spring中怎么使用责任连模式,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
1. 外部控制模式
对于外部控制的方式,这种方式比较简单,链的每个节点只需要专注于各自的逻辑即可,而当前节点调用完成之后是否继续调用下一个节点,这个则由外部控制逻辑决定。这里我们以一个过滤器的实现逻辑进行讲解,在平常工作中,我们经常需要根据一系列的条件对某个东西进行过滤,比如任务服务的设计,在执行某个任务,其需要经过诸如时效性的检验,风控拦截,任务完成次数等的过滤条件的检验之后才能判断当前任务是否能够执行,只有在所有的过滤条件都完成之后,我们才能执行该任务。那么,这里我们可以抽象出一个Filter接口,设计如下:
public interface Filter {
/**
* 用于对各个任务节点进行过滤
*/
boolean filter(Task task);
}这里的Filter.filter方法只有一个参数Task,主要就是控制当天task是否需要过滤掉,其中有个boolean类型的返回值,通过该返回值告知外部控制逻辑是否需要将该task过滤掉。对于该接口的子类,我们只需要将其声明为spring所管理的一个bean即可:
@Component
public class DurationFilter implements Filter {
@Override
public boolean filter(Task task) {
System.out.println("时效性检验");
return true;
}
}@compoment
public class Risk implements Filter {
@override
public boolean filter(Task task){
System.out.println("风控拦截");
return true;
}
}@Component
public class TimesFilter implements Filter {
@Override
public boolean filter(Task task) {
System.out.println("次数限制检验");
return true;
}
}上面我们模拟声明了3个Filter的子类,用于设计一系列的控制当天task是否需要被过滤的逻辑,结构上的逻辑其实比较简单,主要就是需要将其声明为spring所管理的一个bean。下面是我们的控制逻辑:
@Service
public class ApplicationService {
@Autowired
private List<Filter> filters;
public void mockedClient() {
Task task = new Task(); // 这里task一般是通过数据库查询得到的
for (Filter filter : filters) {
if (!filter.filter(task)) {
return;
}
}
// 过滤完成,后续是执行任务的逻辑
}
} 上述的控制逻辑中,对于过滤器的获取,只需要通过spring的自动注入即可,这里的注入是一个List<Filter>,就是说,如果我们有新的Filter实例需要参与责任链的过滤,只需要声明为一个Spring容器所管理的bean即可。
这种责任链设计方式的优点在于链的控制简单,只需要实现一个统一的接口即可,基本上满足大部分的逻辑控制,但是对于某些动态调整链的需求就无能为力了。比如在执行到某个节点之后需要动态的判断师傅执行下一个节点,或者说要执行,某些分叉点的节点等。这个时候,我们就需要将链节点的传递工作交个各个节点执行。
1. 外部控制模式
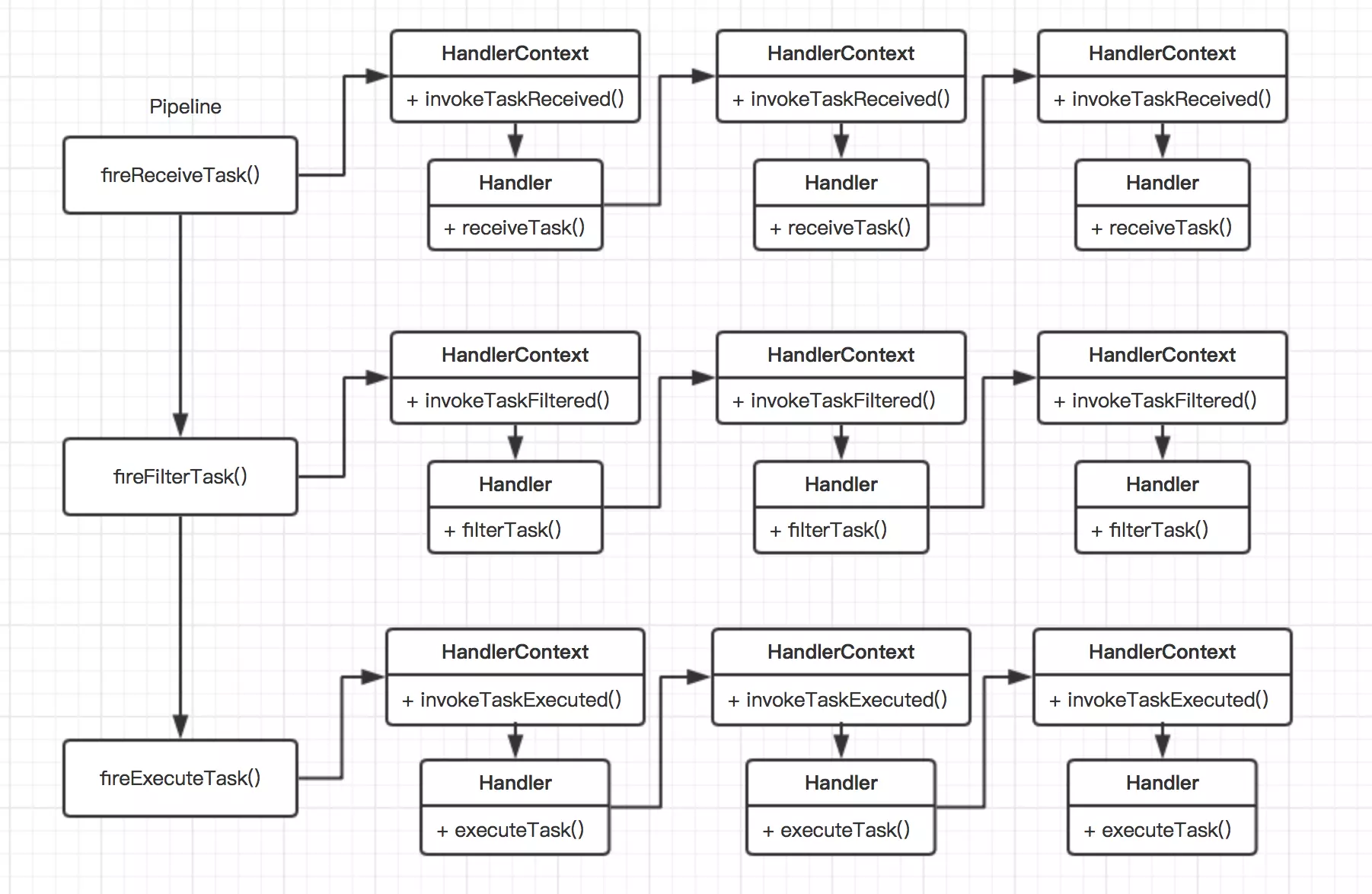
对于节点控制调用的方式,其主要有三个控制点:Handler,HandlerContext和PipeLine。Handle是用于编写具体的业务代码,HandlerContext用于对Handler进行包裹,并且用于控制下一个节点的调用;PipeLine则主要是用于控制整体的流程调用的,比如对于任务的执行,其有任务查询,任务的过滤和执行任务等等流程,这些流程整体的逻辑控制就是有pipeline控制,在每个流程中又包含了一些列的子流程,这些子流程则是由一个个的HandlerContext和Handler进行梳理的,这种责任链的控制方式整体逻辑如下图所示:
 ![]
![]
从上图可以看出,我们整个流程通过pipeline对象进行了抽象,这里主要分为了3个步骤:查询task,过滤task和执行task。在每个步骤中,我们都是用一系列的链式调用。途中需要注意的是,在每次调用链的下一个节点的时候,我们都是通过具体的Handler进行的,也就是说进行链的下一个节点的调用,我们是通过业务实现方来进行动态的控制。
