pythonжҖҺд№ҲжүҫеҮәж•°жҚ®зӣёе…іжҖ§
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңpythonжҖҺд№ҲжүҫеҮәж•°жҚ®зӣёе…іжҖ§вҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңpythonжҖҺд№ҲжүҫеҮәж•°жҚ®зӣёе…іжҖ§вҖқеҗ§пјҒ
й—®йўҳжҸҸиҝ°
йҰ–е…ҲпјҢжҲ‘们йңҖиҰҒи®Ёи®әз«һиөӣжң¬иә«гҖӮDengAIзҡ„зӣ®ж ҮжҳҜпјҲзӣ®еүҚжҳҜпјҢеӣ дёәDriventaз®ЎзҗҶеұҖеҶіе®ҡе°Ҷе…¶и®ҫдёәвҖңжҢҒз»ӯзҡ„вҖқжҜ”иөӣпјҢеӣ жӯӨдҪ еҸҜд»ҘзҺ°еңЁеҠ е…Ҙпјүж №жҚ®еӨ©ж°”ж•°жҚ®е’Ңең°зӮ№йў„жөӢзү№е®ҡдёҖе‘Ёзҡ„зҷ»йқ©зғӯз—…дҫӢж•°гҖӮ
жҜҸдёӘеҸӮдёҺиҖ…йғҪеҫ—еҲ°дәҶдёҖдёӘи®ӯз»ғж•°жҚ®йӣҶе’ҢжөӢиҜ•ж•°жҚ®йӣҶпјҲдёҚжҳҜйӘҢиҜҒж•°жҚ®йӣҶпјүгҖӮMAEпјҲе№іеқҮз»қеҜ№иҜҜе·®пјүжҳҜдёҖз§Қз”ЁдәҺи®Ўз®—еҲҶж•°зҡ„жҢҮж ҮпјҢи®ӯз»ғж•°жҚ®йӣҶж¶өзӣ–дәҶ2дёӘеҹҺеёӮпјҲ1456е‘Ёпјү28е№ҙзҡ„жҜҸе‘Ёзҡ„ж•°еҖјгҖӮжөӢиҜ•ж•°жҚ®иҫғе°ҸпјҢжңүи·Ёи¶Ҡ5е№ҙе’Ң3е№ҙзҡ„пјҲиҝҷеҸ–еҶідәҺеҹҺеёӮпјүгҖӮ
зҷ»йқ©зғӯжҳҜдёҖз§ҚиҡҠеӯҗдј ж’ӯзҡ„з–ҫз—…пјҢеҸ‘з”ҹеңЁдё–з•ҢзғӯеёҰе’ҢдәҡзғӯеёҰең°еҢәгҖӮеӣ дёәе®ғжҳҜз”ұиҡҠеӯҗжҗәеёҰзҡ„пјҢиҜҘз–ҫз—…зҡ„дј ж’ӯдёҺж°”еҖҷгҖҒеӨ©ж°”еҸҳеҢ–жңүе…ігҖӮ
ж•°жҚ®йӣҶ
еҰӮжһңжҲ‘们зңӢдёҖдёӢи®ӯз»ғж•°жҚ®йӣҶпјҢе®ғжңүеӨҡдёӘзү№еҫҒпјҡ
еҹҺеёӮе’Ңж—ҘжңҹжҢҮж Үпјҡ
NOAAзҡ„GHCNжҜҸж—Ҙж°”еҖҷж•°жҚ®ж°”иұЎз«ҷжөӢйҮҸпјҡ
station_max_temp_c-жңҖй«ҳжё©еәҰ
station_min_temp_c-жңҖдҪҺжё©еәҰ
station_avg_temp_c-е№іеқҮжё©еәҰ
station_precip_mm-жҖ»йҷҚж°ҙйҮҸ
station_diur_temp_rng_c-жҳјй—ҙжё©еәҰиҢғеӣҙ
еҚ«жҳҹйҷҚж°ҙжөӢйҮҸпјҲ0.25x0.25еәҰзҡ„ж ҮеәҰпјүпјҡ
NOAAзҡ„NCEPж°”еҖҷйў„жҠҘзі»з»ҹеҲҶжһҗжөӢйҮҸпјҲ0.5x0.5еәҰзҡ„ж ҮеәҰпјүпјҡ
reanalysis_sat_precip_amt_mm-жҖ»йҷҚж°ҙйҮҸ
reanalysis_dew_point_temp_k-е№іеқҮйңІзӮ№жё©еәҰ
reanalysis_air_temp_k-е№іеқҮж°”жё©
