这篇文章的内容主要围绕Mahout、协同过滤和CF推荐算法基本概念及代码示例分析进行讲述,文章内容清晰易懂,条理清晰,非常适合新手学习,值得大家去阅读。感兴趣的朋友可以跟随小编一起阅读吧。希望大家通过这篇文章有所收获!
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
协同过滤一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目录作为推荐给你。当然其中有一个核心的问题:
如何确定一个用户是不是和你有相似的品位?
如何将邻居们的喜好组织成一个排序的目录?
协同过滤相对于集体智慧而言,它从一定程度上保留了个体的特征,就是你的品位偏好,所以它更多可以作为个性化推荐的算法思想。
Mahout提供了2个评估推荐器的指标,查准率和召回率(查全率),这两个指标是搜索引擎中经典的度量方法。
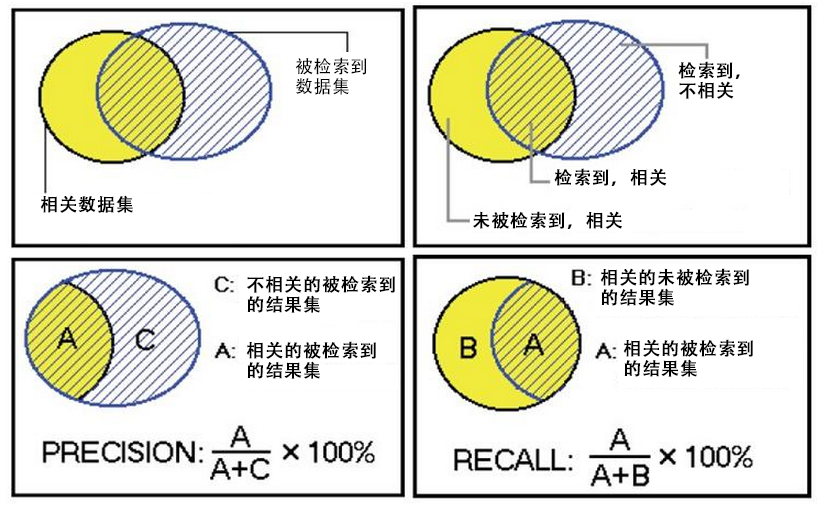
相关 不相关
检索到 A C
未检索到 B D
A:检索到的,相关的 (搜到的也想要的)
B:未检索到的,但是相关的 (没搜到,然而实际上想要的)
C:检索到的,但是不相关的 (搜到的但没用的)
D:未检索到的,也不相关的 (没搜到也没用的)
被检索到的越多越好,这是追求“查全率”,即A/(A+B),越大越好。
被检索到的,越相关的越多越好,不相关的越少越好,这是追求“查准率”,即A/(A+C),越大越好。
在大规模数据集合中,这两个指标是相互制约的。当希望索引出更多的数据的时候,查准率就会下降,当希望索引更准确的时候,会索引更少的数据
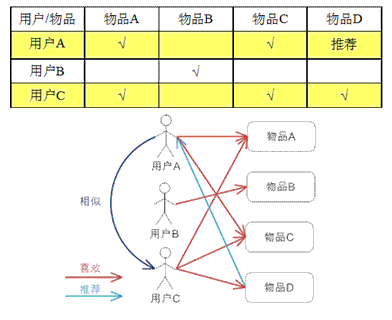
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。下图 给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
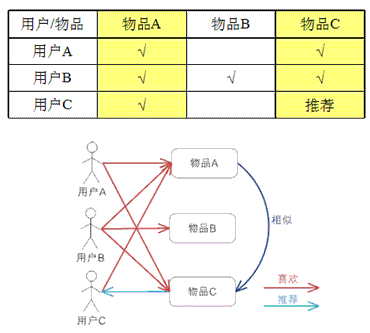
基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。下图 给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
基于物品的 CF 的基本原理
对于 User CF,推荐的原则是假设用户会喜欢那些和他有相同喜好的用户喜欢的东西,但如果一个用户没有相同喜好的朋友,那 User CF 的算法的效果就会很差,所以一个用户对的 CF 算法的适应度是和他有多少共同喜好用户成正比的。
Item CF 算法也有一个基本假设,就是用户会喜欢和他以前喜欢的东西相似的东西,那么我们可以计算一个用户喜欢的物品的自相似度。一个用户喜欢物品的自相似度大,就说明他喜欢的东西都是比较相似的,也就是说他比较符合 Item CF 方法的基本假设,那么他对 Item CF 的适应度自然比较好;反之,如果自相似度小,就说明这个用户的喜好习惯并不满足 Item CF 方法的基本假设,那么对于这种用户,用 Item CF 方法做出好的推荐的可能性非常低。
import java.io.File;
import java.util.List;
import org.apache.mahout.cf.taste.impl.common.FastByIDMap;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.impl.model.GenericDataModel;
import org.apache.mahout.cf.taste.impl.model.GenericPreference;
import org.apache.mahout.cf.taste.impl.model.GenericUserPreferenceArray;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.EuclideanDistanceSimilarity;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.model.PreferenceArray;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
public class RecommenderDemo {
public static void main(String[] args) throws Exception {
userBasedRecommender();
itemBasedRecommender();
CFDemo();
}
/**
* 基于用户相似度的推荐引擎
*
* @throws Exception
*/
public static void userBasedRecommender() throws Exception {
// step1 构建模型
DataModel model = new FileDataModel(new File("data.txt"));
// step2 计算相似度 (基于皮尔逊相关系数计算相似度)
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
// step3 查找k紧邻
UserNeighborhood neighborhood = new NearestNUserNeighborhood(2,
similarity, model);
// 构造推荐引擎
Recommender recommender = new GenericUserBasedRecommender(model,
neighborhood, similarity);
// 为用户1推荐两个ItemID
List<RecommendedItem> recommendations = recommender.recommend(1, 2);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
}
/**
* 基于内容的推荐引擎
*
* @throws Exception
*/
public static void itemBasedRecommender() throws Exception {
DataModel model = new FileDataModel(new File("data.txt"));
ItemSimilarity similarity = new PearsonCorrelationSimilarity(model);
Recommender recommender = new GenericItemBasedRecommender(model,
similarity);
List<RecommendedItem> recommendations = recommender.recommend(1, 1);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
}
/**
*
* @throws Exception
*/
public static void CFDemo() throws Exception {
// 创建dataModel
FastByIDMap<PreferenceArray> preferences = new FastByIDMap<PreferenceArray>();
// 用户1喜欢物品1、2、3
PreferenceArray userPref1 = new GenericUserPreferenceArray(3);
// userPref1.setUserID(1, 1);
// userPref1.setItemID(0, 1);
