这篇文章主要讲解了“Kafka的知识点有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Kafka的知识点有哪些”吧!
kafka具有高吞吐量、低延时的主要原因有三个:
一是其在每次写入数据时只是将数据写入到操作系统的页缓存中,这就相当于只是在内存中写入数据,而繁杂的磁盘IO工作则交由操作系统自行进行;
二是kafka在写入数据的时候是采用追加的方式写入到磁盘中的,这种方式省略了磁头的随机移动而产生的随机IO,其效率甚至比内存的随机读取都要高;
三是在为kafka配置了较大的页缓存时,数据大部分的数据读取和写入工作都直接在页缓存中进行了,读取和写入的时候甚至不需要进行磁盘的IO工作,而磁盘的IO也只在操作系统将数据从页缓存写入到磁盘中才会进行。
kafka使用的零拷贝技术是通过操作系统的sendfile指令来实现的。在正常情况下,数据从磁盘读取然后发送到网卡中需要经过如下步骤:
在这个过程中,数据的复制总共发生了四次,其中与DMA相关的有两次,分别是从磁盘上读取文件数据到内核缓存和将数据从socket相关的内核缓存复制到网卡中,这两次复制是不可避免的。但是在数据在内核态与用户态之间的两次拷贝则非常的消耗CPU的资源,这两次也是可以避免的,而零拷贝技术就是省去了这两次的拷贝过程,从而将CPU给释放出来,以节约资源。sendfile指令指的是,在DMA将磁盘数据拷贝到内核态缓存之后,其会将该缓存中数据的地址值直接当做网络相关的内核态的缓存地址,从而直接从该缓存中通过DMA技术将数据写入到网卡中。通过这种方式就省去了数据在内核态与用户态之间的来回复制。
首先通过DMA(Direct Memory Access)直接存储器访问技术读取磁盘上的文件数据,将其存储到操作系统内核态缓存中;
然后CPU会将内核态的缓存读取到应用程序的缓存中;
应用程序获取到数据之后,会将该数据写入到socket相关的内核态缓存中;
最后通过DMA技术将内核态缓存中的数据发送到网卡中。
有了消息的持久化,kafka实现了高可靠性;有了负载均衡和使用文件系统的独特设计,kafka实现了高吞吐量;有了故障转移,kafka实现了高可用性。
kafka的topic本质上指的是一类消息,其可以理解为消息的目标存储地址,并且kafka并没有采用topic-message的二级存储结构,而是采用了topic-partition-message的三级存储结构。这样做的原因在于能够分散数据到不同的partition上,然后将partition分散到不同的物理机器上,这样就达到了负载均衡提升系统吞吐量的目的。如下是topic-partition-message的三级存储结构的示意图:
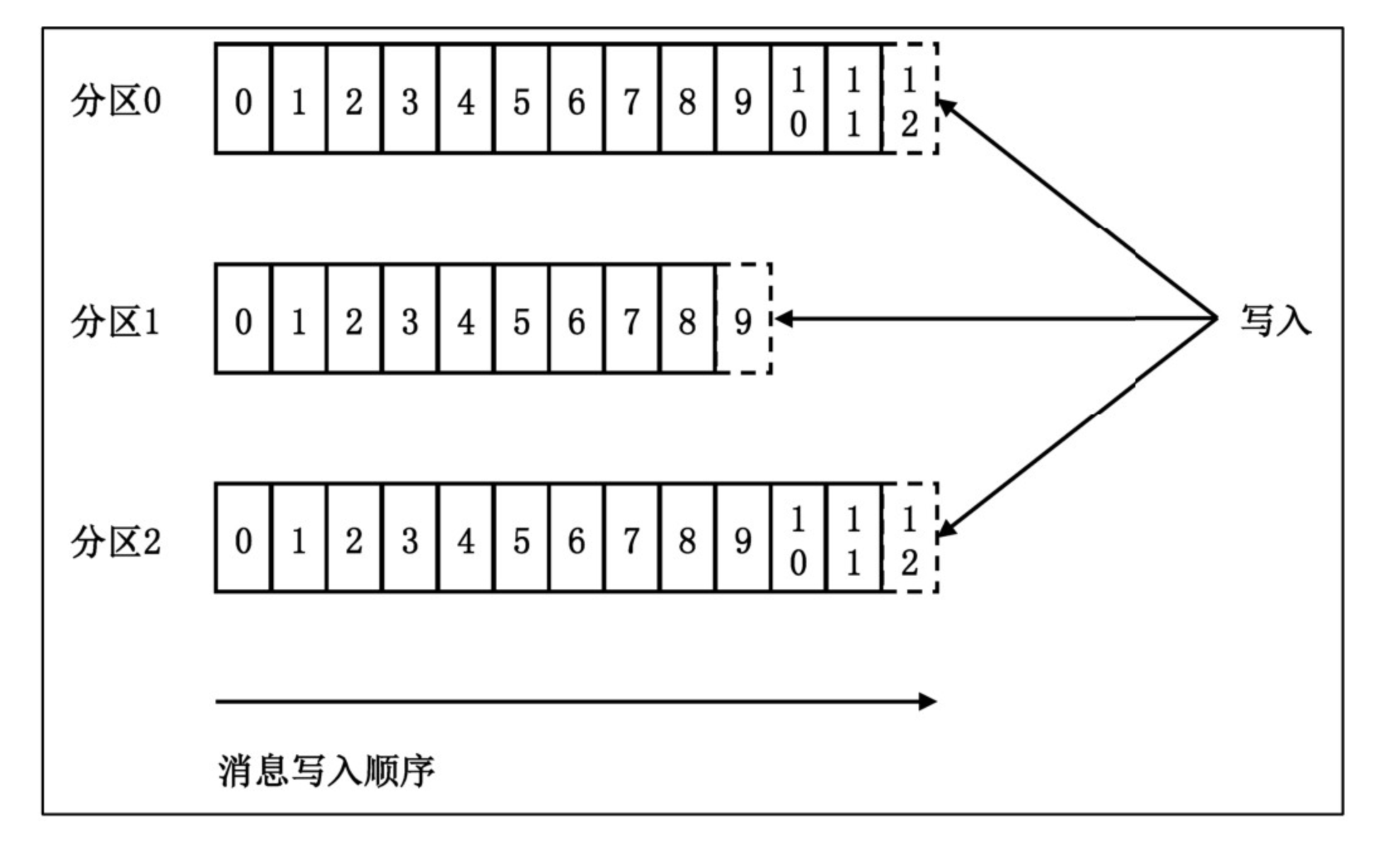
kafka中每个消息都会被分配一个位移offset,这个位移指的是该消息在当前partition中的一个偏移量,对于每个新增的数据,其位移是依次增加的。在consumer端也有一个位移的概念,这个位移指的是该consumer在当前partition中所消费的一个位置,其一定是小于等于该partition中最新的消息的位移的。
根据配置,kafka的每个partition都可以设置一个或多个副本,这些副本分为leader和follower,leader副本会对外提供写入和读取消息的功能,而follower只会从leader副本上读取数据并保存下来,其不对外提供服务。另外,kafka会保证一个partition的多个副本被平均的分配到多个服务器上。通过这种方式,kafka就实现了服务的高可用,当leaderpartition所在的机器宕机之后,kafka就会在follower副本中选举出一个作为leader并对外提供服务。在副本中,还有一个ISR的概念,所谓的ISR就是in-sync-replica,也就是处于完全同步状态的副本,有这个概念的原因主要是follower在同步leader的数据的时候,可能由于网络等原因导致数据不是完全同步的,这个时候leader就会通过ISR来标记哪些副本是处于完全同步状态的,这样在leader宕机的时候,就只会在处于ISR状态的副本中选举新的leader,从而保证数据的一致性。
