Python3жҖҺд№ҲзҲ¬еҸ–иӢұйӣ„иҒ”зӣҹжүҖжңүиӢұйӣ„зҡ®иӮӨ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іPython3жҖҺд№ҲзҲ¬еҸ–иӢұйӣ„иҒ”зӣҹжүҖжңүиӢұйӣ„зҡ®иӮӨпјҢж–Үз« еҶ…е®№иҙЁйҮҸиҫғй«ҳпјҢеӣ жӯӨе°Ҹзј–еҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҜ№зӣёе…ізҹҘиҜҶжңүдёҖе®ҡзҡ„дәҶи§ЈгҖӮ
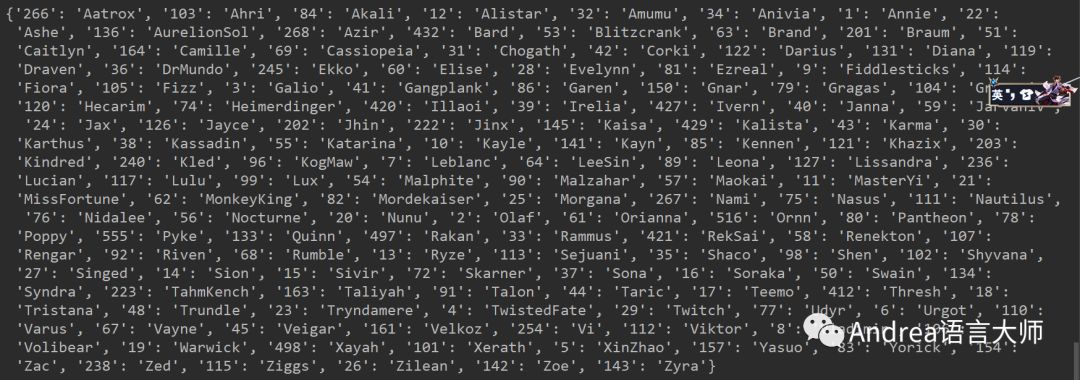
жү“ејҖиӢұйӣ„иҒ”зӣҹе®ҳзҪ‘пјҢзӮ№еҮ»жёёжҲҸиө„ж–ҷпјҢ继з»ӯжҢүF12пјҢжҢүF5еҲ·ж–°пјҢе°ұдјҡеҸ‘зҺ°жңүдёҖдёӘchampion.jsж–Ү件пјҢеӨҚеҲ¶иҝҷдёӘjsж–Ү件зҡ„ең°еқҖ.е’ҢзҺӢиҖ…иҚЈиҖҖдёҚеҗҢпјҢиҝҷдёӘжҳҜjsиҖҢзҺӢиҖ…жҳҜjsonжҜ”иҫғеҘҪеӨ„зҗҶгҖӮjsдёӯжңүиӢұйӣ„зҡ„зј–еҸ·е’ҢеҗҚеӯ—пјҢе°Ҷkeysдёӯзҡ„ж•°жҚ®жӢҝеҮәжқҘ
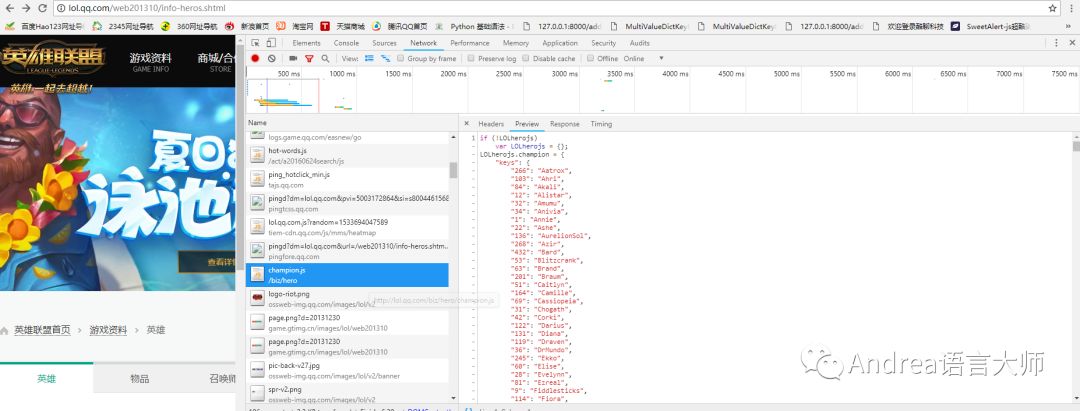
йҖҡиҝҮrequestsзҡ„getж–№жі•иҺ·еҸ–еҲ°е“Қеә”зҡ„еҶ…е®№пјҢpat_jsжҳҜжӯЈеҲҷзҡ„规еҲҷпјҢcompileеҮҪж•°е°ҶеҢ…еҗ«зҡ„жӯЈеҲҷиЎЁиҫҫејҸзҡ„еӯ—з¬ҰдёІеҲӣе»әжЁЎејҸеҜ№иұЎпјҢзӣҙжҺҘи°ғз”Ёfindallж–№жі•гҖӮиҝ”еӣһзҡ„е°ұжҳҜеҢ№й…Қзҡ„еӯ—дёІд»ҘеҲ—иЎЁзҡ„еҪўејҸжҳҫзӨәгҖӮevalе°Ҷе…¶иҪ¬жҚўдёәеӯ—е…ё
def path_js(url_js):
res_js = requests.get(url_js, verify= False).content
html_js = res_js.decode("gbk")
pat_js = r'"keys":(.*?),"data"'
enc = re.compile(pat_js)
list_js = enc.findall(html_js)
dict_js = eval(list_js[0])
print(dict_js)
