这篇文章将为大家详细讲解有关Disruptor的共享与缓存是怎样的,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
下图是计算的基本结构。L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核;L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享。
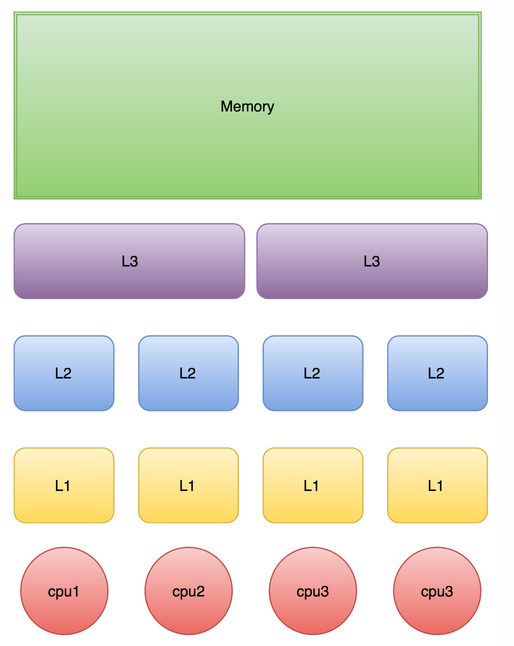
图3 计算机CPU与缓存示意图
当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。
另外,线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。
下面是从CPU访问不同层级数据的时间概念:
| 从CPU到 | 大约需要的CPU周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80ns | |
| QPI 总线传输(between sockets, not drawn) | 约20ns | |
| L3 cache | 约40-45 cycles | 约15ns |
| L2 cache | 约10 cycles | 约3ns |
| L1 cache | 约3-4 cycles | 约1ns |
| 寄存器 | 1 cycle |
可见CPU读取主存中的数据会比从L1中读取慢了近2个数量级。
Cache是由很多个cache line组成的。每个cache line通常是64字节,并且它有效地引用主内存中的一块儿地址。一个Java的long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。
CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。
在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此你能非常快的遍历这个数组。事实上,你可以非常快速的遍历在连续内存块中分配的任意数据结构。
下面的例子是测试利用cache line的特性和不利用cache line的特性的效果对比。
package com.meituan.FalseSharing;
/**
* @author gongming
* @description
* @date 16/6/4
*/
public class CacheLineEffect {
//考虑一般缓存行大小是64字节,一个 long 类型占8字节
static long[][] arr;
public static void main(String[] args) {
arr = new long[1024 * 1024][];
for (int i = 0; i < 1024 * 1024; i++) {
arr[i] = new long[8];
for (int j = 0; j < 8; j++) {
arr[i][j] = 0L;
}
}
long sum = 0L;
long marked = System.currentTimeMillis();
for (int i = 0; i < 1024 * 1024; i+=1) {
for(int j =0; j< 8;j++){
sum = arr[i][j];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
marked = System.currentTimeMillis();
for (int i = 0; i < 8; i+=1) {
for(int j =0; j< 1024 * 1024;j++){
sum = arr[j][i];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
}
}在2G Hz、2核、8G内存的运行环境中测试,速度差一倍。
结果: Loop times:30ms Loop times:65ms
ArrayBlockingQueue有三个成员变量: - takeIndex:需要被取走的元素下标 - putIndex:可被元素插入的位置的下标 - count:队列中元素的数量
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。

图4 ArrayBlockingQueue伪共享示意图
如上图所示,当生产者线程put一个元素到ArrayBlockingQueue时,putIndex会修改,从而导致消费者线程的缓存中的缓存行无效,需要从主存中重新读取。
这种无法充分使用缓存行特性的现象,称为伪共享。
对于伪共享,一般的解决方案是,增大数组元素的间隔使得由不同线程存取的元素位于不同的缓存行上,以空间换时间。
package com.meituan.FalseSharing;
public class FalseSharing implements Runnable{
public final static long ITERATIONS = 500L * 1000L * 100L;
private int arrayIndex = 0;
private static ValuePadding[] longs;
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
for(int i=1;i<10;i++){
System.gc();
final long start = System.currentTimeMillis();
runTest(i);
System.out.println("Thread num "+i+" duration = " + (System.currentTimeMillis() - start));
}
}
private static void runTest(int NUM_THREADS) throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
longs = new ValuePadding[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new ValuePadding();
}
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = 0L;
}
}
public final static class ValuePadding {
protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
protected long p9, p10, p11, p12, p13, p14;
protected long p15;
}
public final static class ValueNoPadding {
// protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
// protected long p9, p10, p11, p12, p13, p14, p15;
}
}在2G Hz,2核,8G内存, jdk 1.7.0_45 的运行环境下,使用了共享机制比没有使用共享机制,速度快了4倍左右。
结果: Thread num 1 duration = 447 Thread num 2 duration = 463 Thread num 3 duration = 454 Thread num 4 duration = 464 Thread num 5 duration = 561 Thread num 6 duration = 606 Thread num 7 duration = 684 Thread num 8 duration = 870 Thread num 9 duration = 823
把代码中ValuePadding都替换为ValueNoPadding后的结果: Thread num 1 duration = 446 Thread num 2 duration = 2549 Thread num 3 duration = 2898 Thread num 4 duration = 3931 Thread num 5 duration = 4716 Thread num 6 duration = 5424 Thread num 7 duration = 4868 Thread num 8 duration = 4595 Thread num 9 duration = 4540
备注:在jdk1.8中,有专门的注解@Contended来避免伪共享,更优雅地解决问题。
关于Disruptor的共享与缓存是怎样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