对于kafka硬盘的规划建议点:
追求性价比的公司可以使用JBOD磁盘;
使用机械硬盘完全可以满足kafka集群的使用,SSD更好。
磁盘大小规划的影响因素:
新增消息数
消息留存时间;
平均消息大小;
副本数;
是否启用压缩;
对于内存大小设置的建议:
尽量分配更多的内存给操作系统的page cache;
不要为broker设置过大的堆内存,最好不超过6GB;
page cache大小至少要大于一个日志段的大小;
对CPU规划的建议:
使用多核系统,CPU数最好大于8;
如果使用kafka 0.10.0.0之前的版本或clients端与broker端消息版本不一致,则考虑多配置一些资源以防止消息解压缩操作消耗过多的CPU。
对带宽资源规划的建议:
尽量使用高速网络;
根据自身网络条件和带宽来评估kafka集群机器数量;
避免使用跨机房网络。
broker参数
broker.id:该参数指的是当前broker的id,每个broker的id不能重复,建议读者自行指定该参数,数值从0依次网上增长即可,如果不指定该参数,那么broker将会自动生成一个随机数;
log.dirs:该参数指定了kafka持久化消息的目录,建议读者根据自己的磁盘数量来指定相应的目录数,这是因为每个磁盘都有一个磁头,指定相同数量的目录之后,kafka写入日志就可以利用多个磁头并行的写入;
zookeeper.connect:该参数指定了zookeeper服务器的地址,多个地址可以用逗号隔开,形如zk1:port1,zk2:port2,zk3:port3;
listeners:broker监听器列表,格式为[协议]://[主机名]:[端口],[协议]://[主机名]:[端口]。该参数主要用于客户端连接broker使用,可以认为是broker端开放给clients的监听端口;
advertised.listeners:和listeners类似,该参数也是用于发布给clientss的监听器,不过该参数主要用于IaaS环境;
unclean.leader.election.enable:是否开启unclean leader选举,所谓的unclean leader指的是在leader宕机时,会从ISR中选举一个follower作为新的leader,但是如果ISR中为空的,说明所有的replica都处于未同步状态,而unclean leader选举指的就是在这种情况下,是否使用这种未同步状态的replica作为新的leader;
delete.topic.enable:是否允许kafka删除topic,默认是开启的,也建议开启,因为控制是否删除可以通过权限来进行;
log.retention.{hours|minutes|ms}:该参数指定了每个partition的日志的留存时间,默认是7天,超过7天的日志将会被自动删除,这个参数中的三个选项如果同时配置,那么优先级是ms>minutes>hours;
log.retention.bytes:指定了每个消息日志最多保存多大的数据,对于超过该参数的分区日志而言,其会被自动删除,该参数默认值为-1;
min.insync.replicas:该参数指定了broker最少响应client消息发送的最少副本数。需要注意的是,该参数不能设置得与当前broker副本数一样,比如当前副本有3个,如果设置为3,那么客户端发送的消息必须在3个副本中都保存才算保存成功,此时如果某个副本宕机了,那么客户端写入消息之后就始终不会有目标数量的副本数响应,因而该消息始终无法写入成功。该参数还可以与客户端的acks参数配合使用以达到消息持久保存,并且需要注意的是,该参数只有在客户端的acks参数指定为-1时才有效;
num.network.threads:指定了broker在后台用于处理网络请求的线程数,默认为3。需要注意的是,这里的“处理”其实只是负责转发请求,它会将接收到的请求转发到后面的处理线程中,在真实环境中可以通过NetworkProcessorAvgIdlePercent JMX指标来监控,如果该值持续低于0.3,建议适当提高该参数的值;
num.io.threads:这个参数控制了broker端实际处理网络请求的线程数,默认值是8,可以通过Request HandlerAvgIdlePercent JMX指标来监控该数据,如果持续低于0.3,则可以考虑适当增加该参数值;
message.max.bytes:该参数指定了每条消息的最大字节数,默认为977KB,真实环境中一般没有这么大的消息。
topic级别参数
delete.retention.ms:每个topic设置自己的日志留存时间,以覆盖全局默认值;
max.message.bytes:每个topic设置自己的消息最大字节数,以覆盖全局默认值;
retention.bytes:每个topic设置自己的日志留存大小,以覆盖全局默认值。
GC参数
建议使用G1 GC;
JVM参数
主要是关于堆内存大小的,因为kafka主要使用的是堆外内存,因而建议堆内存不要超过6GB;
OS参数
文件描述符限制:由于kafka对打开大量的文件,因而建议将kafka的文件描述符限制设置一个比较大的值,命令如:ulimit -n 100000;
socket缓冲区大小:一般的内网环境的socket缓冲区大小为64KB,这对于内网是完全足够的,因为内网的往返时间RTT是非常短的,但是如果消息要经过长距离传输,那么建议提升该值,比如128KB,以防止数据堆积;
最好使用Ext4或者XFS文件系统:使用这种文件系统会提供更好的写入性能,尤其是XFS文件系统;
关闭swap:降低对swap空间的使用,命令为sysctl vm.swappiness=<一个较小的数>;
设置更长的flush时间:默认情况下,OS的刷盘时间是5s,但是这个事件太短了,建议提升该值为2分钟,以更大程度的提升OS物理写入操作的性能。
Producer在发送消息时,其会根据一定的分区筛选策略来选择将当前消息发送到哪个分区。如果当前消息中指定了key,那么就会根据这个key的hash值将该消息发送给某个分区,也就是说具有同一个key的所有消息将会发送到同一个分区。如果当前消息没有key,那么就会采用轮询的方式,依次将消息均匀的发送给各个分区。
kafka的producer的工作流程如下:

首先,producer会将消息封装到一个ProducerRecord中,然后根据设置的序列化器将其序列化为二进制数据,并且将其放置到producer端的一个消息缓冲池中;接着,另一个线程会不断的从消息缓冲池中批量的读取数据,将其封装在一起后一次性的发送给broker进行处理;处理完成之后,由broker返回处理结果,如果某个消息处理失败,那么就户根据设置的重试次数,对其进行重试;如果没有失败,则将消息结果返回给客户端线程。
在发送消息的时候可以指定消息的时间戳,但是建议producer不要设置该参数,因为kafka保存消息是严格按照时间戳顺序来排列的,如果随意指定时间戳,那么可能会导致消息混乱,从而找不到消息,并且也可能会影响消息的保存策略。
Kafka的producer的异步回调函数中有一个异常参数,该异常分为可重试异常和不可重试异常。可重试异常主要有以下几类:
不可重试的异常主要有以下几类:
RecordTooLargeException:发送的消息尺寸过大,超过了规定的大小上线,这种异常一般重试之后也是无法恢复的;
SerializationException:序列化异常,重试无法恢复;
KafkaException:其他类型的异常。
NetworkException:网络瞬时故障引起的异常,可重试;
LeaderNotAvailableException:这种异常一般发生在leader换届选举的时候,一般重试之后就会恢复;
NotControllerException:当前的controller不可用,一般发生在controller换届选举的时候,重试之后可恢复;
producer的关闭有两种方法:不带超时时间的和带超时时间的close()方法。不带超时时间的close()方法会等待之前发送的所有的消息都处理完毕之后再关闭,而带超时时间的close()方法则需要指定一个超时时间,如果在超时时间结束了,消息还未处理完毕,那么就会终止所有的消息发送,这种情况下是可能丢失消息的。
producer端主要参数:
重试可能会造成消息的重复发送。比如某个消息已经成功写入到了broker端,但是由于网络抖动,导致producer端没有接收到响应,或者响应超时,那么producer会尝试重新发送该消息,这样就会产生重复消息。在kafka 0.11.0.0版本中已经开始支持”精确一次“的处理语义;
重试可能会造成消息的乱序。在producer发送消息的时候,默认是会将5条消息作为一个批次进行发送,但是如果其中某个消息写入失败,而其余四条消息写入成功,此时该消息就会被重试,这种情况下,本来应该在该消息后面的消息反而被保存在了该消息前面。
bootstrap.servers:该参数指定了当前kafka服务器的地址,格式如:ip1:port1,ip2:port2,ip3:port3;
key.serializer:该参数指定了key的序列化器,必须是类的全限定名;
value.serializer:该参数指定了value的序列化器,必须是类的全限定名;
acks:这个参数的主要作用是控制producer发送消息后对消息可靠性的管理级别。若设置为0,则表示producer发送消息后,不管消息是否发送成功,即使发生任何异常也无法接收到该异常,这种情况下,消息的可靠性是最低的,但是吞吐量最高;若设置为1,则表示消息发送后,只要在接收消息的broker上成功写入该消息,并且返回响应之后即可进行后续的操作,这个情况下,消息的可靠性和吞吐量都适中,因为写入消息的broker如果宕机,那么消息还是会丢失的;若设置为all或-1,则表示当前消息会被写入到接收消息的broker的日志中,并且还会等待所有ISR集合中的副本都写入日志成功之后才返回响应,这种情况下,消息的可靠性是最高的,但是吞吐量最低。
buffer.memory:该参数指定了当前producer所使用的发送缓冲区的大小;
compression.type:该参数指定了producer端压缩消息的类型,可选择的有GZIP、Snappy和LZ4。这三种压缩方式中,LZ4的效率是最好的。如果为消息设置了压缩类型,这将会显著的减少网络IO的开销,但是会增加producer端的CPU负担。另外需要注意的是,如果producer端和broker端设置的压缩类型不同,那么broker端就会对消息进行解压缩,然后又进行压缩后再保存,这将增加broker的CPU负担。
retries:该参数指定了在producer端发生了诸如网络抖动或leader选举等可重试异常时进行重试的次数。该参数的默认值为0,即不进行重试,建议设置为一个比0大的数,比如3。需要注意的是,设置了重试次数之后,可能会造成两个问题:
max.in.flight.requests.per.connection:指定了在给broker发送消息时,同一时刻发送的请求数量,如果指定为1,那么producer一次就只会发送一个请求;
retry.backoff.ms:在进行重试时,producer会等待一段时间再进行重试,以防止过多的重试对broker造成负担,该参数就是指定这个重试时间间隔的,默认为100ms,建议设置得比当前kafka集群中分区leader选举的时间稍微长一点,因为这种选举是最频繁的;
batch.size:在producer发送消息的时候,会缓存一个批次的消息后再发送该消息,该参数就指定了这个缓冲区的大小的,默认是16384,即16KB,这是一个比较保守的数字,建议稍微提高一些该参数,因为一个适当的缓冲区大小将会极大的提升系统的吞吐量;
linger.ms:在producer发送消息的时候,有的时候并不会等待一个batch都满了才发送消息,因为这可能造成极大的延迟,而是会在等待一个时间间隔之后就直接发送这个batch的消息。默认情况下,该参数值为0,表示消息需要被立即发送,但是这样会拉低系统的吞吐量,为其设置一个适当的值可以提升系统的吞吐量。
max.request.size:该参数指定了producer发送请求的大小,默认为1048576;
request.timeout.ms:该参数指定了producer发送消息后等待broker响应的超时时间,默认为30S;
自定义Partition的步骤如下:
首先定义一个类实现Partitioner接口;
然后在Producer的Property中配置partitioner.class属性,值为自定义Partitioner的类的全限定名。
自定义producer的serializer的步骤:
定义数据对象格式;
创建自定义序列化类,实现org.apache.kafka.common.serialization.Serializer接口,在serializer方法中实现序列化逻辑;
在用于构造KafkaProducer的Properties对象中设置key.serializer或value.serializer。
自定义producer的拦截器使用步骤:
onSend():该方法会保证在消息被序列化以计算分区之前调用,主要是做一些消息发送前的处理工作;
onAcknowledgement():该方法主要是在消息被应答之前或者消息发送失败时调用,并且通常是在producer回调逻辑触发之前调用;
close():该方法主要是关闭interceptor时触发,作用是进行一些清理工作。
创建拦截器类,实现org.apache.kafka.clients.producer.ProducerInterceptor接口,其有三个方法:
在构造KafkaProducer的Properties对象中设置interceptor.classes属性,值为元素为ProducerInterceptor的list。
Producer端的消息可靠性保证。在Producer端发送消息的时候,kafka会将消息放到一个batch里,然后进行整批数据进行发送,那么这就会产生一个时间窗口,若在这个窗口内producer宕机,那么就有可能丢失消息。producer的这种批量发送的机制会产生两个问题:
producer端的无消息丢失配置如下:
block.on.buffer.full=true # 该参数的目的主要是在producer的发送缓冲区满的时候,必须等到缓冲区的数据处理完毕才会开始下一个批次的消息处理 acks=all or -1 # 该参数的作用是控制broker只有在所有的ISR中的副本都写入消息完毕才会发送响应给producer retries=Integer.MAX_VALUE # 该参数指定了重试次数,这样可以保证可重试的消息一定会写入成功,而对于不可重试的异常,kafka会将其直接返回 max.in.flight.requests.per.connection=1 # 该参数指定了producer同一时刻只会给一个broker发送消息,并且会等待该消息处理完毕 使用带回调机制的send()发送消息,即KafkaProducer.send(record, callback); # 使用这种机制是因为可以通过这种方式来确保消息处理完成,这里一定不能使用不带任何参数的send()方法,因为该方法是一个异步方式,其无法保证消息的顺序性 Callback逻辑中显示地立即关闭producer,使用close(0) # 在Callback中显示的调用close(0)方法可以保证producer不会将未完成的消息发送出去 unclean.leader.election.enable=false # 关闭该参数可以保证broker在宕机重新选举时,不会将没有完全同步的broker副本选为新的leader,因为这样会导致消息丢失 replication.factor=3 # 该参数指定了每个topic的副本数 min.insync.replicas=2 # 该参数指定了ISR中至少需要有多少个副本处于同步状态,其必须大于1,因为1个的时候表示只有leader副本,需要注意的是,只有producer的acks为-1或者all时该参数才有效 replication.factor > min.insync.replicas # 这种配置可以保证当前分区的副本数大于等于ISR中的副本数,这样就可以允许至少一个或多个副本宕机,否则,如果某个副本宕机,那么如果producer设置的acks为-1或all时,始终没法保证ISR中的数量达到目标副本数 enable.auto.commit=false # 设置自动提交为false,这样可以保证消费者消费完成之后再提交消费信息
如果在发送batch数据之前producer宕机,那么就会丢失这一部分数据;
如果在发送batch数据的过程中,某个数据发送失败了,该消息就会被重试,而其后面成功发送的数据是不会重试的,因而如果重试后成功,那么这条本应该在前面的消息,其就会排到后面了;
producer端的时间消耗主要发生在压缩上,而压缩的效率与batch的大小是有一定关系的。batch大小越大,压缩时间就越长,不过时间的增长不是线性的,而是越来越平缓的。如果发现压缩很慢,说明系统的瓶颈在用户主进程而不是IO线程,因此可以考虑增加多个用户线程同时发送消息,这样通常能显著的提升producer的吞吐量。
消费者组:消费者所使用一个消费者组名(即group.id)来标记自己,topic的每条消息都只会被发送到每个订阅它的消费者组的一个消费者实例上。
消费者组的要点:a. 一个consumer group可能有若干个consumer实例(一个group只有一个示例也是允许的);b. 对于同一个group而言,topic的每条消息只能被发送到group下的一个consumer实例上;③topic消息可以被发送到多个group中。
对于使用consumer group的优点,其主要是实现消费者的高伸缩性、容错性的目的。在正常情况下,消费者组里的消费者会被平均的分配各个partition以进行消息的消费,当某个消费者宕机时,consumer group会将已经崩溃的消费者所消费的分区分配给其他的消费者进行消费,通过这种方式实现集群容错。如果某个topic的消息比较多,分区数也比消费者数量多,此时如果消费者处理速度比生产者生产消息的速度低,那么就会出现消息积压的情况,此时就可以通过增加消费者数量的方式提升消费效率,只需要将新加入的消费者实例的groupId指定为当前产生积压的group的id即可,consumer group就会自动将多余的分区分配给该实例。这里说的这两种重分配partition的方式称为再平衡。
kafka将保存位移信息没有保存在zookeeper的原因有两点:①zookeeper本质上是一个分布式的服务协调工具,其不适合做数据存储服务;②zookeeper对于读的性能是非常高的,但是写性能比较低,而对于kafka这种需要频繁写入消费进度的场景,其是不适合的。在新版本中,kafka将每个topic的消费进度都保存在了一个特殊的topic下,即__consumer_offsets。
kafka将位移信息提交到__consumer_offsets这个topic下的原理如下:首先consumer会将其要提交的信息组成一个KV形式的消息,其key是groupId+topic+partition的一个字符串连接的形式,其值则为当前的偏移量;然后在消息发送到该topic之后,这个topic会对消息进行压实处理,也就是说,会取每个key下面的最大的value,而只保存该value。通过这种方式,在__consumer_offsets下就为每个group的某个topic下的某个分区唯一保存了一条数据,这条数据就是最新的offset。
感谢各位的阅读,以上就是“Kafka的知识点有哪些”的内容了,经过本文的学习后,相信大家对Kafka的知识点有哪些这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