--------------------------------------------------------------------------------------------------------
еңЁйЎөйқўдёӯзӮ№ејҖиӢұйӣ„иө„ж–ҷпјҢжІЎжңүиӢұйӣ„зҡ„зҡ®иӮӨurlпјҢйңҖиҰҒеҸій”®пјҢеңЁж–°ж ҮзӯҫйЎөжү“ејҖпјҢиҺ·еҸ–еҲ°иҝһжҺҘhttp://ossweb-img.qq.com/images/lol/web201310/skin/big266000.jpg
ж №жҚ®иҺ·еҸ–еҲ°зҡ„й“ҫжҺҘеҲҶжһҗпјҢbigеҗҺеүҚдёүдёӘж•°еӯ—д»ЈиЎЁиӢұйӣ„зҡ„зј–еҸ·пјҢеҗҺдёүдёӘд»ЈиЎЁзҡ®иӮӨзҡ„дёӘж•°пјҢж №жҚ®жӯӨжқҘжӢјжҺҘиҺ·еҸ–зҡ®иӮӨеӣҫзүҮзҡ„й“ҫжҺҘгҖӮжҜҸдёӘиӢұйӣ„зҡ„зҡ®иӮӨдёҚи¶…иҝҮ20дёӘпјҢд»ҘжӯӨжқҘеҫӘзҺҜиҺ·еҸ–жӢјжҺҘгҖӮпјҲиҺ·еҸ–зҡ„й“ҫжҺҘдјҡжңүеӨ§йҮҸзҡ„жІЎжңүе“Қеә”зҡ„й“ҫжҺҘпјү
def path_url(dict_js):
pic_list = []
for key in dict_js:
for i in range(20):
xuhao = str(i)
if len(xuhao) == 1:
num_houxu = "00" + xuhao
elif len(xuhao) == 2:
num_houxu = "0" + xuhao
numStr = key + num_houxu
url = r'http://ossweb-img.qq.com/images/lol/web201310/skin/big' + numStr + '.jpg'
pic_list.append(url)
print(pic_list)
return pic_list

й“ҫжҺҘиҺ·еҸ–еҲ°д№ӢеҗҺпјҢејҖе§Ӣж №жҚ®й“ҫжҺҘжқҘдёӢиҪҪзҡ®иӮӨ
е…Ҳз”ҹжҲҗж–Ү件зҡ„дҝқеӯҳи·Ҝеҫ„
'''
ж №жҚ®еӯ—е…ёзҡ„valueеҖјиҺ·еҸ–иӢұйӣ„еҗҚеӯ—пјҢе°Ҷе…¶дҪңдёәж–Ү件еҗҚе’Ңдҝқеӯҳи·Ҝеҫ„
'''
def name_pic(dict_js, path):
list_filePath = []
for name in dict_js.values():
for i in range(20):
file_path = path + name + str(i) + '.jpg'