关于该模式的设计,我们首先需要强调的就是Handler接口的设计,其设计如下所示:
public interface Handler {
/**
* 处理接收到前端请求的逻辑
*/
default void receiveTask(HandlerContext ctx, Request request) {
ctx.fireTaskReceived(request);
}
/**
* 查询到task之后,进行task过滤的逻辑
*/
default void filterTask(HandlerContext ctx, Task task) {
ctx.fireTaskFiltered(task);
}
/**
* task过滤完成之后,处理执行task的逻辑
*/
default void executeTask(HandlerContext ctx, Task task) {
ctx.fireTaskExecuted(task);
}
/**
* 当实现的前面的方法抛出异常时,将使用当前方法进行异常处理,这样可以将每个handler的异常
* 都只在该handler内进行处理,而无需额外进行捕获
*/
default void exceptionCaught(HandlerContext ctx, Throwable e) {
throw new RuntimeException(e);
}
/**
* 在整个流程中,保证最后一定会执行的代码,主要是用于一些清理工作
*/
default void afterCompletion(HandlerContext ctx) {
ctx.fireAfterCompletion(ctx);
}
}这里的Handler接口主要是对具体的业务逻辑的一个抽象,对于该Handler主要有如下几点需要说明:
在前面图中pipline的每个层级中对应于改Handler都有一个方法,在需要进行具体的业务处理的时候,用户只需要声明一个bean,具体实现某个业务所需要处理的层级的方法即可,无需管其他的逻辑;
每个层级的方法都有默认的实现,默认实现方式就是将链的调用继续往下进行传递
每个层级的方法中,第一个参数都是一个Handler类型的,该参数主要是用于进行流程控制的,比如是否需要将当前层级的调用链继续往下传递,这里的链的传递工作主要是通过ctx.filterXXX()方法进行
每个Handler中都有一个exceptionCaught()和afterCompletion()方法,这两个方法分别用于异常的控制和所有调用完成之后的清理,这里的异常控制主要是捕获当前Handler中的异常,而afterCompetition()方法则会保证所有步骤之后一定会进行调用的,五路是否抛出异常;
对于Handler的使用,我们希望能够达到的目的是,使用方只需要实现该接口,并且使用某个注解来将其标志位spring bean即可,无需管整个pipeline的组装和流程控制。通过这种方式,我们既保留了每个spring提供给我们的便利性,也使用了pipeline模式的灵活性
上述流程代码中,我们注意到,每个层级的方法中都有一个HandlerContext用于传递链的相关控制信息,我们来看下关于这部分的源码:
@Component
@Scope("prototype")
public class HandlerContext {
HandlerContext prev;
HandlerContext next;
Handler handler;
private Task task;
public void fireTaskReceived(Request request) {
invokeTaskReceived(next(), request);
}
/**
* 处理接收到任务的事件
*/
static void invokeTaskReceived(HandlerContext ctx, Request request) {
if (ctx != null) {
try {
ctx.handler().receiveTask(ctx, request);
} catch (Throwable e) {
ctx.handler().exceptionCaught(ctx, e);
}
}
}
public void fireTaskFiltered(Task task) {
invokeTaskFiltered(next(), task);
}
/**
* 处理任务过滤事件
*/
