今天就跟大家聊聊有关怎样分析Debezium MySQL模块设计,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
注:本文不会着重分析MySQL binlog格式结构和解析过程,而在于debezium的架构设计。
Debezium is an open source distributed platform for change data capture.
这句话引用自debezium官网,可以看到,debezium的野心还是很大的,把自己定义为一个通用的CDC平台,事实上,也确实如此,尤其是从0.8版本以来,开发者将大量精力投入到PostgreSQL模块的开发,一方面引入SQL Server, Oracle, Db2, Cassandra等数据库的支持,另一方面适配了Pulsar,Amazon Kineis,Google Pub/Sub等消息引擎,并且逐步重构,解耦和具体数据库的绑定以及具体消息系统的依赖,向统一架构和云原生靠拢。
事实上,早期的Debezium是和Kafka Connect框架紧耦合的,Debezium是Kafka Connect的一个Source Plugin,并且主要适配MySQL,稍带了MongoDB。
目前Debezium最新版是1.2,1.3已经进入beta阶段。其实MySQL模块在0.8版本已经基本定下来了,后面的变动只有0.9合入了DBZ-175,这是一个在线加表特性,仅作为内部实验特性,并没有在文档上提及。我个人认为这个设计十分精彩,会在本文有篇幅专门讨论。在后续的开发中,同为早期的MongoDB被彻底重构,但MySQL模块还是保持原来的样子。
Rebase MySQL connector to common framework used by the other connectors.
这个已经在Roadmap上挂了有段儿时间了,但可以预见到,短期内还不会有什么动作。很大一部分原因是,MySQL模块的代码中有大量的针对MySQL和Kafka Connect缺陷的额外处理,还有像DBZ-175这种统一架构还不支持的特性,另外由于MySQL的广泛使用,多年来社区发现和修复了大量的场景下的bug,把一个久经验证的模块架构推倒是一件风险很大的事情。
后续的分析仅仅针对MySQL模块的架构和代码,基本上不会涉及新的统一架构。
上文提到,Debezium最初设计成一个Kafka Connect 的Source Plugin,目前开发者虽致力于将其与Kafka Connect解耦,但当前的代码实现还未变动。下图引自Debeizum官方文档,可以看到一个Debezium在一个完整CDC系统中的位置。
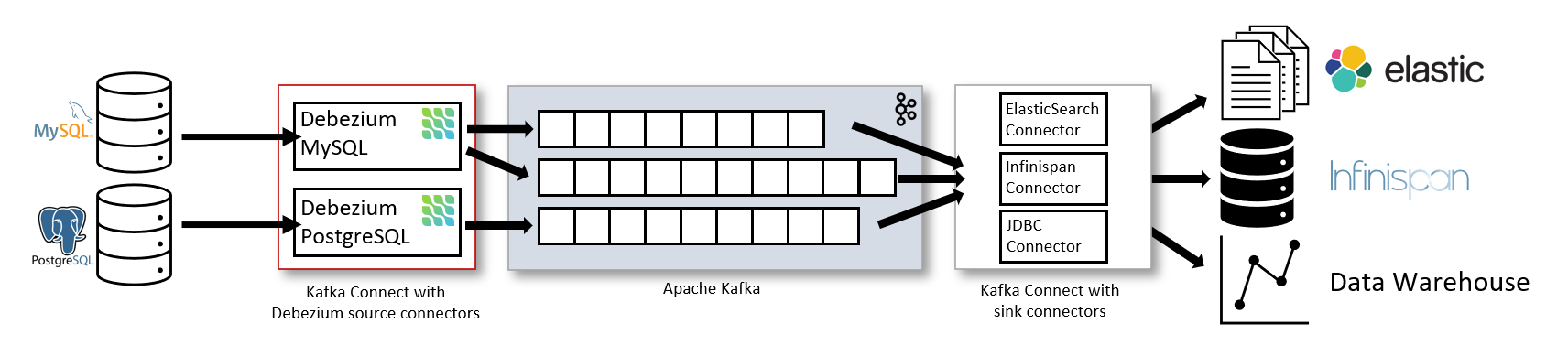
Kafka Connect 为Source Plugin提供了一系列的编程接口,最主要的就是要实现SourceTask的poll方法,其返回List<SourceRecord>将会被以最少一次语义的方式投递至Kafka。如果你想了解更多Kafka Connect的细节,请参阅我的另一篇文章:https://www.jianshu.com/p/538b2f0a7462
public abstract class SourceTask implements Task {
...
public abstract List<SourceRecord> poll() throws InterruptedException;
...
}Reader体系构成了MySQL模块中代码的主线,我们的分析从Reader开始。
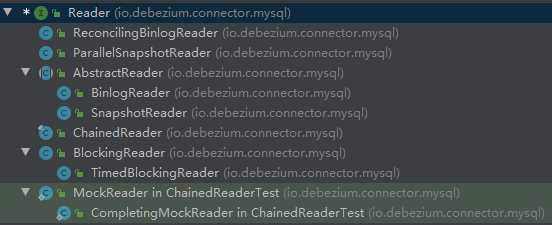
这里是Reader的整个继承树,我们先暂时忽略ParallelSnapshotReader,ReconcilingBinlogReader,他们是DBZ-175引入的东西。
从名字上应该可以看出,真正主要的是SnapshotReader和BinlogReader,分别实现了对MySQL数据的全量读取和增量读取,他们继承于AbstractReader,里面封装了共用逻辑,下图是AbstractReader的内部设计。

可以看到,AbstractReader在实现时,并没有直接将enqueue喂进来的record投递进Kafka,而是通过一个内存阻塞队列BlockingQueue进行了解耦,这种设计有诸多好处:
职责解耦
如上的图中,在喂入BlockingQueue之前,要根据条件判断是否接受该record;在向Kafka投递record之前,判断task的running状态。这样把同类的功能限定在特定的位置。
线程隔离
BlockingQueue是一个线程安全的阻塞队列,通过BlockingQueue实现的生产者消费者模型,是可以跑在不同的线程里的,这样避免局部的阻塞带来的整体的干扰。如上图中的右侧,消费者会定期判断running标志位,若running被stop信号置为了false,可以立刻停止整个task,而不会因MySQL IO阻塞延迟相应。
Single与Batch的互相转化
Enqueue record是单条的投递record,drain_to是批量的消费records。这个用法也可以反过来,实现batch到single的转化。
还剩下两个ChainedReader和TimedBlockingReader。
ChainedReader顾名思义,会把几个Reader包装起来,串行执行。
TimedBlockingReader就是简单的sleep一段时间,它的存在是为了应对Kafka Connect rebalance的设计缺陷,在上文中我的另一篇文章中有提到。
如果你搭建过MySQL的主从同步,因该知道,建立从库时,需要先导出全量数据(MySQL 8.0.x好像已经有了更便捷的方法),然后记录binlog的位置,把全量数据导入从库后,从binlog位置继续增量同步,已保持数据的一致性。
可能你还知道阿里开源的另一个MySQL CDC工具canal,他只负责stream过程,并没有处理snapshot过程,这也是debezium相较于canal的一个优势。
对于Debezium来说,基本沿用了官方搭建从库的这一思路,让我们看下官方文档描述的详细步骤。(如果没有额外说明,后面的讨论仅针对Innodb引擎)
Grabs a global read lock that blocks writes by other database clients. The snapshot itself does not prevent other clients from applying DDL which might interfere with the connector’s attempt to read the binlog position and table schemas. The global read lock is kept while the binlog position is read before released in a later step.
Starts a transaction with repeatable read semantics to ensure that all subsequent reads within the transaction are done against the consistent snapshot.
Reads the current binlog position.
Reads the schema of the databases and tables allowed by the connector’s configuration.
Releases the global read lock. This now allows other database clients to write to the database.
Writes the DDL changes to the schema change topic, including all necessary DROP… and CREATE… DDL statements. This happens if applicable.
Scans the database tables and generates CREATE events on the relevant table-specific Kafka topics for each row.
Commits the transaction.
Records the completed snapshot in the connector offsets.
Debezium把这个过程分解成了9步,看上去好像比我们想的要复杂些。
在Debezium目前版本的实现中,这9步是单线程串行的,其中主要的耗时就在第7步,这一步其实就是使用最朴素的方式,通过jdbc使用select * from table [where ...]来实现的读取全量数据,如果很多千万级甚至更大的表,这一步的耗时是很长的。其实这一步是可以并行化的,在第1步中,已经获取了全局锁,在全局锁释放前,是可以开多个连接,并行的实现全量数据的拉去,极大的提升效率。
另外snapshot整个过程如果失败,是无法恢复的,毕竟事务已经丢了,无法再读取当时的快照,来保证数据的一致性。
Snapshot过程时间长和中断不可恢复,再加上Kafka Connect 粗暴的rebalance策略,正是早期使用debezium的一大痛点。TimedBlockingReader的引入正是为了在一定程度上缓解这个问题。
ChainedReader ├── TimedBlockReader ├── SnapshotReader └── BinlogReader
当准备一次性提交多个同步任务时,因为每次任务提交都会触发一次rebalance,在SnapshotReader和BinlogReader前插入一个TimedBlockReader,确保同步任务提交后不会立刻执行,等多个任务都提交完成时,集群稳定下来,才会开始并发执行。
特别的,snapshot和stream过程都是可选的,你也可以像canal一样只从当前时刻开始监听binlog,捕获stream数据,具体配置请参考官方文档。
下面我们关注一下stream过程,也就是binlog解析过程。(做数据同步binlog必须设为row模式)
相信能读到这里的大多数同学都执行过以下命令,就是用MySQL官方的binlog工具解析binlog文件内容。仔细看,你会发现,这里面有库名和表名,有每个字段的值,却没有字段名,换句话说,binlog里不包含schema信息!
mysqlbinlog --no-defaults --base64-output=decode-rows -vvv ~/Downloads/mysql-bin.001192 | less
#190810 12:00:20 server id 206195699 end_log_pos 8624 CRC32 0x46912d80 GTID last_committed=12 sequence_number=13 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '5358e6dc-d161-11e8-8a6c-7cd30ac4dc44:25115781'/*!*/;
# at 8624
#190810 12:00:20 server id 206195699 end_log_pos 8687 CRC32 0xe14a2f5a Query thread_id=576127 exec_time=0 error_code=0
SET TIMESTAMP=1565409620/*!*/;
BEGIN
/*!*/;
# at 8687
#190810 12:00:20 server id 206195699 end_log_pos 8775 CRC32 0xaf16fb7d Table_map: `risk_control`.`log_operation` mapped to number 39286
# at 8775
#190810 12:00:20 server id 206195699 end_log_pos 9055 CRC32 0x9bdc15ae Write_rows: table id 39286 flags: STMT_END_F
### INSERT INTO `risk_control`.`log_operation`
### SET
### @1=8166048 /* INT meta=0 nullable=0 is_null=0 */
### @2='7b0d526124ba40f6ac71cfe1d0d90665' /* VARSTRING(160) meta=160 nullable=0 is_null=0 */
### @3=17 /* INT meta=0 nullable=1 is_null=0 */
### @4='2' /* VARSTRING(64) meta=64 nullable=1 is_null=0 */
### @5='casign_end=;方法public void com.xxx.risk.service.impl.ActivitiEventServiceImpl.updateAuditStatus(java.lang.String,java.lang.String);参数{"auditStatus": 3}' /* VARSTRING(1020) meta=1020 nullable=0 is_null=0 */
### @6='\x00\x01\x00\x16\x00\x0b\x00\x0b\x00\x05\x03\x00auditStatus' /* JSON meta=4 nullable=1 is_null=0 */
### @7='2019-08-10 12:00:21' /* DATETIME(0) meta=0 nullable=0 is_null=0 */
### @8='' /* VARSTRING(128) meta=128 nullable=0 is_null=0 */
### @9='' /* VARSTRING(256) meta=256 nullable=0 is_null=0 */
# at 9055
#190810 12:00:20 server id 206195699 end_log_pos 9086 CRC32 0xbe19a1b1 Xid = 180175929
COMMIT/*!*/;其实这种设计可以理解,作为一个高效的二进制格式,binlog里不存储冗余度极高的列名可以很可观的减少体积,并且,有了表名,表结构信息可以从MySQL information_schema表中拿到的,何必再存一份呢?
但是,debezium偷梁换柱,模拟从库拉取binlog做解析,他并不是真正的从库,是没有information_schema表可以查的,只能从MySQL主库查询。但这个方式真的万无一失吗?
考虑下面的场景:
15:00 BinlogReader正常消费
15:05 Kafka Connect集群维护,暂停BinlogReader
15:10 表A修改,在第3列后增加了1列(新增列不一定在尾部)
15:15 Kafka Connect集群维护结束,恢复BinlogReader
这个场景中,BinlogReader在15:15恢复后,会继续从15:05读取并解析binlog,如果这时从MySQL读取information_schema来获取表A的schema信息,那么在15:05-15:10期间binlog和schema是不匹配的,也就无法解析出正确的数据。换句话说,如果debezium读取binlog有延迟,这段时间主库schema做了修改,那么读取主库information_schema的方案就会有问题了。
要解决这个问题,就要模拟information_schema机制,维护一份当前的schema快照,可这样就够了吗?
回到前面提到的AbstractReader内部设计上,BinlogReader作为生产者,其将解析后的数据投递到BlockingQueue中,如果在解析binlog过程中遇到了DDL语句(比如alter table add column ...),就会更新当前的schema快照。

这时,如果stop task,如上图,BlockingQueue中还未被消费的records将被丢弃,如果包含schema修改之前解析出的record,那么下次binlog将从此处开始解析,而debezium存储的schema快照却已经对应了修改后的,也会照成binlog和schema的不匹配。在这种边缘场景下,仅保存当前schema快照的方案就行不通了。当然,后面我们还会提到这种模式同样不能满足很多其他场景。
事已至此,我们只好使用终极方案,把每一次的schema变更都保存下来,构造一条完整的schema时间线,确保在解析任一时刻的binlog事件时,都能找到对应版本的schema快照。
Debezium中使用DatabaseHistory来实现该功能,功能已经满足,不过实现的确是简陋。MySQLDatabaseHistory会从同步任务启动时,导出所有的create table语句(参见snapshot过程第6步),在此基础上,追加记录每一条DDL语句,debezium为这些DDL存储提供了内存、文件、kafka topic实现,其中kafka topic必须设置过期策略为永不过期。
当要恢复到任意时刻的schema快照时,从头开始,逐条解析所有的DDL,叠加修改,直到指定时刻前最后一条DDL。可以看到,这种实现方式的效率是比较低的,当任务持续数个月时,会累积大量的DDL(尤其是在阿里云RDS上,不知道阿里云改了什么,binlog里会产生海量的DDL),一次恢复可能需要数十分钟乃至数个小时,并且若其中有一处DDL解析错误,会导致其后所有的快照都发生错误。开发者很早就意识到了这个问题,并且提出了一些改进想法,可能会在不久后有所进展。
看到这里,相信你已经可以理解,为什么有些商业的数据同步引擎对同步过程中的schema变更有所限制,要完备的支持各种情况,着实不是一件容易的事情。
我们前面已经多次提到了DBZ-175,现在我们我们开始讨论这个精彩的设计。https://issues.redhat.com/browse/DBZ-175
注:该功能仅作为内部实验特性,官方文档未提及,有问题请参考JIRA讨论或者阅读调试源码。
我们先来补充一些背景,debezium在同步数据过程中,允许通过table.whitelist和table.blacklist指定要同步的表。假设一开始,我们将table.whitelist配置为a,b两张表,这两张表完成了Snapshot阶段,已经稳定的切换到Stream阶段。这时,来了新的同步需求,要再同步c表,并且最好不干扰a,b两张表的同步进度。那很自然的想法就是我再起一个新的同步任务来处理c表,长此以往,你会发现一个MySQL主库上挂了很多个“从库”,对MySQL主库会照成一定压力。所以,一个理想的方案便是:修改同步任务的table.whitelist后,debezium可以自动完成新增表的全量和增量同步,并且这个过程不会干扰原有的同步任务;当新老两批同步任务进度相近时,合二为一,只使用同一个BinlogReader完成后续的stream同步。
简单吧!怎么实现呢?就是我们前文暂时略过的ParallelSnapshotReader和ReconcilingBinlogReader。
首先描述一下在线加表后,整个Reader的结构。
ChainedReader ├── ParallelSnapshotReader │ ├── OldTablesBinlogReader │ └── ChainedReader │ ├── NewTablesSnapshotReader │ └── NewTablesBinlogReader ├── ReconcilingBinlogReader └── UnifiedBinlogReader
ParallelSnapshotReader就如其名字一样,在保证不干扰OldTablesBinlogReader运行的情况下,并行的开始对新增表进行全量和增量同步;
当新增表进入stream阶段后,OldTablesBinlogReader和NewTablesBinlogReader每一次拉取都会和对方作比较,当两者的进度相差在一定时间内(默认时5分钟)时,将两者停止;
此时ParallelSnapshotReader退出,由ReconcilingBinlogReader将两个BinlogReader进度同步,即将滞后者追平只领先者;
原有的两个BinlogReader退出,新建的UnifiedBinlogReader从其位点继续做新老所有表的stream解析,整个合并过程结束。
这段设计是我在翻阅了JIRA上数位开发者们历经几年的讨论记录后,结合代码调试整理得出的。回想当年刚毕业的我,接到这个在线加表需求时,本以为是不可能实现的事情,直到发现了这个设计,不由得是感叹和惊喜。
这只是一个初版的实现,在整个过程中,因为元数据的设计问题,并不支持schema的变更,可能正是由于这个原因,严谨的开发者们选择不公开这项功能,仅作为内部实验特性。
看完上述内容,你们对怎样分析Debezium MySQL模块设计有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