list_filePath.append(file_path)
print(list_filePath)
return list_filePath

жҺҘдёӢжқҘе°ұжҳҜдёӢиҪҪеӣҫзүҮпјҢе°ҶеӣҫзүҮеҶҷе…Ҙж–Ү件гҖӮпјҲи§ЈеҶіеӨ§йҮҸжІЎжңүе“Қеә”зҡ„й“ҫжҺҘпјүиҝҳжҳҜйҖҡиҝҮrequestsзҡ„getж–№жі•иҺ·еҸ– е“Қеә”пјҢеҰӮжһңе“Қеә”зҡ„textзҡ„еҶ…е®№жҳҜ404пјҢеҲҷз»“жқҹжң¬ж¬ЎеҫӘзҺҜпјҢеҰӮжһңдёҚжҳҜеҲҷе°ҶиҜҘеӣҫзүҮеҶҷе…Ҙж–Ү件дҝқеӯҳгҖӮиҝҷж ·е°ұдёҚдјҡдёӢиҪҪеӨ§йҮҸзҡ„дёҚиғҪжү“ејҖзҡ„з©әеӣҫзүҮ
def writing(url_list, list_filePath):
try:
for i in range(len(url_list)):
res = requests.get(url_list[i], verify=False)
if '404 page not found' in res.text:
print("иҜҘиӢұйӣ„зҡ®иӮӨдёӢиҪҪе®ҢжҜ•"), i
continue
with open(list_filePath[i], "wb") as f:
f.write(res.content)
except Exception as e:
print("дёӢиҪҪеӣҫзүҮеҮәй”ҷ,%s" % (e))
return False


иҺ·еҸ–еҲ°996дёӘзҡ®иӮӨ
иҮіжӯӨпјҢзҡ®иӮӨиҺ·еҸ–е®ҢжҜ•гҖӮеҪ“然иҝҳеҸҜд»ҘдјҳеҢ–пјҢеҸҜд»Ҙе°қиҜ•дҪҝз”ЁеӨҡзәҝзЁӢж”№иҝӣиҜҘзЁӢеәҸпјҢеӣҫзүҮеӨӘеӨҡпјҢеҚ•зәҝзЁӢиҝҮж…ўгҖӮиҝҳжңүзҡ®иӮӨй“ҫжҺҘзҡ„з”ҹжҲҗй—®йўҳпјҢиҖғиҷ‘жҳҜеҗҰжңүжӣҙеҘҪзҡ„и§ЈеҶіеҠһжі•пјҢдёҚдјҡеҺ»з”ҹжҲҗеӨ§йҮҸж— з”Ёзҡ„й“ҫжҺҘгҖӮзЁӢеәҸдјҡеҺ»иҜ·жұӮиҝҷдәӣж— з”Ёзҡ„й“ҫжҺҘпјҢйҖ жҲҗеӨ§йҮҸиө„жәҗжөӘиҙ№гҖӮ
е…ідәҺPython3жҖҺд№ҲзҲ¬еҸ–иӢұйӣ„иҒ”зӣҹжүҖжңүиӢұйӣ„зҡ®иӮӨе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





