这篇文章给大家分享的是有关Hive有多少种存储格式的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
hive文件存储格式
1.textfile
textfile为默认格式
存储方式:行存储
磁盘开销大 数据解析开销大
压缩的text文件 hive无法进行合并和拆分
2.sequencefile
二进制文件,以<key,value>的形式序列化到文件中
存储方式:行存储
可分割 压缩
一般选择block压缩
优势是文件和hadoop api中的mapfile是相互兼容的。
3.rcfile
存储方式:数据按行分块 每块按照列存储
压缩快 快速列存取
读记录尽量涉及到的block最少
读取需要的列只需要读取每个row group 的头部定义。
读取全量数据的操作 性能可能比sequencefile没有明显的优势
4.orc
存储方式:数据按行分块 每块按照列存储
压缩快 快速列存取
效率比rcfile高,是rcfile的改良版本
5.自定义格式
用户可以通过实现inputformat和 outputformat来自定义输入输出格式。
总结:
textfile 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高
sequencefile 存储空间消耗最大,压缩的文件可以分割和合并 查询效率高,需要通过text文件转化来加载
rcfile 存储空间最小,查询的效率最高 ,需要通过text文件转化来加载,加载的速度最低
个人建议:text,seqfile能不用就尽量不要用 最好是选择orc
If you do not have an existing file to use, begin by creating one.
To create an RCFile, SequenceFile, or Text File table:
In the impala-shell interpreter, issue a command similar to:
create table rcfile_table (column_specs) stored as rcfile; create table sequencefile_table (column_specs) stored as sequencefile; create table textfile_table (column_specs) stored as textfile; -- If the STORED AS clause is omitted, the default is a comma-delimited TEXTFILE. create table default_table (column_specs);
Because Impala can query some kinds of tables that it cannot currently write to, after creating tables of certain file formats, you might use the Hive shell to load the data. See Understanding File Formats for details.
You may want to enable compression on existing tables. Enabling compression provides performance gains in most cases and is supported for RCFile and SequenceFile tables. For example, to enable Snappy compression, you would specify the following additional settings when loading data through the Hive shell:
hive> SET hive.exec.compress.output=true; hive> SET mapred.max.split.size=256000000; hive> SET mapred.output.compression.type=BLOCK; hive> SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec; hive> insert overwrite table NEW_TABLE select * from OLD_TABLE;
If you are converting partitioned tables, you must complete additional steps. In such a case, specify additional settings similar to the following:
hive> create table NEW_TABLE (YOUR COLS) partitioned by (PARTITION COLS) stored as NEW_FORMAT; hive> SET hive.exec.dynamic.partition.mode=nonstrict; hive> SET hive.exec.dynamic.partition=true; hive> insert overwrite table NEW_TABLE partition(COMMA SEPARATED PARTITION COLS) select * from OLD_TABLE;
Remember that Hive does not require that you specify a source format for it. Consider the case of converting a table with two partition columns called "year" and "month" to a Snappy compressed SequenceFile. Combining the components outlined previously to complete this table conversion, you would specify settings similar to the following:
hive> create table TBL_SEQ (int_col int, string_col string) stored as SEQUENCEFILE; hive> SET hive.exec.compress.output=true; hive> SET mapred.max.split.size=256000000; hive> SET mapred.output.compression.type=BLOCK; hive> SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec; hive> SET hive.exec.dynamic.partition.mode=nonstrict; hive> SET hive.exec.dynamic.partition=true; hive> insert overwrite table TBL_SEQ select * from TBL;
To complete a similar process for a table that includes partitions, you would specify settings similar to the following:
hive> create table TBL_SEQ (int_col int, string_col string) partitioned by (year int) stored as SEQUENCEFILE; hive> SET hive.exec.compress.output=true; hive> SET mapred.max.split.size=256000000; hive> SET mapred.output.compression.type=BLOCK; hive> SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec; hive> SET hive.exec.dynamic.partition.mode=nonstrict; hive> SET hive.exec.dynamic.partition=true; hive> insert overwrite table TBL_SEQ partition(year) select * from TBL;
Note:
The compression type is specified in the following phrase:
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
You could elect to specify alternative codecs such as GzipCodec here.
Hive的三种文件格式:TEXTFILE、SEQUENCEFILE、RCFILE中,TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的,RCFILE是基于行列混合的思想,先按行把数据划分成N个row group,在row group中对每个列分别进行存储。另:Hive能支持自定义格式,详情见:Hive文件存储格式
基于HDFS的行存储具备快速数据加载和动态负载的高适应能力,因为行存储保证了相同记录的所有域都在同一个集群节点。但是它不太满足快速的查询响应时间的要求,因为当查询仅仅针对所有列中的 少数几列时,它就不能跳过不需要的列,直接定位到所需列;同时在存储空间利用上,它也存在一些瓶颈,由于数据表中包含不同类型,不同数据值的列,行存储不 易获得一个较高的压缩比。RCFILE是基于SEQUENCEFILE实现的列存储格式。除了满足快速数据加载和动态负载高适应的需求外,也解决了SEQUENCEFILE的一些瓶颈。
下面对这几种几个作一个简单的介绍:
TextFile:
Hive默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2、Snappy等使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
SequenceFile:
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。
SequenceFile的文件结构图:
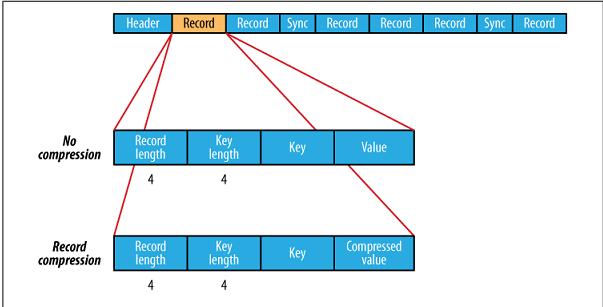
Header通用头文件格式:
| SEQ | 3BYTE |
| Nun | 1byte数字 |
| keyClassName | |
| ValueClassName | |
| compression | (boolean)指明了在文件中是否启用压缩 |
| blockCompression | (boolean,指明是否是block压缩) |
| compression | codec |
| Metadata | 文件元数据 |
| Sync | 头文件结束标志 |
Block-Compressed SequenceFile格式
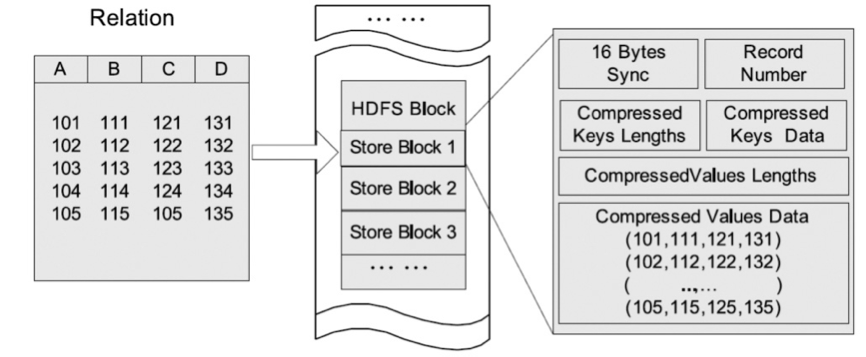
基于Hadoop系统行存储结构的优点在于快速数据加载和动态负载的高适应能力,这是因为行存储保证了相同记录的所有域都在同一个集群节点,即同一个 HDFS块。不过,行存储的缺点也是显而易见的,例如它不能支持快速查询处理,因为当查询仅仅针对多列表中的少数几列时,它不能跳过不必要的列读取;此 外,由于混合着不同数据值的列,行存储不易获得一个极高的压缩比,即空间利用率不易大幅提高。
列存储
HDFS块内列存储的例子
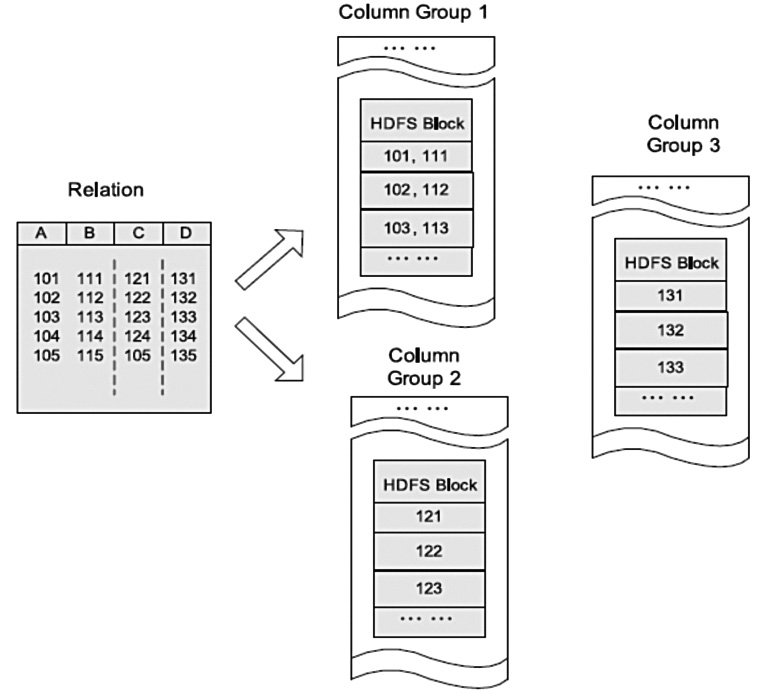
在HDFS上按照列组存储表格的例子。在这个例子中,列A和列B存储在同一列组,而列C和列D分别存储在单独的列组。查询时列存储能够避免读不必要的列, 并且压缩一个列中的相似数据能够达到较高的压缩比。然而,由于元组重构的较高开销,它并不能提供基于Hadoop系统的快速查询处理。列存储不能保证同一 记录的所有域都存储在同一集群节点,行存储的例子中,记录的4个域存储在位于不同节点的3个HDFS块中。因此,记录的重构将导致通过集群节点网络的大 量数据传输。尽管预先分组后,多个列在一起能够减少开销,但是对于高度动态的负载模式,它并不具备很好的适应性。
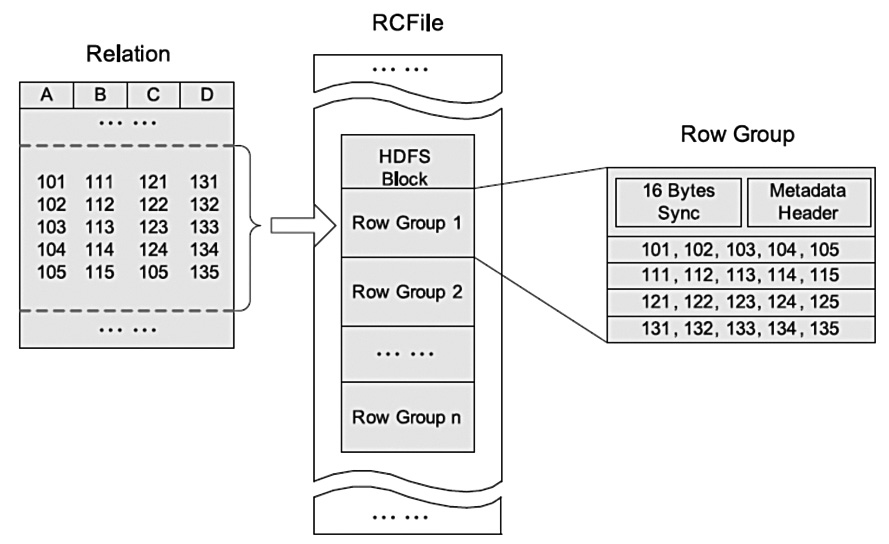
RCFile结合行存储查询的快速和列存储节省空间的特点:首先,RCFile保证同一行的数据位于同一节点,因此元组重构的开销很低;其次,像列存储一样,RCFile能够利用列维度的数据压缩,并且能跳过不必要的列读取。
HDFS块内RCFile方式存储的例子:
数据测试
源表数据记录数:67236221
第一步:创建三种文件类型的表,建表语法参考Hive文件存储格式
Sql代码
--TextFile
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
INSERT OVERWRITE table hzr_test_text_table PARTITION(product='xxx',dt='2013-04-22')
SELECT xxx,xxx.... FROM xxxtable WHERE product='xxx' AND dt='2013-04-22';
--SquenceFile
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
set io.seqfile.compression.type=BLOCK;
INSERT OVERWRITE table hzr_test_sequence_table PARTITION(product='xxx',dt='2013-04-22')
SELECT xxx,xxx.... FROM xxxtable WHERE product='xxx' AND dt='2013-04-22';
--RCFile
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
INSERT OVERWRITE table hzr_test_rcfile_table PARTITION(product='xxx',dt='2013-04-22')
SELECT xxx,xxx.... FROM xxxtable WHERE product='xxx' AND dt='2013-04-22';
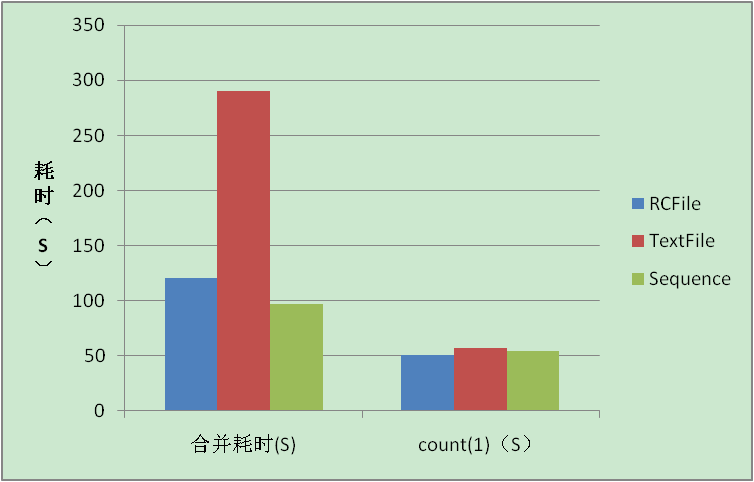
第二步:测试insert overwrite table tablename select.... 耗时,存储空间
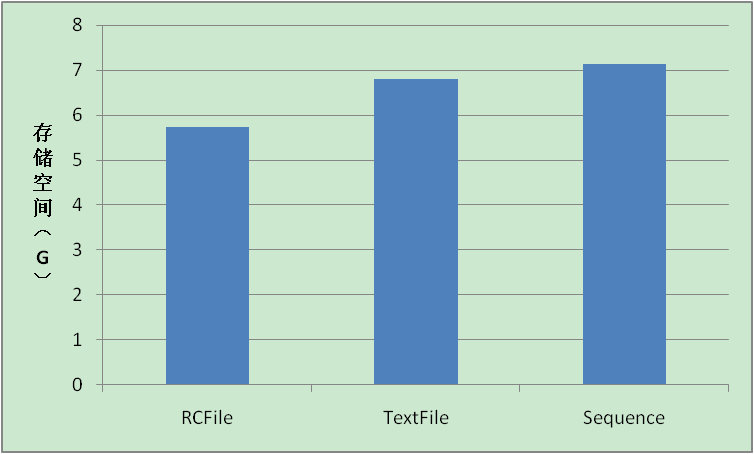
| 类型 | insert耗时(S) | 存储空间(G) |
Sequence | 97.291 | 7.13G |
RCFile | 120.901 | 5.73G |
TextFile | 290.517 | 6.80G |
insert耗时、count(1)耗时比较:
第三步:查询响应时间
测试一
Sql代码
方案一,测试整行记录的查询效率:
select * from hzr_test_sequence_table where game='XXX' ;
select * from hzr_test_rcfile_table where game='XXX' ;
select * from hzr_test_text_table where game='XXX' ;
方案二,测试特定列的查询效率:
select game,game_server from hzr_test_sequence_table where game ='XXX';
select game,game_server from hzr_test_rcfile_table where game ='XXX';
select game,game_server from hzr_test_text_table where game ='XXX';
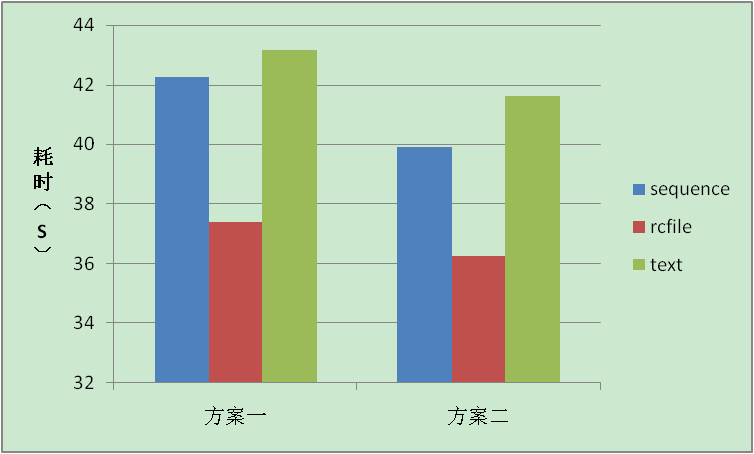
文件格式 | 查询整行记录耗时(S) | 查询特定列记录耗时(S) |
sequence | 42.241 | 39.918 |
rcfile | 37.395 | 36.248 |
text | 43.164 | 41.632 |
方案耗时对比:
测试二:
本测试目的是验证RCFILE的数据读取方式和Lazy解压方式是否有性能优势。数据读取方式只读取元数据和相关的列,节省IO;Lazy解压方式只解压相关的列数据,对不满足where条件的查询数据不进行解压,IO和效率都有优势。
方案一:
记录数:698020
Sql代码
insert overwrite local directory 'XXX/XXXX' select game,game_server from hzr_test_xxx_table where game ='XXX';
方案二:
记录数:67236221
Sql代码
insert overwrite local directory 'xxx/xxxx' select game,game_server from hzr_test_xxx_table;
方案三:
记录数:
Sql代码
insert overwrite local directory 'xxx/xxx'
select game from hzr_xxx_rcfile_table;
| 文件类型 | 方案一 | 方案二 | 方案三 |
| TextFile | 54.895 | 69.428 | 167.667 |
| SequenceFile | 137.096 | 77.03 | 123.667 |
| RCFile | 44.28 | 57.037 | 89.9 |
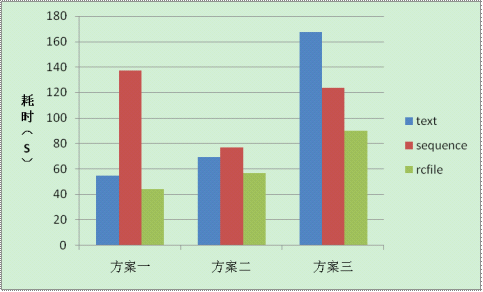
上图表现反应在大小数据集上,RCFILE的查询效率高于SEQUENCEFILE,在特定字段数据读取时,RCFILE的查询效率依然优于SEQUENCEFILE。
感谢各位的阅读!关于“Hive有多少种存储格式”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





