一、基本概念与模型
1、大数据
结构化数据:有严格定义
半结构化数据:html、json、xml等,有结构但没有约束的文档
非结构化数据:没有元数据,比如说日志类文档
搜索引擎:ELK,搜索组件、索引组件组成,用来搜索数据,保存在分布式存储中
爬虫程序:搜索的是半结构化和非结构化数据
需要+高效存储能力、高效的分析处理平台
2、Hadoop
Hadoop是用Java语言开发的,是对谷歌公司这3篇论文开发出来的山寨版
2003年:The Google File System -->HDFS
2004年:MapReduce:Simplified Data Processing On Large Cluster -->MapReduce
2006年:BigTable:A Distributed Storage System for Structure Data -->Hbase
HDFS+MapReduce=Hadoop
HDFS:Hadoop的分布式文件系统,有中心节点式存储数据
MapReduce:面向大数据并行处理的计算模型、框架和平台
HBase:Hadoop的database数据库
官方网址:hadoop.apache.org
二、HDFS
1、HDFS问题
存在名称节点:NN:NameNode和第二名称节点SNN:Secondary NameNode
NN数据存储在内存中,由于数据在内存中变化十分快,硬盘存储跟不上内存的变化速度,所以通过类似于数据库事务日志的机制,向硬盘存储映像文件,在此过程中 ,追加日志不断被清空不断被写入,所以当NN服务器挂了,至少不会丢失太多文件,但是由于文件元数据在宕机后可能有不统一的情况造成文件校验,数据量过大会花费大量时间。
SNN为辅助名称节点,NN的追加日志放到了共享存储上,使SNN能访问,当NN宕机后,SNN会可以根据追加日志及时启动,至少优化了只有一个NN时候的文件校验时间。
在Hadoop2或者HBase2版本之后,可以将数据共享存放到zookeeper,几个节点通过zookeeper同时获取到视图,很好的解决了刚才的问题,也能够进行高可用设置了。
2、HDFS数据节点工作原理:
存在数据节点:DN:DataNode
当有数据存储时,HDFS文件系统除了存储DN,会再寻找两个数据节点进行存储作为副本,数据节点之间以链式相连,即有第一份才有第二份,有第二份才有第三份,每次存储结束后节点会向前数据点报告,向元数据块或者服务器报告自己的状态和数据块列表。当某一点数据丢失,此时链式数据会重新启动,补足丢失的数据块。
三、MapReduce
1、JobTracker:作业追踪器
每一个负责运行作业的节点,在MapReduce里叫任务追踪器,TaskTracker
2、每一个节点都要运行两类进程:
DataNode:负责存储或者删除数据等数据管理操作
TaskTracker:负责完成队列处理,属于Hadoop集群
