本篇文章为大家展示了Bytes型数据decode时是为什么要把几位数据组合在一起的,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
大家在开发 Python 的过程中,经常会进行字符串encode为 Bytes型数据,或者把 Bytes 型数据 decode为字符串的操作。例如:
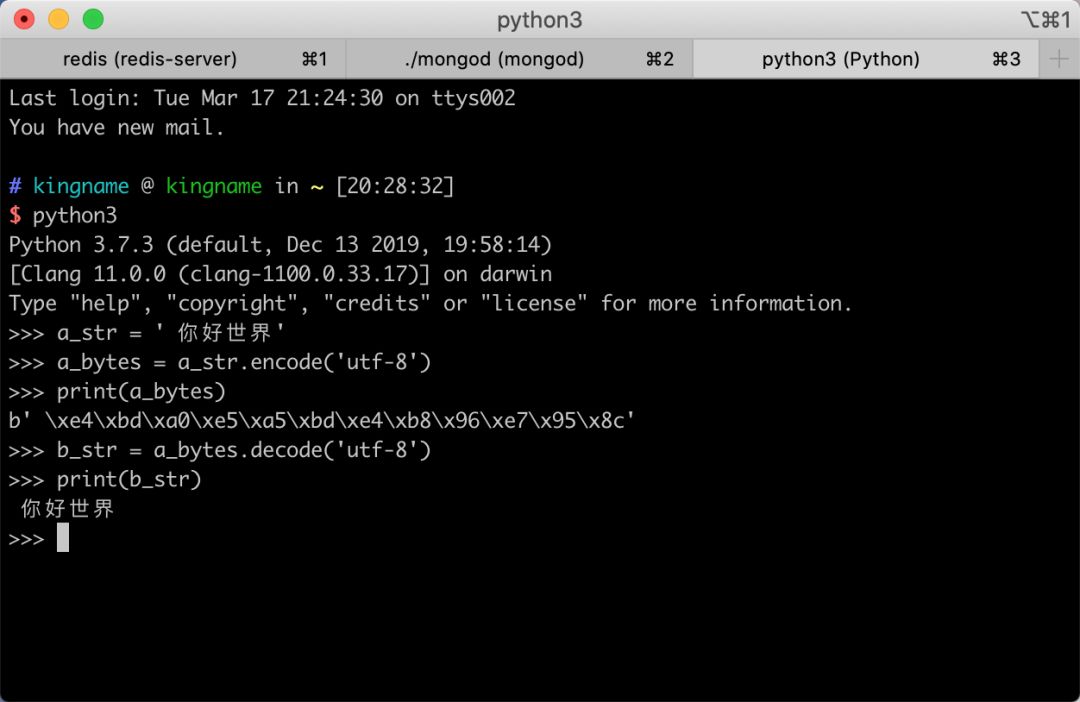
我们知道,在 Unicode 编码中,中文占3个字节,所以一个中文字符编码为 Bytes 型数据以后,会占用3个 Bytes 字符,例如:
>>> a = '青'
>>> a.encode()
b'\xe9\x9d\x92'
>>> b = '青南'
>>> b.encode()
b'\xe9\x9d\x92\xe5\x8d\x97'
注意这里的\xe9需要作为整体来看待,表示一个16进制数。
所以,当我要把 Bytes 型数据\xe9\x9d\x92\xe5\x8d\x97 转为字符串时,Python 会把\xe9\x9d\x92转成青字,把\xe5\x8d\x97转成南字,看起来,似乎是 Python 知道应该把每3个 Bytes 符号一组来进行处理。
然而,Unicode 中,emoji 表情是4个字节,例如表情符号:????,它对应的 Bytes 型数据为:\xf0\x9f\xa4\x94,如下图所示:

如果我把青????南转换为 Bytes 型数据,值为:\xe9\x9d\x92\xf0\x9f\xa4\x94\xe5\x8d\x97,如下图所示,一共10个 Bytes 字符:
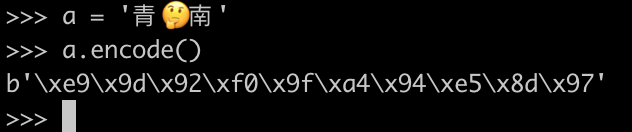
那么问题来了,当我对这个 Bytes 型数据进行 decode 的时候会怎么样呢?如下图所示:

Python 可以正确地把 Bytes 数据划分为:
\xe9\x9d\x92 对应“青”
\xf0\x9f\xa4\x94 对应“????”
\xe5\x8d\x97 对应“南”
为什么 Python 知道要把\xf0\x9f\xa4\x94这4个符号分到一组?为什么不会像下面这样分组?
\xe9\x9d\x92
\xf0\x9f\xa4
\x94\xe5\x8d\x97
实际上,这个问题的原因,只有当我们用二进制来看的时候,才能发现端倪。
青对应的第一个 Bytes 字符\xe9,其中的e9是一个十六进制数字,把它转成十进制是233,转成二进制是11101001。
南对应的第一个 Bytes 字符\xe5,其中的e5是一个十六进制数字,把它转成十进制是229,转成二进制是11100101。
????对应的第一个 Bytes 字符\xf0,其中的f0是一个十六进制数字,把它转成十进制是240,转成二进制是11110000。
如果还看不出他们的差异,那我们把他们放在一起对比一下:
11101001
11100101
11110000
看出差异了吗?中文汉字是三个字节,转换为 Bytes 型数据以后,第一个字符对应的二进制数是1110开头。emoji 是4个字节,转换为 Bytes 型数据以后,第一个字符对应的二进制数是1111开头。
所以,当给定一个 Bytes 型数据需要给 Python 来转换为字符串的时候,Python 是这样判断应该有几个字符一组的。
\xe9\x9d\x92\xf0\x9f\xa4\x94\xe5\x8d\x97青字。\xf0,发现它对应的二进制数高4位是1111,所以这个字符和接下来3个字符(合计4个字符)一组,解析出
????。\xe5,对应的二进制高4位是1110,因此这个字符和接下来的两个字符一组进行解析,得到
南。对于数字和英文字母,在 Unicode 里面只使用一个字节来表示,他们的 Ascii 码小于128。而多字节的 Unicode 字符,都是从129开头的,所以英文字母数字与中文混合生成的 Bytes 型数据,在解码的时候也不会出现分组不明确的问题。
上述内容就是Bytes型数据decode时是为什么要把几位数据组合在一起的,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