reanalysis_relative_humidity_percent-е№іеқҮзӣёеҜ№ж№ҝеәҰ
reanalysis_specific_humidity_g_per_kg-е№іеқҮзү№е®ҡж№ҝеәҰ
reanalysis_precip_amt_kg_per_m2-жҖ»йҷҚж°ҙйҮҸ
reanalysis_max_air_temp_k=жңҖеӨ§з©әж°”жё©еәҰ
reanalysis_min_air_temp_k-жңҖдҪҺз©әж°”жё©еәҰ
reanalysis_avg_temp_k-е№іеқҮж°”жё©
reanalysis_tdtr_k-зҷҪеӨ©жё©еәҰиҢғеӣҙ
NOAAзҡ„CDRеҪ’дёҖеҢ–е·®ејӮжӨҚиў«жҢҮж•°пјҲNDVIпјүпјҲ0.5x0.5еәҰзҡ„ж ҮеәҰпјүпјҡ
ndvi_se-еҹҺеёӮиҙЁеҝғдёңеҚ—зҡ„NVDI
ndvi_sw-еҹҺеёӮиҙЁеҝғиҘҝеҚ—зҡ„NVDI
ndvi_ne-еҹҺеёӮиҙЁеҝғдёңеҢ—зҡ„NVDI
ndvi_nw-еҹҺеёӮдёӯеҝғиҘҝеҢ—зҡ„NVDI
жӯӨеӨ–пјҢжҲ‘们иҝҳжңүжҜҸе‘ЁжҖ»з—…дҫӢж•°зҡ„дҝЎжҒҜгҖӮ
еҫҲе®№жҳ“еҸ‘зҺ°пјҢеҜ№дәҺж•°жҚ®йӣҶдёӯзҡ„жҜҸдёҖиЎҢпјҢжҲ‘们йғҪжңүеӨҡдёӘжҸҸиҝ°зұ»дјјж•°жҚ®зҡ„зү№еҫҒгҖӮжңүеӣӣзұ»пјҡ
еӣ жӯӨпјҢжҲ‘们еә”иҜҘиғҪеӨҹд»Һиҫ“е…ҘдёӯеҲ йҷӨдёҖдәӣеҶ—дҪҷж•°жҚ®гҖӮ
иҫ“е…ҘзӨәдҫӢпјҡ
week_start_date 1994-05-07
total_cases 22
station_max_temp_c 33.3
station_avg_temp_c 27.7571428571
station_precip_mm 10.5
station_min_temp_c 22.8
station_diur_temp_rng_c 7.7
precipitation_amt_mm 68.0
reanalysis_sat_precip_amt_mm 68.0
reanalysis_dew_point_temp_k 295.235714286
reanalysis_air_temp_k 298.927142857
reanalysis_relative_humidity_percent 80.3528571429
reanalysis_specific_humidity_g_per_kg 16.6214285714
reanalysis_precip_amt_kg_per_m2 14.1
reanalysis_max_air_temp_k 301.1
reanalysis_min_air_temp_k 297.0
reanalysis_avg_temp_k 299.092857143
reanalysis_tdtr_k 2.67142857143
ndvi_location_1 0.1644143
ndvi_location_2 0.0652
ndvi_location_3 0.1321429
ndvi_location_4 0.08175
жҸҗдәӨж јејҸпјҡ
city,year,weekofyear,total_cases
sj,1990,18,4
sj,1990,19,5
...
иҜ„еҲҶиҜ„д»·пјҡ
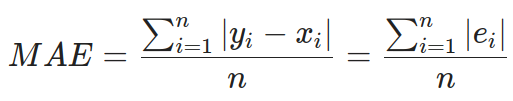
ж•°жҚ®еҲҶжһҗ
еңЁејҖе§Ӣи®ҫи®ЎжЁЎеһӢд№ӢеүҚпјҢжҲ‘们йңҖиҰҒжҹҘзңӢеҺҹе§Ӣж•°жҚ®е№¶еҠ д»Ҙдҝ®жӯЈгҖӮдёәдәҶиҫҫеҲ°иҝҷдёӘзӣ®зҡ„пјҢжҲ‘们е°ҶдҪҝз”Ёpandasеә“гҖӮйҖҡеёёпјҢжҲ‘们еҸҜд»ҘзӣҙжҺҘеҜје…Ҙ.csvж–Ү件并еӨ„зҗҶеҜје…Ҙзҡ„ж•°жҚ®её§пјҢдҪҶжңүж—¶пјҲзү№еҲ«жҳҜеҪ“第дёҖиЎҢжІЎжңүеҲ—жҸҸиҝ°ж—¶пјүпјҢжҲ‘们еҝ…йЎ»жҸҗдҫӣеҲ—еҲ—иЎЁгҖӮ
import pandas as pd
pd.set_option("display.precision", 2)
df = pd.read_csv('./dengue_features_train_with_out.csv')
df.describe()PandasжңүдёҖдёӘеҗҚдёәdescribeзҡ„еҶ…зҪ®ж–№жі•пјҢе®ғжҳҫзӨәж•°жҚ®йӣҶдёӯеҲ—зҡ„еҹәжң¬з»ҹи®ЎдҝЎжҒҜгҖӮ
еҪ“然пјҢиҝҷз§Қж–№жі•еҸӘйҖӮз”ЁдәҺж•°еҖјж•°жҚ®гҖӮеҰӮжһңжҲ‘们жңүйқһж•°еҖјеҲ—пјҢжҲ‘们еҝ…йЎ»е…ҲеҒҡдёҖдәӣйў„еӨ„зҗҶгҖӮеңЁжҲ‘们зҡ„дҫӢеӯҗдёӯпјҢе”ҜдёҖзҡ„еҲ—жҳҜcityгҖӮиҝҷдёӘеҲ—еҸӘеҢ…еҗ«sjе’ҢiqдёӨдёӘеҖјпјҢжҲ‘们зЁҚеҗҺе°ҶеӨ„зҗҶе®ғгҖӮ
еӣһеҲ°дё»иЎЁгҖӮжҜҸиЎҢеҢ…еҗ«дёҚеҗҢзұ»еһӢзҡ„дҝЎжҒҜпјҡ
count -жҸҸиҝ°йқһNaNеҖјзҡ„дёӘж•°
mean -ж•ҙеҲ—зҡ„е№іеқҮеҖјпјҲз”ЁдәҺж ҮеҮҶеҢ–пјү
std -ж ҮеҮҶе·®пјҲд№ҹеҸҜз”ЁдәҺж ҮеҮҶеҢ–пјү
min ->max -жҳҫзӨәеҢ…еҗ«еҖјзҡ„иҢғеӣҙпјҲз”ЁдәҺзј©ж”ҫпјү
и®©жҲ‘们д»Һи®Ўж•°ејҖе§ӢгҖӮзҹҘйҒ“ж•°жҚ®йӣҶдёӯжңүеӨҡе°‘жқЎи®°еҪ•дёўеӨұдәҶпјҲдёҖдёӘжҲ–еӨҡдёӘпјү并еҶіе®ҡеҰӮдҪ•еӨ„зҗҶиҝҷдәӣж•°жҚ®жҳҜеҫҲйҮҚиҰҒзҡ„гҖӮеҰӮжһңдҪ зңӢndvi_nwеҖјпјҢе®ғеңЁ13.3%зҡ„жғ…еҶөдёӢжҳҜз©әзҡ„гҖӮеҰӮжһңдҪ еҶіе®ҡз”ЁиҜёеҰӮ0д№Ӣзұ»зҡ„д»»ж„ҸеҖјжӣҝжҚўзјәе°‘зҡ„еҖјпјҢиҝҷеҸҜиғҪжҳҜдёӘжҖ§иғҪй—®йўҳгҖӮйҖҡеёёпјҢжңүдёӨз§Қеёёи§Ғзҡ„и§ЈеҶіж–№жЎҲпјҡ
жҸ’еҖјпјҲеӨ„зҗҶзјәеӨұж•°жҚ®пјү
еҪ“еӨ„зҗҶеәҸеҲ—ж•°жҚ®ж—¶пјҲе°ұеғҸжҲ‘们иҝҷдёӘеңәжҷҜдёҖж ·пјүпјҢд»Һе®ғзҡ„йӮ»еҹҹдёӯжҸ’еҖјпјҲд»…д»ҺйӮ»еҹҹдёӯеҸ–е№іеқҮеҖјпјүеҖјпјҢиҖҢдёҚжҳҜз”Ёж•ҙдёӘйӣҶеҗҲдёӯзҡ„е№іеқҮеҖјжқҘд»Јжӣҝе®ғпјҢиҝҷж ·жҜ”иҫғеҗҲзҗҶгҖӮ
йҖҡеёёпјҢеәҸеҲ—ж•°жҚ®еңЁеәҸеҲ—дёӯзҡ„еҖјд№Ӣй—ҙжңүдёҖе®ҡзҡ„зӣёе…іжҖ§пјҢдҪҝз”ЁйӮ»еҹҹеҸҜд»Ҙеҫ—еҲ°жӣҙеҘҪзҡ„з»“жһңгҖӮжҲ‘з»ҷдҪ дёҫдёӘдҫӢеӯҗгҖӮ
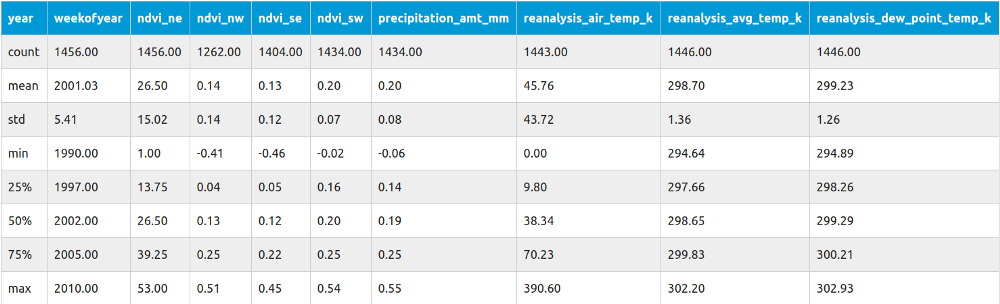
еҒҮи®ҫдҪ жӯЈеңЁеӨ„зҗҶжё©еәҰж•°жҚ®пјҢ并且дҪ зҡ„ж•ҙдёӘж•°жҚ®йӣҶз”ұдёҖжңҲеҲ°еҚҒдәҢжңҲзҡ„еҖјз»„жҲҗгҖӮе…Ёе№ҙзҡ„е№іеқҮеҖје°ҶжҳҜдёҖе№ҙдёӯеӨ§йғЁеҲҶж—¶й—ҙзјәеӨұеӨ©ж•°зҡ„ж— ж•Ҳжӣҝд»ЈеҖјгҖӮ
еҰӮжһңд»Һ7жңҲејҖе§Ӣи®Ўз®—пјҢеҲҷеҸҜиғҪдјҡжңү[28пјҢ27пјҢ-пјҢ-пјҢ30]гҖӮеҰӮжһңеңЁдјҰж•Ұзҡ„иҜқпјҢе№ҙе№іеқҮж°”жё©жҳҜ11ж‘„ж°ҸеәҰпјҲжҲ–52еҚҺж°ҸеәҰпјүгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢдҪҝз”Ё11дҪңдёәжё©еәҰеЎ«е……е°ұжҳҜй”ҷиҜҜзҡ„гҖӮиҝҷе°ұжҳҜдёәд»Җд№ҲжҲ‘们еә”иҜҘдҪҝз”ЁжҸ’еҖјиҖҢдёҚжҳҜе№іеқҮеҖјгҖӮ
жңүдәҶжҸ’еҖјпјҲеҚідҪҝеңЁжңүжӣҙеӨ§е·®и·қзҡ„жғ…еҶөдёӢпјүпјҢжҲ‘们еә”иҜҘиғҪеӨҹиҺ·еҫ—жӣҙеҘҪзҡ„з»“жһңгҖӮеҰӮжһңдҪ и®Ўз®—иҝҷдәӣеҖјпјҢдҪ еә”иҜҘеҫ—еҲ°пјҲ27+30пјү/2=28.5е’ҢпјҲ28.5+30пјү/2=29.25пјҢжүҖд»ҘжңҖз»ҲжҲ‘们зҡ„ж•°жҚ®йӣҶзңӢиө·жқҘеғҸжҳҜ[28пјҢ27пјҢ28.5пјҢ29.25пјҢ30]пјҢиҝңиҝңеҘҪдәҺ[28пјҢ27пјҢ11пјҢ11пјҢ30]гҖӮ
е°Ҷж•°жҚ®йӣҶжӢҶеҲҶдёәеҹҺеёӮ
еӣ дёәжҲ‘们已з»Ҹи®Ёи®әдәҶдёҖдәӣйҮҚиҰҒзҡ„дәӢжғ…пјҢжүҖд»ҘжҲ‘们еҸҜд»Ҙе®ҡд№үдёҖз§Қж–№жі•пјҢиҜҘж–№жі•е…Ғи®ёжҲ‘们е°ҶеҲҶзұ»еҲ—пјҲcityпјүйҮҚж–°е®ҡд№үдёәдәҢиҝӣеҲ¶еҲ—еҗ‘йҮҸ并еҜ№ж•°жҚ®иҝӣиЎҢжҸ’еҖјпјҡ
def extract_data(train_file_path, columns, categorical_columns=CATEGORICAL_COLUMNS, categories_desc=CATEGORIES,
interpolate=True):
# иҜ»еҸ–csvж–Ү件并иҝ”еӣһ
all_data = pd.read_csv(train_file_path, usecols=columns)
if categorical_columns is not None:
# е°ҶеҲҶзұ»жҳ е°„еҲ°еҲ—
for feature_name in categorical_columns:
mapping_dict = {categories_desc[feature_name][i]: categories_desc[feature_name][i] for i in
range(0, len(categories_desc[feature_name]))}
all_data[feature_name] = all_data[feature_name].map(mapping_dict)
# е°Ҷжҳ е°„зҡ„еҲҶзұ»ж•°жҚ®жӣҙж”№дёә0/1еҲ—
all_data = pd.get_dummies(all_data, prefix='', prefix_sep='')
# дҝ®еӨҚдёўеӨұзҡ„ж•°жҚ®
if interpolate:
all_data = all_data.interpolate(method='linear', limit_direction='forward')
return all_data
жӯӨеҮҪж•°иҝ”еӣһдёҖдёӘж•°жҚ®йӣҶпјҢе…¶дёӯеҢ…еҗ«дёӨдёӘеҗҚдёәsjе’Ңiqзҡ„дәҢиҝӣеҲ¶еҲ—пјҢе®ғ们具жңүеёғе°”еҖјпјҢе…¶дёӯcityиў«и®ҫзҪ®дёәsjжҲ–iqгҖӮ
з»ҳеҲ¶ж•°жҚ®
з»ҳеҲ¶ж•°жҚ®еӣҫд»Ҙзӣҙи§Ӯең°дәҶи§ЈеҖјеңЁеәҸеҲ—дёӯзҡ„еҲҶеёғжҳҜеҫҲйҮҚиҰҒзҡ„гҖӮжҲ‘们е°ҶдҪҝз”ЁдёҖдёӘеҗҚдёәSeabornзҡ„еә“жқҘеё®еҠ©жҲ‘们з»ҳеҲ¶ж•°жҚ®гҖӮ
sns.pairplot(dataset[["precipitation_amt_mm", "reanalysis_sat_precip_amt_mm", "station_precip_mm"]], diag_kind="kde")
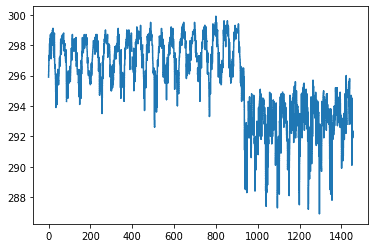
иҝҷйҮҢжҲ‘们еҸӘжңүдёҖдёӘж•°жҚ®йӣҶзҡ„зү№еҫҒпјҢжҲ‘们еҸҜд»Ҙжё…жҘҡең°еҢәеҲҶеӯЈиҠӮе’ҢеҹҺеёӮпјҲе№іеқҮеҖјд»Һ~297дёӢйҷҚеҲ°~292пјүгҖӮ
еҸҰдёҖ件жңүз”Ёзҡ„дәӢжғ…жҳҜдёҚеҗҢзү№еҫҒд№Ӣй—ҙзҡ„е…іиҒ”гҖӮиҝҷж ·жҲ‘们е°ұеҸҜд»Ҙд»Һж•°жҚ®йӣҶдёӯеҲ йҷӨдёҖдәӣеҶ—дҪҷзҡ„зү№еҫҒгҖӮ
жӯЈеҰӮдҪ жүҖжіЁж„ҸеҲ°зҡ„пјҢжҲ‘们еҸҜд»Ҙз«ӢеҚіеҲ йҷӨе…¶дёӯдёҖдёӘйҷҚж°ҙзү№еҫҒгҖӮдёҖејҖе§ӢиҝҷеҸҜиғҪжҳҜж— ж„Ҹзҡ„пјҢдҪҶеӣ дёәжҲ‘们жңүжқҘиҮӘдёҚеҗҢжқҘжәҗзҡ„ж•°жҚ®пјҢеҗҢдёҖзұ»ж•°жҚ®пјҲеҰӮйҷҚж°ҙйҮҸпјү并дёҚжҖ»жҳҜе®Ңе…Ёзӣёе…ізҡ„гҖӮиҝҷеҸҜиғҪжҳҜз”ұдәҺдёҚеҗҢзҡ„жөӢйҮҸж–№жі•жҲ–е…¶д»–еҺҹеӣ йҖ жҲҗзҡ„гҖӮ
ж•°жҚ®зӣёе…іжҖ§
еҪ“жҲ‘们дҪҝз”ЁеҫҲеӨҡзү№еҫҒж—¶пјҢжҲ‘们дёҚйңҖиҰҒдёәжҜҸдёҖеҜ№йғҪз»ҳеҲ¶жҲҗеҜ№еӣҫгҖӮеҸҰдёҖдёӘйҖүжӢ©е°ұжҳҜи®Ўз®—жүҖи°“зҡ„зӣёе…іжҖ§еҲҶж•°гҖӮдёҚеҗҢзұ»еһӢзҡ„ж•°жҚ®жңүдёҚеҗҢзұ»еһӢзҡ„зӣёе…іжҖ§гҖӮжҲ‘们дҪҝз”Ёcorr()зҡ„ж–№жі•з”ҹжҲҗж•°жҚ®йӣҶзҡ„ж•°еҖјзӣёе…іжҖ§гҖӮ
еҰӮжһңжңүдёҚеә”иҜҘиў«и§ҶдёәдәҢиҝӣеҲ¶зҡ„еҲҶзұ»еҲ—пјҢдҪ еҸҜд»Ҙи®Ўз®—Cramerзҡ„Vе…іиҒ”еәҰйҮҸжқҘжүҫеҮәе®ғ们е’Ңе…¶д»–ж•°жҚ®д№Ӣй—ҙзҡ„вҖңзӣёе…іжҖ§вҖқгҖӮ
import pandas as pd
import seaborn as sns
# еҜје…ҘжҲ‘们зҡ„жҸҗеҸ–еҮҪж•°
from helpers import extract_data
from data_info import *
train_data = extract_data(train_file, CSV_COLUMNS)
# иҺ·еҸ–вҖңsjвҖқcityзҡ„ж•°жҚ®е№¶еҲ йҷӨдёӨдёӘдәҢиҝӣеҲ¶еҲ—
sj_train = train_data[train_data['sj'] == 1].drop(['sj', 'iq'], axis=1)
# з”ҹжҲҗзғӯеӣҫ
corr = sj_train.corr()
mask = np.triu(np.ones_like(corr, dtype=np.bool))
plt.figure(figsize=(20, 10))
ax = sns.heatmap(
corr,
mask=mask,
vmin=-1, vmax=1, center=0,
cmap=sns.diverging_palette(20, 220, n=200),
square=True
)
ax.set_title('Data correlation for city "sj"')
ax.set_xticklabels(
ax.get_xticklabels(),
rotation=45,
horizontalalignment='right'
);
дҪ еҸҜд»ҘеҜ№iq еҹҺеҒҡеҗҢж ·зҡ„дәӢжғ…пјҢ并е°ҶдёӨиҖ…иҝӣиЎҢжҜ”иҫғпјҲзӣёе…іжҖ§жҳҜдёҚеҗҢзҡ„пјүгҖӮ
еҰӮжһңдҪ зңӢзңӢиҝҷеј зғӯеӣҫпјҢеҫҲжҳҺжҳҫеҸҜд»ҘзңӢеҮәе“Әдәӣзү№еҫҒзӣёдә’е…іиҒ”пјҢе“ӘдәӣдёҚзӣёе…ігҖӮдҪ еә”иҜҘзҹҘйҒ“жңүжӯЈзӣёе…іе’Ңиҙҹзӣёе…іпјҲж·ұи“қиүІе’Ңж·ұзәўиүІпјүгҖӮжІЎжңүзӣёе…іжҖ§зҡ„зү№еҫҒжҳҜзҷҪиүІзҡ„гҖӮ
жңүеҮ з»„жӯЈзӣёе…ізҡ„зү№еҫҒпјҢжҜ«дёҚеҘҮжҖӘпјҢе®ғ们жҢҮзҡ„жҳҜеҗҢдёҖзұ»еһӢзҡ„жөӢйҮҸ(дҫӢеҰӮstation_min_temp_cе’Ңstation_avg_temp_cд№Ӣй—ҙзҡ„зӣёе…іжҖ§)гҖӮдҪҶеңЁдёҚеҗҢзҡ„зү№еҫҒд№Ӣй—ҙд№ҹеӯҳеңЁзӣёе…іжҖ§(жҜ”еҰӮreanalysis_specific_humidity_g_per_kgе’Ңreanalysis_dew_point_temp_k)гҖӮжҲ‘们иҝҳеә”иҜҘе…іжіЁtotal_casesе’Ңе…¶д»–зү№еҫҒд№Ӣй—ҙзҡ„зӣёе…іжҖ§пјҢеӣ дёәиҝҷжҳҜжҲ‘们йңҖиҰҒйў„жөӢзҡ„гҖӮ
иҝҷж¬ЎжҲ‘们иө°иҝҗдәҶпјҢеӣ дёәжІЎжңүд»Җд№ҲдёңиҘҝе’ҢжҲ‘们зҡ„зӣ®ж ҮжңүеҫҲејәзҡ„зӣёе…іжҖ§гҖӮдҪҶжҳҜжҲ‘们д»Қ然еә”иҜҘиғҪеӨҹдёәжҲ‘们зҡ„жЁЎеһӢйҖүжӢ©жңҖйҮҚиҰҒзҡ„зү№еҫҒгҖӮзҺ°еңЁзңӢзғӯеӣҫжІЎд»Җд№Ҳз”ЁпјҢи®©жҲ‘еҲҮжҚўеҲ°жқЎеҪўеӣҫгҖӮ
sorted_y = corr.sort_values(by='total_cases', axis=0).drop('total_cases')
plt.figure(figsize=(20, 10))
ax = sns.barplot(x=sorted_y.total_cases, y=sorted_y.index, color="b")
ax.set_title('Correlation with total_cases in "sj"')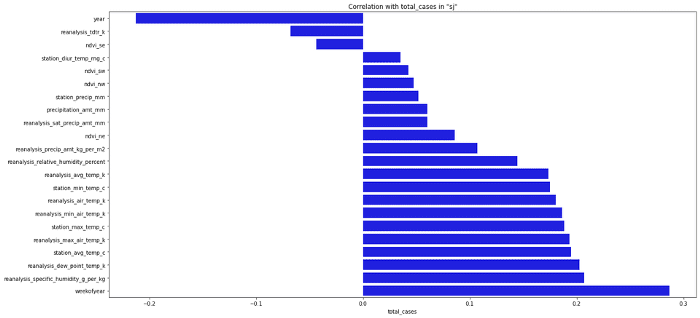
йҖҡеёёпјҢеңЁдёәжЁЎеһӢйҖүжӢ©зү№еҫҒж—¶пјҢжҲ‘们йҖүжӢ©зҡ„зү№еҫҒдёҺзӣ®ж Үзҡ„з»қеҜ№зӣёе…іеҖјжңҖй«ҳгҖӮиҝҷеҸ–еҶідәҺдҪ еҶіе®ҡдҪ йҖүжӢ©еӨҡе°‘зү№еҫҒпјҢдҪ з”ҡиҮіеҸҜд»ҘйҖүжӢ©жүҖжңүзҡ„зү№еҫҒпјҢдҪҶиҝҷйҖҡеёёдёҚжҳҜжңҖеҘҪзҡ„дё»ж„ҸгҖӮ
и§ӮеҜҹзӣ®ж ҮеҖјеңЁж•°жҚ®йӣҶдёӯжҳҜеҰӮдҪ•еҲҶеёғзҡ„д№ҹжҳҜеҫҲйҮҚиҰҒзҡ„гҖӮжҲ‘们еҸҜд»ҘеҫҲе®№жҳ“ең°з”ЁpandasеҒҡеҲ°пјҡ
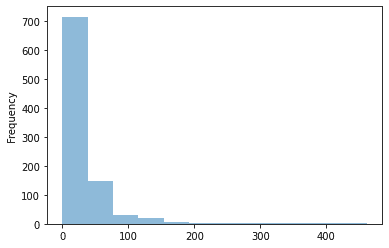
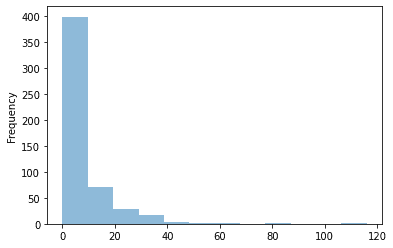
е№іеқҮдёҖе‘Ёзҡ„з—…дҫӢж•°зӣёеҪ“е°‘гҖӮеҸӘжҳҜеҒ¶е°”пјҲдёҖе№ҙдёҖж¬ЎпјүпјҢжЎҲ件жҖ»ж•°дјҡи·іеҲ°жҹҗдёӘжӣҙй«ҳзҡ„ж•°еҖјгҖӮеңЁи®ҫи®ЎжҲ‘们зҡ„жЁЎеһӢж—¶пјҢжҲ‘们йңҖиҰҒи®°дҪҸиҝҷдёҖзӮ№пјҢеӣ дёәеҚідҪҝжҲ‘们и®ҫжі•жүҫеҲ°дәҶвҖңи·іи·ғвҖқпјҢжҲ‘们еҸҜиғҪдјҡеңЁеҮ е‘ЁеҶ…еҫ—еҲҶжҚҹеӨұжғЁйҮҚпјҢеӣ дёәи·іи·ғиҝҷз§Қжғ…еҶөеҮ д№ҺжІЎжңүж ·жң¬гҖӮ
д»Җд№ҲжҳҜNDVIеҖјпјҹ
жң¬ж–ҮжңҖеҗҺиҰҒи®Ёи®әзҡ„жҳҜNDVIжҢҮж•°пјҲеҪ’дёҖеҢ–е·®ејӮжӨҚиў«жҢҮж•°пјүгҖӮиҝҷдёӘжҢҮж•°жҳҜжӨҚиў«зҡ„жҢҮж ҮгҖӮй«ҳиҙҹеҖјеҜ№еә”дәҺж°ҙпјҢжҺҘиҝ‘0зҡ„еҖјиЎЁзӨәеІ©зҹі/жІҷеӯҗ/йӣӘпјҢеҖјжҺҘиҝ‘1зғӯеёҰжЈ®жһ—гҖӮеңЁз»ҷе®ҡзҡ„ж•°жҚ®йӣҶдёӯпјҢжҜҸдёӘеҹҺеёӮжңү4дёӘдёҚеҗҢзҡ„NDVIеҖјпјҲжҜҸдёӘеҖјеҜ№еә”дәҺең°еӣҫдёҠдёҚеҗҢзҡ„и§’иҗҪпјүгҖӮ
еҚідҪҝжҖ»дҪ“NDVIжҢҮж•°еҜ№дәҺдәҶи§ЈжҲ‘们жӯЈеңЁеӨ„зҗҶзҡ„ең°еҪўзұ»еһӢйқһеёёжңүз”ЁгҖӮеҰӮжһңжҲ‘们йңҖиҰҒдёәеӨҡдёӘеҹҺеёӮи®ҫи®ЎдёҖдёӘжЁЎеһӢпјҢең°еҪўзұ»еһӢзҡ„зү№еҫҒеҸҜиғҪдјҡеҫҲжңүз”ЁпјҢдҪҶеңЁиҝҷз§Қжғ…еҶөдёӢпјҢжҲ‘们еҸӘе·ІзҹҘдёӨдёӘеҹҺеёӮзҡ„ж°”еҖҷе’ҢдҪҚзҪ®гҖӮжҲ‘们дёҚйңҖиҰҒи®ӯз»ғжҲ‘们зҡ„жЁЎеһӢжқҘеҲӨж–ӯжҲ‘们жүҖеӨ„зҡ„зҺҜеўғпјҢзӣёеҸҚпјҢжҲ‘们еҸҜд»ҘдёәжҜҸдёӘеҹҺеёӮи®ӯз»ғдёҚеҗҢзҡ„жЁЎеһӢгҖӮ
жҲ‘иҠұдәҶдёҖж®өж—¶й—ҙе°қиҜ•дҪҝз”ЁиҝҷдәӣеҖјпјҲе°Өе…¶жҳҜеңЁиҝҷз§Қжғ…еҶөдёӢжҸ’еҖјеҫҲеӣ°йҡҫпјҢеӣ дёәжҲ‘们еңЁиҝҷдёӘиҝҮзЁӢдёӯдҪҝз”ЁдәҶеӨ§йҮҸзҡ„дҝЎжҒҜпјүгҖӮдҪҝз”ЁNDVIжҢҮж•°д№ҹеҸҜиғҪдә§з”ҹиҜҜеҜјпјҢеӣ дёәж•°еҖјзҡ„еҸҳеҢ–并дёҚдёҖе®ҡдёҺжӨҚиў«иҝҮзЁӢзҡ„еҸҳеҢ–зӣёеҜ№еә”гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңpythonжҖҺд№ҲжүҫеҮәж•°жҚ®зӣёе…іжҖ§вҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№pythonжҖҺд№ҲжүҫеҮәж•°жҚ®зӣёе…іжҖ§иҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ





