RabbitMQ Shovel的原理好用法是什么,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
Shovel能够可靠、持续地从一个Broker中的队列(作为源端,即source)拉取数据并转发至另一个Broker中的交换器(作为目的端,即destination)。作为源端的队列和作为目的端的交换器可以位于同一个Broker上,也可以位于不同的Broker上。
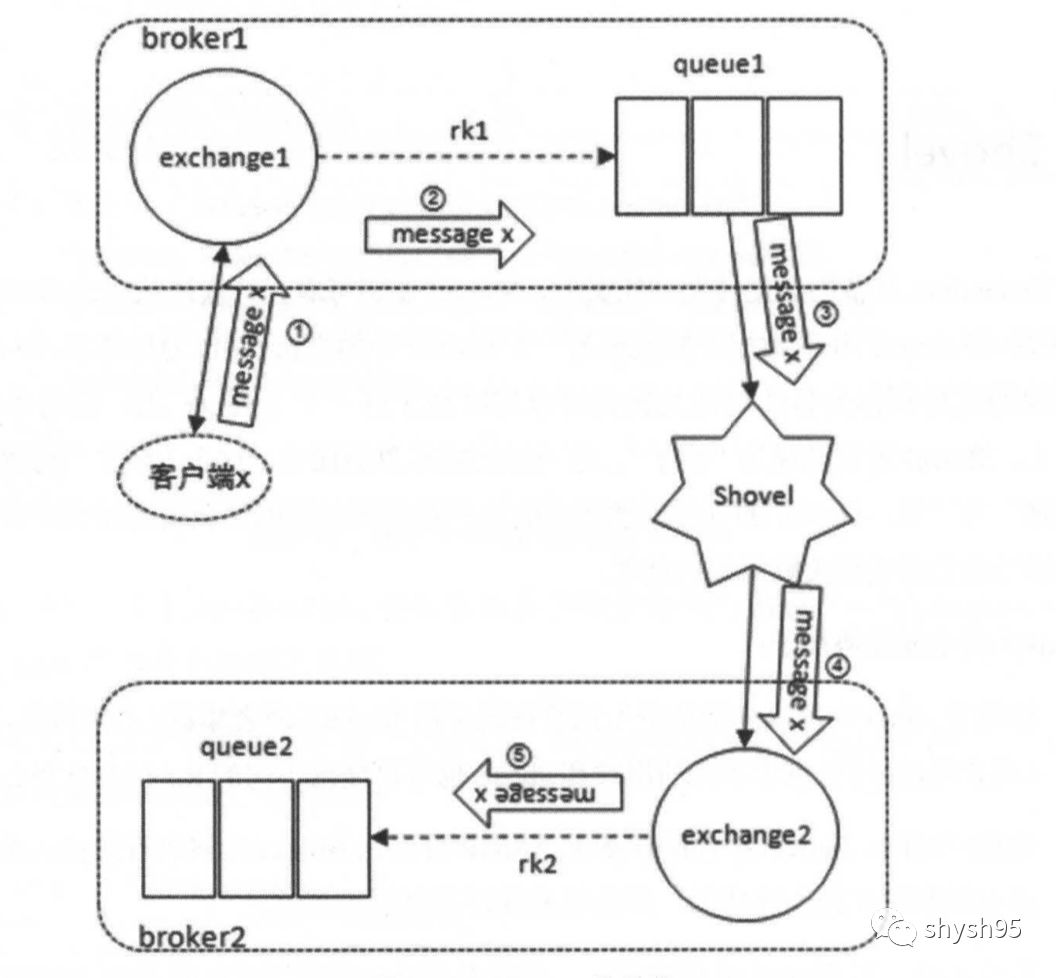 broker1中有交换器exchange1和队列queue1,且这两者通过路由键"rk1"进行绑定;broker2中有交换器exchange2和队列queue2,且这两者通过路由键"rk2"进行绑定。
broker1中有交换器exchange1和队列queue1,且这两者通过路由键"rk1"进行绑定;broker2中有交换器exchange2和队列queue2,且这两者通过路由键"rk2"进行绑定。
在队列queue1和交换器exchange2之间配置一个Shovel link,当一条内容为"shovel test payload" 的消息从客户端发送至交换器exchange1的时候,这条消息会经过上图中的数据流转最后存储在队列queue2中。如果在配置Shovel link设置了add-forward-headers参数为true,则在消费到队列queue2中这条消息的时候会有特殊的headers属性标记。如下图: 上面讲述的是源端为队列,目的端为交换器,下面看一下目的端也为队列的示意图:
上面讲述的是源端为队列,目的端为交换器,下面看一下目的端也为队列的示意图: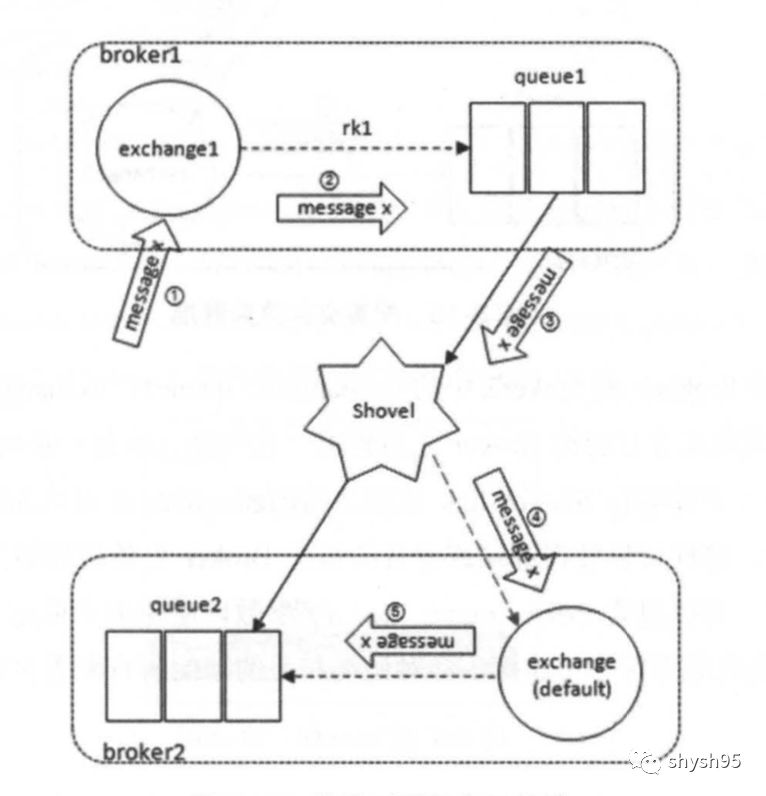 虽然看起来队列queue1是通过Shovel link直接将消息转发至queue2的,其实中间也是经由broker2的交换器转发,只不过这个交换器是默认的交换器而己。
虽然看起来队列queue1是通过Shovel link直接将消息转发至queue2的,其实中间也是经由broker2的交换器转发,只不过这个交换器是默认的交换器而己。
再看一下源端是交换器,目的端是交换器的示意图: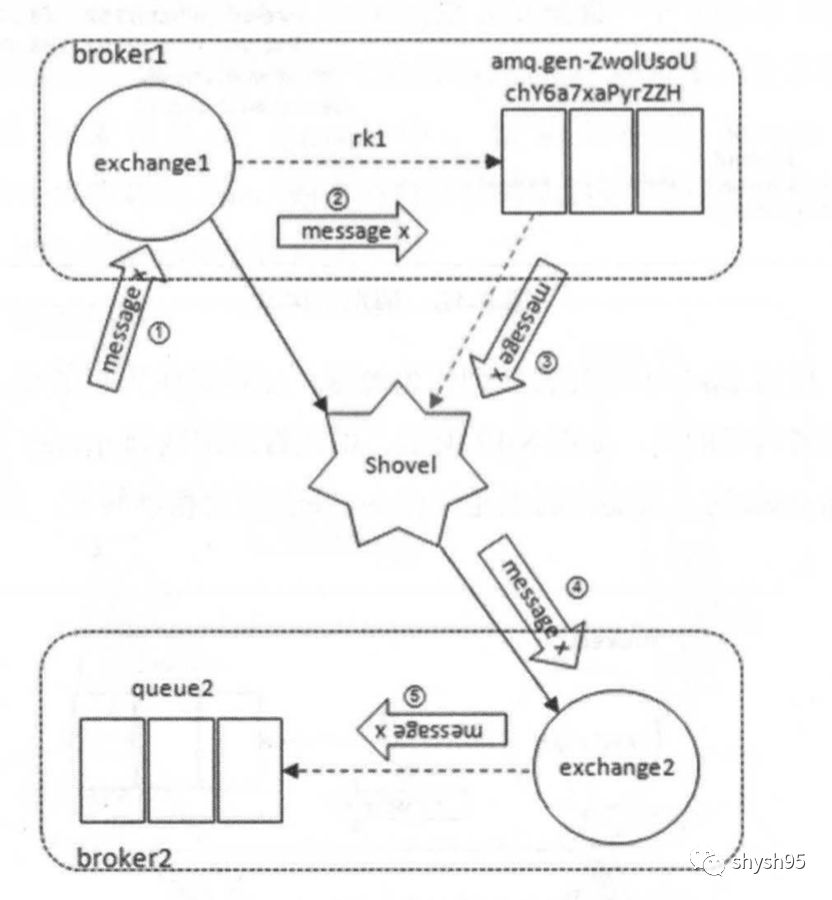 虽然看起来交换器exchange1是通过Shovel link直接将消息转发至exchange2上的,实际上在broker1中会新建一个队列(名称由RabbitMQ自定义,比如上图中的"amq.gen-ZwolUsoUchY6a7xaPyrZZH")并绑定exchange1,消息从交换器exchange1过来先存储在这个队列中,然后Shovel再从这个队列中拉取消息进而转发至交换器exchange2。
虽然看起来交换器exchange1是通过Shovel link直接将消息转发至exchange2上的,实际上在broker1中会新建一个队列(名称由RabbitMQ自定义,比如上图中的"amq.gen-ZwolUsoUchY6a7xaPyrZZH")并绑定exchange1,消息从交换器exchange1过来先存储在这个队列中,然后Shovel再从这个队列中拉取消息进而转发至交换器exchange2。
broker1和broker2中的exchange1、queue1、exchange2及queue2都可以在Shovel成功连接源端或者目的端Broker之后再第一次创建(执行一系列相应的AMQP配置声明时),它们并不一定需要在Shovel link建立之前创建。Shovel可以为源端或者目的端配置多个Broker的地址,这样可以使得源端或者目的端的Broker失效后能够尝试重连到其他Broker之上(随机挑选)。
可以设置reconnect delay参数以避免由于重连行为导致的网络泛洪,或者可以在重连失败后直接停止连接。针对源端和目的端的所有配置声明会在重连成功之后被重新发送。
Shovel插件默认也在RabbitMQ的发布包中,执行rabbitmq-plugins enable rabbitmqshovel命令可以开启Shovel功能,该命令默认也会开启amqpclient插件。要开启Shovel的管理插件,需要执行rabbitmq-plugins enable rabbitmqshovelmanagement命令。
Shovel既可以部署在源端,也可以部署在目的端。有两种方式可以部署Shovel: 静态方式和动态方式。静态方式是指在rabbitmq.config配置文件中设置,而动态方式是指通过Runtime Parameter设置。我们这里讲动态方式配置,基于插件的WEB管理界面进行配置。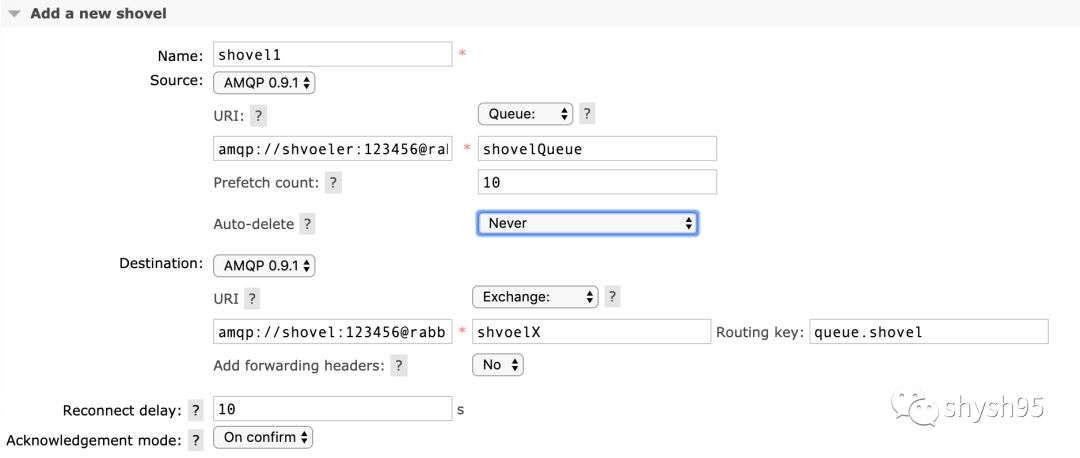
Name:该Shovel配置的名称
Source:Source中需要指定协议类型、连接的源节点地址,源端的类型(队列、交换器,如果是交换器还需要填入routingKey)
Prefetch count:该参数表示Shovel内部缓存的消息条数,可以参考Federation的相关参数。Shovel的内部缓存是源端服务器和目的端服务器之间的中间缓存部分
Auto-delete:默认为Never表示不删除自己,如果设置为After initial length transferred,则再消息转移完成后删除自己。
Destination:Destination需要指定协议类型,连接的目的节点地址,目的端的类型(队列、交换器,如果是交换器还需要填入routingKey)
Add forwarding headers:如果设置为true,则会在转发的消息内添加x-shovelled的header属性
Reconnect delay:指定在Shovel link失效的情况下,重新建立连接前需要等待的时间,单位为秒。如果设置为0,则不会进行重连动作,即Shovel会在首次连接失效时停止工作。默认为5秒。
Acknowledgement mode:参考Federation的配置。no ack表示无须任何消息确认行为;on publish表示Shovel会把每一条消息发送到目的端之后再向源端发送消息确认; on confirm表示Shovel会使用publisher confirm机制,在收到目的端的消息确认之后再向源端发送消息确认。
消息堆积是在使用消息中间件过程中遇到的最正常不过的事情。消息堆积是一把双刃剑,适量的堆积可以有削峰、缓存之用,但是如果堆积过于严重,那么就可能影响到其他队列的使用,导致整体服务质量的下降。
处理消息堆积的整体思路是为集群准备一个备用集群,当在线的集群某个队列消息堆积严重时,则开启Shovel将消息导入到备用机群的某一个,等到在线集群消息堆积状况回暖时,再开启Shovel从备用集群的队列中导入到原集群中的队列。
下图是Federation/Shovel与集群的区别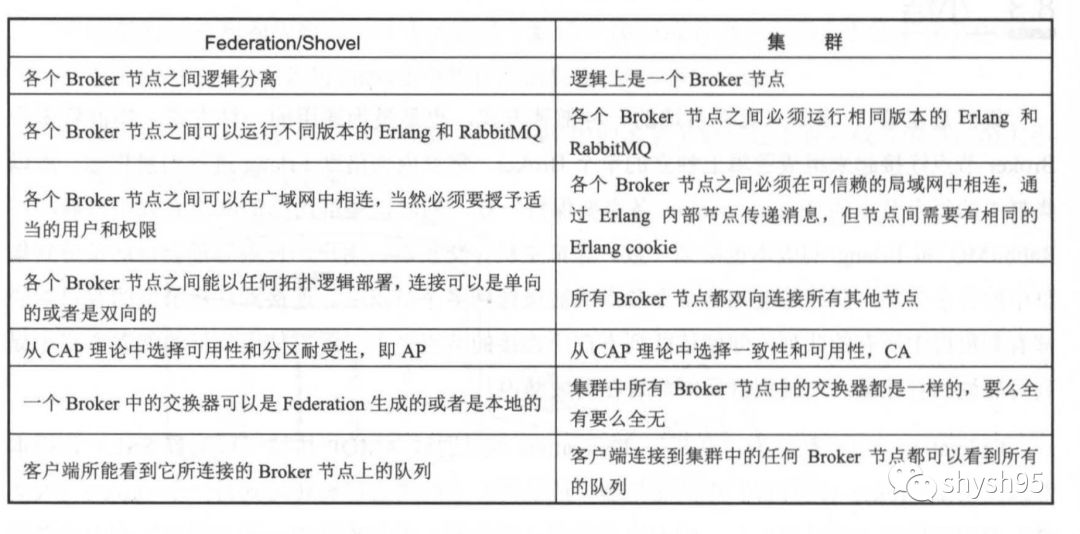
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