// userPref1.setValue(0, 5.0f);
// userPref1.setItemID(1, 2);
// userPref1.setValue(1, 3.0f);
// userPref1.setItemID(2, 3);
// userPref1.setValue(2, 2.5f);
userPref1.set(0, new GenericPreference(1, 1, 5.0f));
userPref1.set(1, new GenericPreference(1, 2, 3.0f));
userPref1.set(2, new GenericPreference(1, 3, 2.5f));
// 用户2喜欢物品1、2、3、4
PreferenceArray userPref2 = new GenericUserPreferenceArray(4);
userPref2.set(0, new GenericPreference(2, 1, 2.0f));
userPref2.set(1, new GenericPreference(2, 2, 2.5f));
userPref2.set(2, new GenericPreference(2, 3, 5.0f));
userPref2.set(3, new GenericPreference(2, 4, 2.0f));
// 用户3喜欢物品1、4、5、7
PreferenceArray userPref3 = new GenericUserPreferenceArray(4);
userPref3.set(0, new GenericPreference(3, 1, 2.5f));
userPref3.set(1, new GenericPreference(3, 4, 4.0f));
userPref3.set(2, new GenericPreference(3, 5, 4.5f));
userPref3.set(3, new GenericPreference(3, 7, 5.0f));
// 用户4喜欢物品1、3、4、6
PreferenceArray userPref4 = new GenericUserPreferenceArray(4);
userPref4.set(0, new GenericPreference(4, 1, 5.0f));
userPref4.set(1, new GenericPreference(4, 3, 3.0f));
userPref4.set(2, new GenericPreference(4, 4, 4.5f));
userPref4.set(3, new GenericPreference(4, 6, 4.0f));
// 用户5喜欢物品1、2、3、4、5、6
PreferenceArray userPref5 = new GenericUserPreferenceArray(6);
userPref5.set(0, new GenericPreference(5, 1, 4.0f));
userPref5.set(1, new GenericPreference(5, 2, 3.0f));
userPref5.set(2, new GenericPreference(5, 3, 2.0f));
userPref5.set(3, new GenericPreference(5, 4, 4.0f));
userPref5.set(4, new GenericPreference(5, 5, 3.5f));
userPref5.set(5, new GenericPreference(5, 6, 4.0f));
preferences.put(1, userPref1);
preferences.put(2, userPref2);
preferences.put(3, userPref3);
preferences.put(4, userPref4);
preferences.put(5, userPref5);
//基于程序构建的dataModel
DataModel model = new GenericDataModel(preferences);
//基于文件的dataModel
// DataModel model = new FileDataModel(new File("testCF.csv"));
//基于用户的、欧氏距离、最近邻的协同过滤算法
UserSimilarity similarity = new EuclideanDistanceSimilarity(model);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(2,
similarity, model);
Recommender recommender = new GenericUserBasedRecommender(model,
neighborhood, similarity);
//打印用户4的推荐信息
List<RecommendedItem> recommendations = recommender.recommend(4, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
//打印所有用户的推荐信息
LongPrimitiveIterator iter = model.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List<RecommendedItem> list = recommender.recommend(uid, 3);
System.out.printf("uid:%s", uid);
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(),
ritem.getValue());
}
System.out.println();
}
//基于内容的、欧氏距离、最近邻的协同过滤算法
ItemSimilarity similarity1 = new EuclideanDistanceSimilarity(model);
Recommender recommender1 = new GenericItemBasedRecommender(model,similarity1);
LongPrimitiveIterator iter1 = model.getUserIDs();
while (iter1.hasNext()) {
long uid = iter1.nextLong();
List<RecommendedItem> list = recommender1.recommend(uid, 3);
System.out.printf("uid:%s", uid);
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(),
ritem.getValue());
}
System.out.println();
}
}
}
data.txt内容
1,101,5
1,102,3
1,103,2.5
2,101,2
2,102,2.5
2,103,5
2,104,2
3,101,2.5
3,104,4
3,105,4.5
3,107,5
4,101,5
4,103,3
4,104,4.5
4,106,4
5,101,4
5,102,3
5,103,2
5,104,4
5,105,3.5
5,106,4
感谢你的阅读,相信你对“Mahout、协同过滤和CF推荐算法基本概念及代码示例分析”这一问题有一定的了解,快去动手实践吧,如果想了解更多相关知识点,可以关注亿速云网站!小编会继续为大家带来更好的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