static void invokeTaskFiltered(HandlerContext ctx, Task task) {
if (null != ctx) {
try {
ctx.handler().filterTask(ctx, task);
} catch (Throwable e) {
ctx.handler().exceptionCaught(ctx, e);
}
}
}
public void fireTaskExecuted(Task task) {
invokeTaskExecuted(next(), task);
}
/**
* 处理执行任务事件
*/
static void invokeTaskExecuted(HandlerContext ctx, Task task) {
if (null != ctx) {
try {
ctx.handler().executeTask(ctx, task);
} catch (Exception e) {
ctx.handler().exceptionCaught(ctx, e);
}
}
}
public void fireAfterCompletion(HandlerContext ctx) {
invokeAfterCompletion(next());
}
static void invokeAfterCompletion(HandlerContext ctx) {
if (null != ctx) {
ctx.handler().afterCompletion(ctx);
}
}
private HandlerContext next() {
return next;
}
private Handler handler() {
return handler;
}
}在HandlerContext中,我们需要说明几点:
之前Handler接口默认实现的ctx.filterXXX()方法,这里都委托给了对应的invokeXXX方法进行调用,而且我们注意到,在传递invokeXXX()方法的参数里,传入的HandlerContext对象都是通过next()方法获取到的。也就是说我们在Handler中调用ctx.filterXXX方法时,都是在调用当前Handler的下一个Handler对应的层级方法,通过这种方式我们就可以实现链式的传递调用;
在上一点中我们说到,在某个Handler中如果想让链往下传递,只需要调用FilterXXX()方法即可,如果我们在某个Handler中,根据业务,当前层级已经调用完成,而无需调用后续的Handler,那么我们就不需要调用ctx.filterXXX()方法即可;
在HandlerContext中,我们也实现了invokeXXX()方法,该方法的作用是提供给外部的pipeline调用的,开启每个层级的链;
在每个invokeXXX()方法中,我们都是用try...catch将当前层级的调用抛出异常捕获了,然后调用ctx.handler().exceptionCaught()方法即可,异常捕获流程就是在这里的HandlerContext()中处理的;
在HandlerContext的声明处,我们需要注意到,其使用了@conpoment和@("prototype")注解进行标注了,这说明我们的HandlerContext是有spring 容器管理的,并且由于我们每个Handler实际都由HandlerContext维护,所以这里必须声明为prototype类型。通过这种方式,我们的HandlerContext也就具备着诸如spring相关的bean的功能,能够根据业务需求进行一些额外的处理;
前面我们讲解了Handler和HandlerContext的具体实现,以及实现的过程需要注意的一些问题,下面我们将来看进行流程控制的pipeline是如何实现的,如下是其接口的定义:
public interface Pipeline {
Pipeline fireTaskReceived();
Pipeline fireTaskFiltered();
Pipeline fireTaskExecuted();
Pipeline fireAfterCompletion();
}这里主要是定义了一个pipeline接口,该接口定义了一些列的层级调用,是每个层级的入口方法,如下是该接口的实现类:
@Component("pipeline")
@Scope("prototype")
public class DefaultPipeline implements Pipeline, ApplicationContextAware, InitializingBean {
