘйҖҡиҝҮ https://nmap.org/ncat/ е®үиЈ… ncat 然еҗҺиҝҗиЎҢпјҡ
ncat -lk 9000
然еҗҺзӣҙжҺҘиҝҗиЎҢSocketWindowWordCountзҡ„ main ж–№жі•гҖӮ
еҸӘйңҖиҰҒеңЁ netcat жҺ§еҲ¶еҸ°иҫ“е…ҘеҚ•иҜҚпјҢе°ұиғҪеңЁ SocketWindowWordCount зҡ„иҫ“еҮәжҺ§еҲ¶еҸ°зңӢеҲ°жҜҸдёӘеҚ•иҜҚзҡ„иҜҚйў‘з»ҹи®ЎгҖӮеҰӮжһңжғізңӢеҲ°еӨ§дәҺ1зҡ„и®Ўж•°пјҢиҜ·еңЁ5з§’еҶ…еҸҚеӨҚй”®е…ҘзӣёеҗҢзҡ„еҚ•иҜҚгҖӮ
жҲ‘иҝҷйҮҢеҶҷдәҶдёӘз®ҖеҚ•зҡ„ tcp_server.py жЁЎжӢҹдёҠиҝ°жүӢеҠЁ nc ж“ҚдҪңпјҢеӨ§е®¶еҸҜд»ҘжҢҒз»ӯи§ӮеҜҹ flink зӘ—еҸЈз»ҹи®Ўз»“жһңжӯЈзЎ®жҖ§пјҡ
import socket
import string
import random
import time
import datetime
import os
from collections import Counter
tcpServerSocket = socket.socket()
host, port = "localhost", 9876 # host = socket.gethostname()#иҺ·еҸ–жң¬ең°дё»жңәеҗҚ
tcpServerSocket.bind((host, port))
tcpServerSocket.listen(2) # д»ЈеҠһдәӢ件дёӯжҺ’йҳҹзӯүеҫ…connectзҡ„жңҖеӨ§ж•°зӣ®
def sleep_some_time(start_time):
end_time = datetime.datetime.now()
rest_time = 5 - (end_time-start_time).seconds
sleep_time = rest_time if 0 <= rest_time <= 5 else 0
time.sleep(sleep_time)
while True:
#sckжҳҜиҜҘconnectionдёҠеҸҜд»ҘеҸ‘йҖҒе’ҢжҺҘ收数жҚ®зҡ„ж–°еҘ—жҺҘеӯ—еҜ№иұЎ, addrжҳҜдёҺconnectionеҸҰдёҖз«Ҝзҡ„еҘ—жҺҘеӯ—з»‘е®ҡзҡ„ең°еқҖ
sck, addr = tcpServerSocket.accept()
print('е®ўжҲ·з«ҜиҝһжҺҘең°еқҖпјҡ', addr)
print_flag = 0
while 1:
start_time = datetime.datetime.now()
window_cycle_count = 1
ascii_lowercase_list = []
print_flag += 1
if print_flag % 2 == 0:
sck.send(("-------------------------------" + "\n").encode())
sleep_some_time(start_time)
continue
print(">>> " + start_time.strftime('%Y-%m-%d %H:%M:%S'))
while window_cycle_count < 6:
for _ in range(random.choice(range(6))):
ascii_lowercase = random.choice(string.ascii_lowercase[0:10])
sck.send((ascii_lowercase + "\n").encode())
ascii_lowercase_list.append(ascii_lowercase)
window_cycle_count += 1
print(Counter(ascii_lowercase_list))
sleep_some_time(start_time)
print("<<<<<< " + datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') + "\n")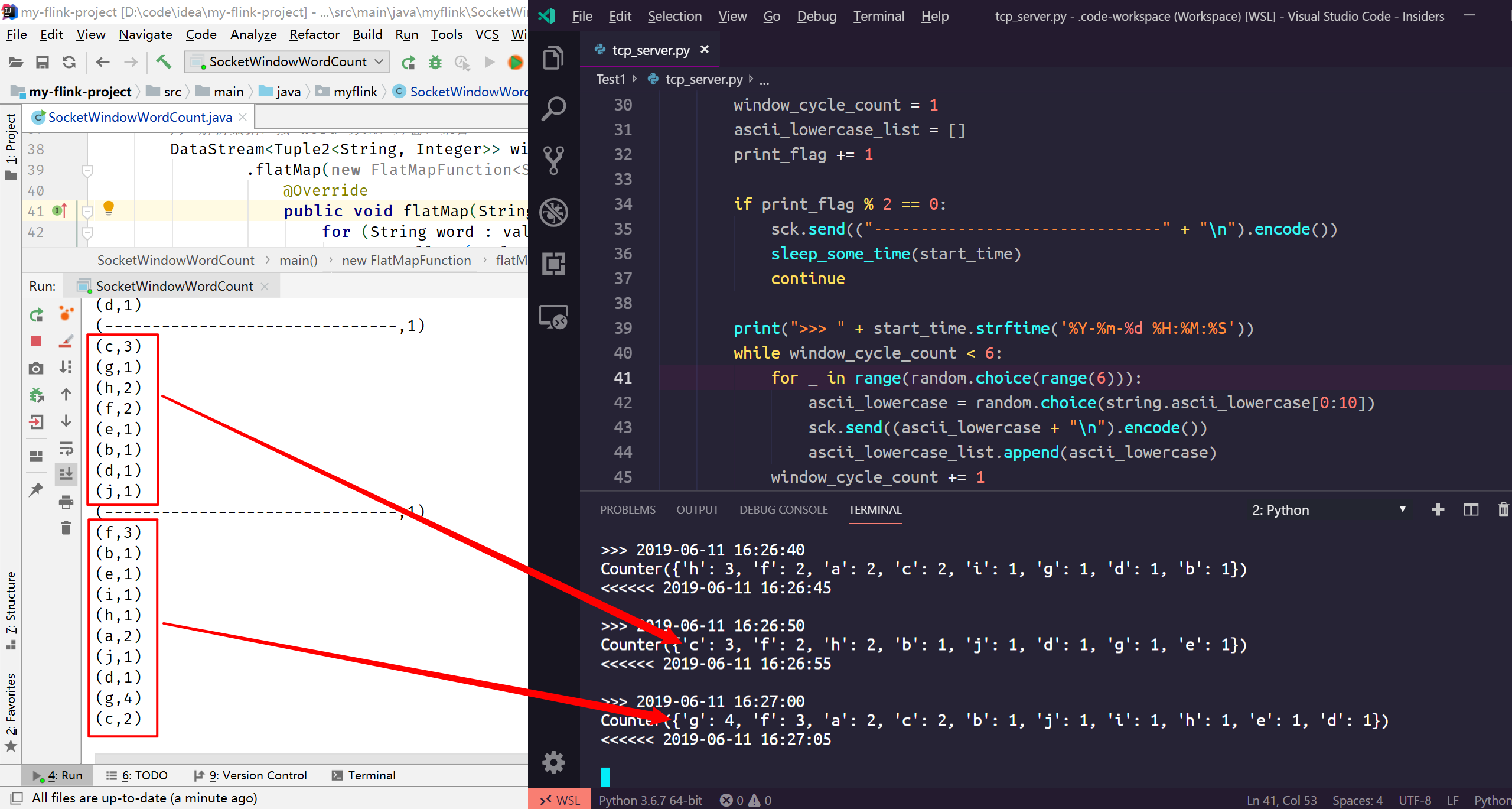
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңеҰӮдҪ•жһ„е»әApache Flinkеә”з”ЁвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !





