MapReducer工作流程图: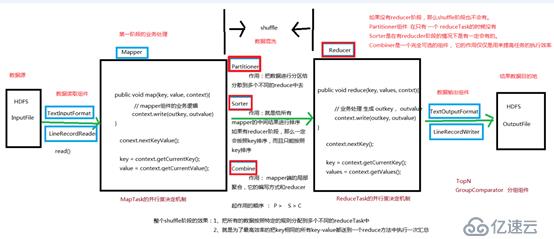
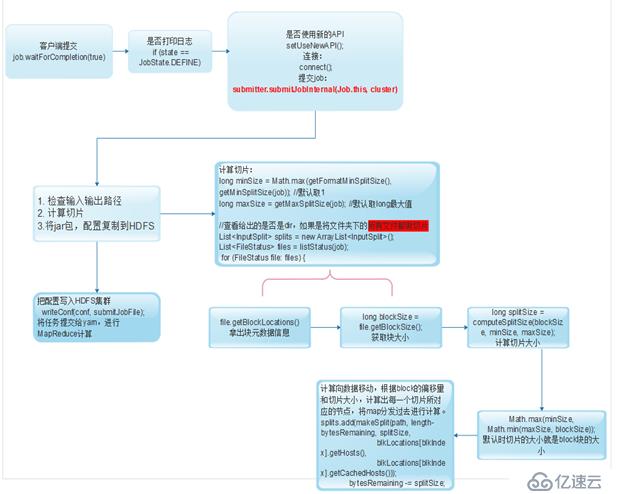
解释:
- 判断是否打印日志
- 判断是否使用新的API,检查连接
- 在检查连接时,检查输入输出路径,计算切片,将jar、配置文件复制到HDFS
- 计算切片时,计算最小切片数(默认为1,可自定义)和最大切片数(默认是long的最大值,可以自定义)
- 查看给定的是否是文件,如果是否目录计算目录下所有文件的切片
- 通过block大小和最小切片数、最大切片数计算出切片大小
- 过切片大小,计算出map的数量以及分发到的节点
- 提交job给yarn,进行MapReduce计算
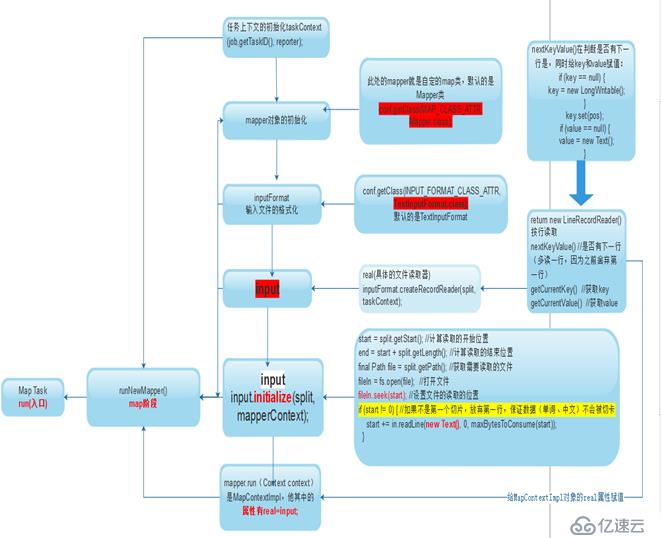
解释:
- 首先Map Task任务,调用run()方法,run()方法会经过以下几个阶段
- 初始化taskcontext对象
- 对mapper对象的初始化,此处包括一个默认值的判断,如果没有自定义mapper类,默认用系统的Mapper
- 对文件输入的格式化,此处包括一个默认值的判断,如果没有自定义inputFormat类,默认用系统的TextinputFormat
- 创建input对象,创建具体的文件读取类,通过lineReader(),默认每次迭代读取一行,此处实现一个迭代的判断的nextKeyVaule(),并在nextKeyVaule实现时初始化key和value
- Input初始化:计算打开位置,读取文件内容,(放弃第一行)
- 调用mapper的run方法循环读取,直到末尾,多读一行,start放弃第一行的数据被上一个切片读到,注意这里的run方法中就会调用我们编写的Mapper类中的setup、map、cleanup方法
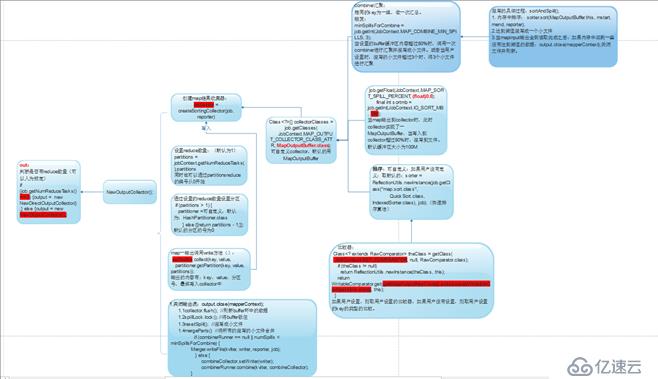
解释:
- 由newOutCollector创建output对象
- newOutCollector中需要准备collector和partitions计算reduce数量,会将map端输出的K,V,P(分区号)写入collector中
- 在准备collector实际上是准备MpaOutputBuffer,这是一特别复杂的过程,这里向大致的解释一下,就是先将收集的KV,P写入一个环形的缓冲区,然后在经过排序和分区将数据写入到文件中。(具体过程会在下面的shuffle中讲解)
- 最后mapOut结束之后,会调用close方法关闭output,在关闭时,会将剩余在buffer环的数据缓冲出去,并且将所有一些的小文件进行排序然后合并成一个大文件。
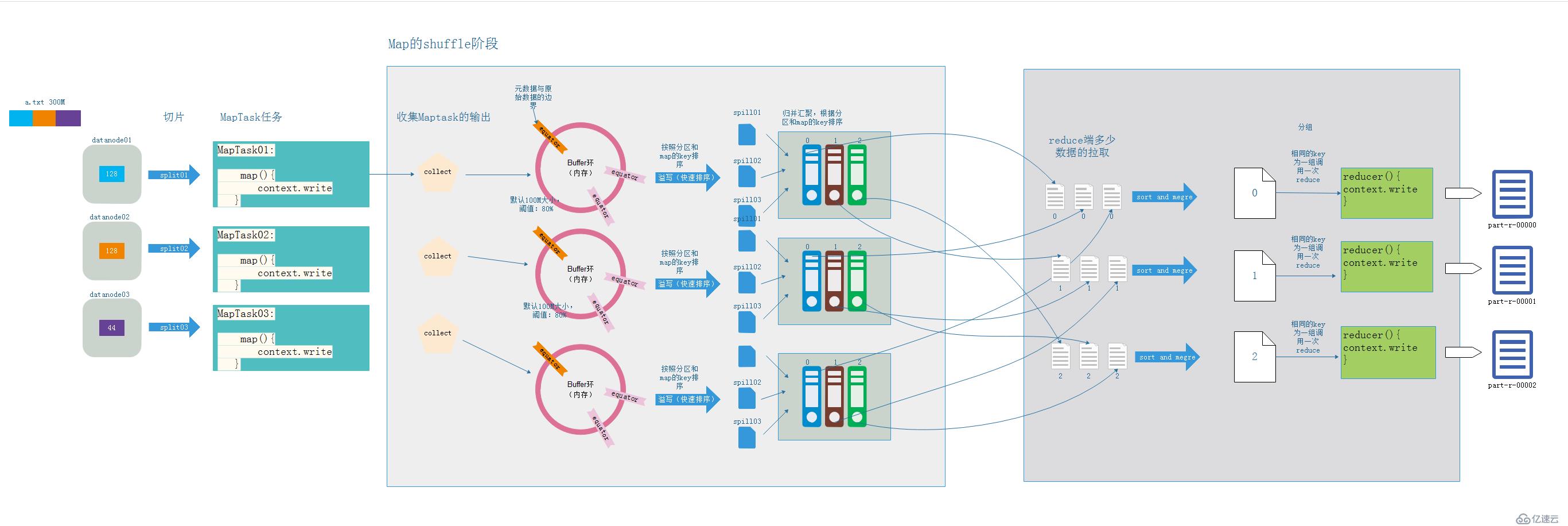
过程介绍:
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