3、程序特点
传统程序方案:程序在哪,数据就加载在哪
Hadoop方案:数据在哪,程序就在哪里跑
4、Hadoop分布式运行处理框架
任务提交可能会同时由N个人提交N个作业,每个人的作业不一定运行在所有节点上,有可能是在一部分节点上,甚至可能是一个节点上,为了能够限制一个节点上不要接入过多的任务,所以我们通过task slot,任务槽,来确定一个节点最多只能运行多少份任务
5、函数式编程:MapReduce参考了这种运行机制
Lisp,ML函数式编程语言:高阶函数
map,fold
map:把一个任务映射为多个任务,把一个函数当作为一个参数,并将其应用于列表中的
所有元素,会生成一个结果列表,即可映射为多个函数。
map(f())
fold:不断地把得到的结果折叠到函数上,接收两个参数:函数,初始值。
fold(g(),init):首先结合init初始值,通过函数g()得到g(init)的结果,然后将得到的结果g(init)在第二轮将作为初始值,通过函数g()得到g(g(init))的结果,以此类推最后会得到一个最终结果。
6、MapReduce过程
<1>mapper:每一个mapper就是每一个实例,每一个mapper处理完会生成一个列表,相当于map函数的过程,mapper接收数据如果是键值数据则直接使用,如果不是键值数据会先转换为键值数据
<2>reducer:当所有mapper运行完以后才会进行reducer,相当于fold函数的过程,reducer可能不止一个,reducer只处理键值型数据,接收到的数据做折叠
<3>reducer在折叠后的数据依旧是键值型数据,折叠过程叫做shuttle and sort,此过程十分重要
便于理解:同济一本书每个单词出现的次数:
mapper:每100页一个单位,比如说5 mappers,用于拆分成为单词,比如说this 1,is 1,this 1,how 1,单词逐个拆分,mapper处理后的为k-v型数据
reducer:reducer只处理键值型数据,将拆分出来的单词传递进reducer中进行统计处理与排序,将键相同的数据发往同一个reducer中,最后的结果this 500,is 200等等,结果依旧为kv型数据
shuffle and sort:接收mapper后,reducer将单词出现的次数进行键值数据统计计算的过程叫做shuffle and sort
7、Hadoop数据图
Hadoop只提供了数据存储平台,任何作业、任何数据程序处理必须由Hadoop开发人员写MapReduce程序调用才可供使用,mapper的具体任务是什么,reducer用什么,都取决于开发人员的定义是什么。
(1)partitioner:分区器,具备决定将mapper键值通过shuffle and sort过程发送给哪个reducer的功能
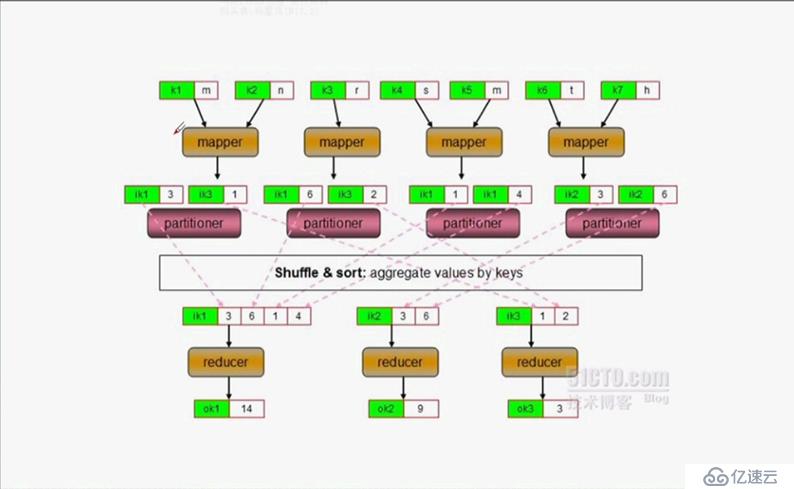