// 创建一个默认的handler,将其注入到首尾两个节点的HandlerContext中,其作用只是将链往下传递
private static final Handler DEFAULT_HANDLER = new Handler() {};
// 将ApplicationContext注入进来的主要原因在于,HandlerContext是prototype类型的,因而需要
// 通过ApplicationContext.getBean()方法来获取其实例
private ApplicationContext context;
// 创建一个头结点和尾节点,这两个节点内部没有做任何处理,只是默认的将每一层级的链往下传递,
// 这里头结点和尾节点的主要作用就是用于标志整个链的首尾,所有的业务节点都在这两个节点中间
private HandlerContext head;
private HandlerContext tail;
// 用于业务调用的request对象,其内部封装了业务数据
private Request request;
// 用于执行任务的task对象
private Task task;
// 最初始的业务数据需要通过构造函数传入,因为这是驱动整个pipeline所需要的数据,
// 一般通过外部调用方的参数进行封装即可
public DefaultPipeline(Request request) {
this.request = request;
}
// 这里我们可以看到,每一层级的调用都是通过HandlerContext.invokeXXX(head)的方式进行的,
// 也就是说我们每一层级链的入口都是从头结点开始的,当然在某些情况下,我们也需要从尾节点开始链
// 的调用,这个时候传入tail即可。
@Override
public Pipeline fireTaskReceived() {
HandlerContext.invokeTaskReceived(head, request);
return this;
}
// 触发任务过滤的链调用
@Override
public Pipeline fireTaskFiltered() {
HandlerContext.invokeTaskFiltered(head, task);
return this;
}
// 触发任务执行的链执行
@Override
public Pipeline fireTaskExecuted() {
HandlerContext.invokeTaskExecuted(head, task);
return this;
}
// 触发最终完成的链的执行
@Override
public Pipeline fireAfterCompletion() {
HandlerContext.invokeAfterCompletion(head);
return this;
}
// 用于往Pipeline中添加节点的方法,读者朋友也可以实现其他的方法用于进行链的维护
void addLast(Handler handler) {
HandlerContext handlerContext = newContext(handler);
tail.prev.next = handlerContext;
handlerContext.prev = tail.prev;
handlerContext.next = tail;
tail.prev = handlerContext;
}
// 这里通过实现InitializingBean接口来达到初始化Pipeline的目的,可以看到,这里初始的时候
// 我们通过ApplicationContext实例化了两个HandlerContext对象,然后将head.next指向tail节点,
// 将tail.prev指向head节点。也就是说,初始时,整个链只有头结点和尾节点。
@Override
public void afterPropertiesSet() throws Exception {
head = newContext(DEFAULT_HANDLER);
tail = newContext(DEFAULT_HANDLER);
head.next = tail;
tail.prev = head;
}
// 使用默认的Handler初始化一个HandlerContext
private HandlerContext newContext(Handler handler) {
HandlerContext context = this.context.getBean(HandlerContext.class);