(2)combiner:如果mapper产生的键值数据中的键相同,那么将合并键,否则不合并,分散发送,同样由hadoop开发人员开发。其输入键和输出键必须保证一致。
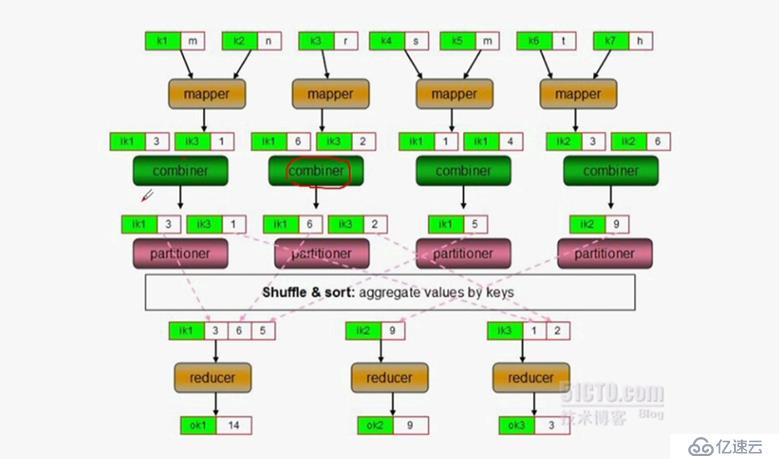
(3)多个reduce时:
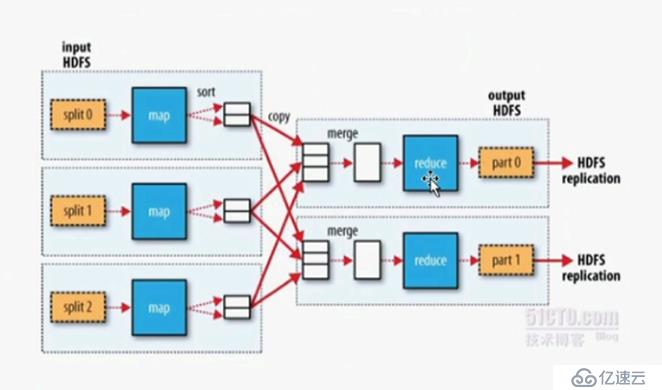
sort:每一个map在本地排序叫做sort
(4)单个reduce时:
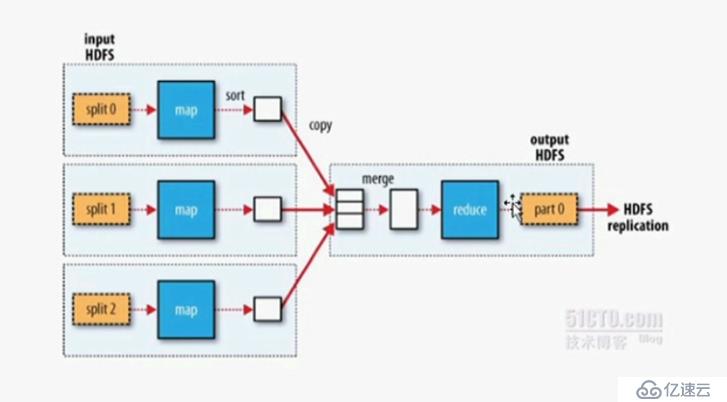
(5)shuffle and sort阶段:
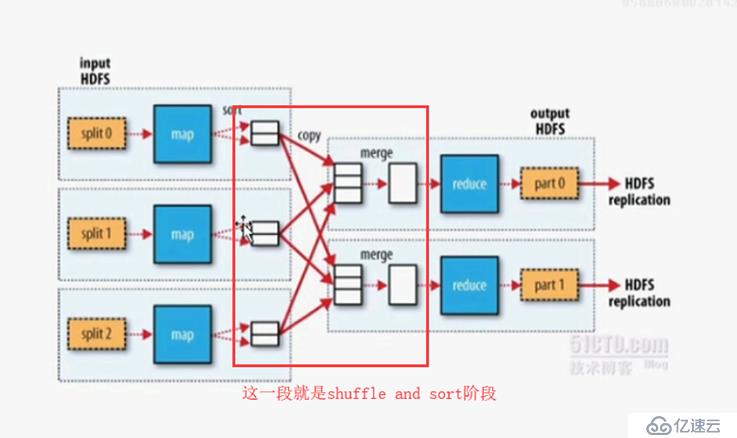
(6)作业提交请求过程:

(7)JobTracker内部结构
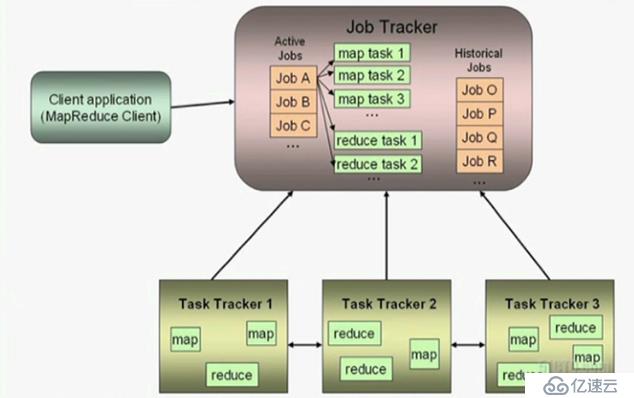
作用:作业调度、管理监控等等,所以运行时JobTracker会非常繁忙,它由此也成为了性能瓶颈,不过在MRv2版本后,作业调度、管理和监控功能被切割
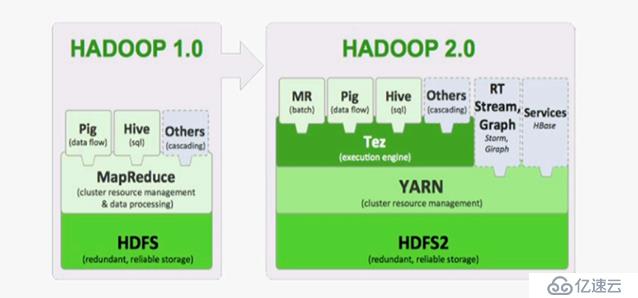
(8)版本更迭
MRv1(Hadoop2) --> MRv2(Hadoop2)
MRv1:集群资源管理器、数据处理程序
MRv2:
YARN:集群资源管理器
MRv2:数据处理程序
Tez:执行引擎
MR:批处理作业
RT Stream Graph:实时流式图处理,图状算法数据结构
(9)第二代hadoop资源任务运行流程
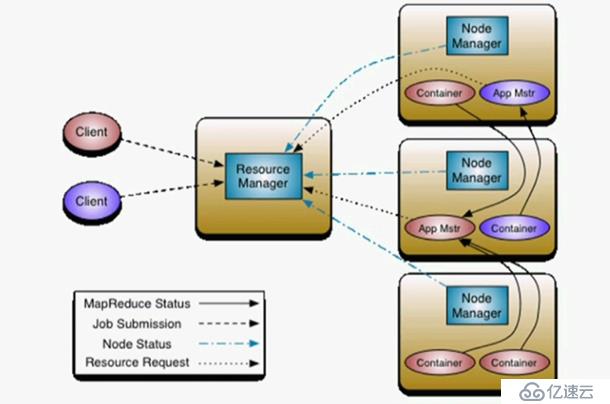
mapreduce把 资源管理和任务运行二者隔离开了,程序运行由自己的Application Master负责,而资源分配由Resource Manager进行。所以当一个客户端提交一个任务时,Resource Manager会询问每一个Node Manager有没有空闲的容器来运行程序。如果有,它去找有的这个节点,来启动这个主控进程Application Master。然后App Mstr向Resource Manager申请资源任务,Resource Manager分配好资源任务后会告诉App Mstr,之后App Mstr可以使用contrainer来运行作业了。
每一个container在运行过程中都会将反馈自己的作业任务给App Mstr,当container中有任务结束了,App Mstr也会报告给Resource Manager,Resource Manager会将资源收回来
RM:Resource Manager
NM:Node Manager
AM:Application Manager
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