context.handler = handler;
return context;
}
// 注入ApplicationContext对象
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
this.context = applicationContext;
}
}关于defaultPipeline的实现,有以下几点需要说明:
defaultpipeline 使用@compoment和@scope("prototype")注解进行了标注,当前一个注解用于将其声明为一个spring容器所管理的bean,而后一个注解则用于表征defaultPipeline是个多例类型,很明显的,这里的pipeLine是有状态的。这里需要进行说明的是,'有状态'主要是因为我们可能会根据业务情况的动态的调整整个链的节点情况,而且这里的request和task对象都是与具体的业务相关的,因为必须声明为prototype类型;
上面的示例中,request对象是通过构造pipeline对象的时候传进来的,而task对象则是在pipeline的流转过程中生成的,这里比如通过完成filterTaskReceived()链的调用之后,就需要通过外部请求request得到一个task对象,从而进行后续的处理;
对于后续写业务代码的人而言,其只需要实现一个Handler接口即可,无需要处理链相关的所有逻辑,以为我们需要获取到所有实现Handler接口的bean;
将实现了Handler接口的bean通过Handlercontext进行封装,然后将其添加到pipeline中
这里的第一个问题好处理,因为通过ApplicationContext就可以获取实现了某个接口的所有bean,而第二个问题我们可以通过声明了BeanPostProcessoor接口的类来实现。如下是具体的实现代码:
verride
public void setApplicationContext(ApplicationContext applicationContext) {
this.context = applicationContext;
}
}
关于DefaultPipeline的实现,主要有如下几点需要说明:
DefaultPipeline使用@Component和@Scope("prototype")注解进行了标注,前一个注解用于将其声明为一个Spring容器所管理的bean,而后一个注解则用于表征DefaultPipeline是一个多例类型的,很明显,这里的Pipeline是有状态的。这里需要进行说明的是,"有状态"主要是因为我们可能会根据业务情况动态的调整个链的节点情况,而且这里的Request和Task对象都是与具体的业务相关的,因而必须声明为prototype类型;
上面的示例中,Request对象是通过构造Pipeline对象的时候传进来的,而Task对象则是在Pipeline的流转过程中生成的,这里比如通过完成fireTaskReceived()链的调用之后,就需要通过外部请求Request得到一个Task对象,从而进行整个Pipeline的后续处理;
这里我们已经实现了Pipeline,HandlerContext和Handler,知道这些bean都是被Spring所管理的bean,那么我们接下来的问题主要在于如何进行整个链的组装。这里的组装方式比较简单,其主要需要解决两个问题:
对于后续写业务代码的人而言,其只需要实现一个Handler接口即可,而无需处理与链相关的所有逻辑,因而我们需要获取到所有实现了Handler接口的bean;
将实现了Handler接口的bean通过HandlerContext进行封装,然后将其添加到Pipeline中。
这里的第一个问题比较好处理,因为通过ApplicationContext就可以获取实现了某个接口的所有bean,而第二个问题我们可以通过声明一个实现了BeanPostProcessor接口的类来实现。如下是其实现代码:
@Component
public class HandlerBeanProcessor implements BeanPostProcessor, ApplicationContextAware {
private ApplicationContext context;
// 该方法会在一个bean初始化完成后调用,这里主要是在Pipeline初始化完成之后获取所有实现了
// Handler接口的bean,然后通过调用Pipeline.addLast()方法将其添加到pipeline中
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
if (bean instanceof DefaultPipeline) {
DefaultPipeline pipeline = (DefaultPipeline) bean;
Map<String, Handler> handlerMap = context.getBeansOfType(Handler.class);
handlerMap.forEach((name, handler) -> pipeline.addLast(handler));
}
return bean;
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
this.context = applicationContext;
}
}这里我们整个链路的维护工作就完成,可以看到,现在基本已经实现了链式流程控制。这里需要说明的一点是,上面的HandlerBeanProcessor.postProcessAfterInitialization()方法的执行是在InitializingBean.afterPropertySet()方法之后执行的,也就是说这里的HandlerBeanProcessor在执行的时候,整个pipeline就是已经完成初始化的了。下面我们来看下外部客户端如何进行这个链路流程的控制:
HandlerBeanProcessor在执行时,整个Pipeline是已经初始化完成了的。下面我们来看一下外部客户端如何进行整个链是流程的控制:
@Service
public class ApplicationService {
@Autowired
private ApplicationContext context;
public void mockedClient() {
Request request = new Request(); // request一般是通过外部调用获取
Pipeline pipeline = newPipeline(request);
try {
pipeline.fireTaskReceived();
pipeline.fireTaskFiltered();
pipeline.fireTaskExecuted();
} finally {
pipeline.fireAfterCompletion();
}
}
private Pipeline newPipeline(Request request) {
return context.getBean(DefaultPipeline.class, request);
}
}这里我们模拟一个客户端的调用,首先创建了一个pipeline对象,然后依次调用各个层级的方法,并且这里我们使用try....finally结构来保证Pipeline.fireAfterCompletion()方法一定会执行。如此我们就完成了整个责任链路模式的构造。这里我们使用前面用到的时效性的filter来作为示例来实现一个Handler:
@Component
public class DurationHandler implements Handler {
@Override
public void filterTask(HandlerContext ctx, Task task) {
System.out.println("时效性检验");
ctx.fireTaskFiltered(task);
}
}关于这里具体的业务我们需要说明的有如下几点:
改Handler必须使用@compoment注解来将其声明为spring容器管理的bean,这样我们前面实现的HandlerBeanProcessor 才能动态的添加到整个pipeline中;
在每个Handler中,需要根据当前的业务需要来实现具体的层级方法,比如这里是进行时效性检验的,就是"任务过滤"这一层级的逻辑,因为时效性检验通过我们才能执行这个task,因而这里需要实现的是Handler.filterTask()方法,如果我们需要实现的是执行task的逻辑,那么需要实现的是Handler.executeTask()方法; 在实现完具体的业务逻辑之后,我们可以根据当前的业务需要看是否需要将当前层级的链继续往下传递,也就是这里的ctx.fireTaskFiltered(task);方法的调用,我们可以看前面HandlerContext.fireXXX()方法就是会获取当前节点的下一个节点,然后进行调用。如果根据业务需要,不需要将链往下传递,那么就不需要调用ctx.fireTaskFiltered(task);
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





