RabbitMQж¶ҲжҒҜдёўеӨұй—®йўҳе’ҢдҝқиҜҒж¶ҲжҒҜеҸҜйқ жҖ§д№Ӣж¶Ҳиҙ№з«ҜдёҚдёўж¶ҲжҒҜе’ҢHAзҡ„зӨәдҫӢеҲҶжһҗ
RabbitMQж¶ҲжҒҜдёўеӨұй—®йўҳе’ҢдҝқиҜҒж¶ҲжҒҜеҸҜйқ жҖ§д№Ӣж¶Ҳиҙ№з«ҜдёҚдёўж¶ҲжҒҜе’ҢHAзҡ„зӨәдҫӢеҲҶжһҗпјҢй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶзӣёеҜ№еә”зҡ„еҲҶжһҗе’Ңи§Јзӯ”пјҢеёҢжңӣеҸҜд»Ҙеё®еҠ©жӣҙеӨҡжғіи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„е°ҸдјҷдјҙжүҫеҲ°жӣҙз®ҖеҚ•жҳ“иЎҢзҡ„ж–№жі•гҖӮ
дёҠйқўдёӨдёӘж“ҚдҪңдҝқиҜҒж¶ҲжҒҜеҲ°жңҚеҠЎз«ҜдёҚдёўпјҢдҪҶжҳҜйқһй«ҳеҸҜз”ЁзҠ¶жҖҒпјҢеҰӮжһңиҠӮзӮ№жҢӮжҺүпјҢжңҚеҠЎжҡӮж—¶дёҚеҸҜз”ЁпјҢйңҖиҰҒйҮҚеҗҜеҗҺпјҢж¶ҲжҒҜжҒўеӨҚпјҢж¶ҲжҒҜдёҚдјҡдёўеӨұпјҢеӣ дёәжңүзЈҒзӣҳеӯҳеӮЁгҖӮ
жң¬ж–Үе…Ҳд»Һж¶Ҳиҙ№з«Ҝи®Іиө·пјҡ
RabbitMQ ServerеҲ°ж¶Ҳиҙ№иҖ…ж¶ҲжҒҜеҰӮдҪ•дёҚдёўпјҹ
дёҠйқўдёҖзҜҮж–Үз« д№ҹжҸҗеҲ°дәҶпјҢж¶Ҳиҙ№иҖ…иҺ·еҸ–еҲ°ж¶ҲжҒҜд№ӢеҗҺпјҢжІЎжңүжқҘеҫ—еҸҠеӨ„зҗҶе®ҢжҜ•пјҢиҮӘе·ұзӣҙжҺҘе®•жңәдәҶ,еӣ дёәж¶ҲжҒҜиҖ…й»ҳи®ӨйҮҮз”ЁиҮӘеҠЁackпјҢжӯӨж—¶RabbitMQзҡ„иҮӘеҠЁackжңәеҲ¶дјҡйҖҡзҹҘMQ ServerиҝҷжқЎж¶ҲжҒҜе·Із»ҸеӨ„зҗҶеҘҪдәҶпјҢжӯӨж—¶ж¶ҲжҒҜе°ұдёўдәҶпјҢ并дёҚжҳҜйў„жңҹзҡ„гҖӮ
йӮЈд№ҲжҲ‘们йҮҮз”ЁжүӢеҠЁackжңәеҲ¶жқҘи§ЈеҶіиҝҷдёӘй—®йўҳпјҢж¶Ҳиҙ№з«ҜеӨ„зҗҶе®ҢйҖ»иҫ‘д№ӢеҗҺеҶҚйҖҡзҹҘMQ ServerпјҢиҝҷж ·ж¶Ҳиҙ№иҖ…жІЎеӨ„зҗҶе®Ңж¶ҲжҒҜдёҚдјҡеҸ‘йҖҒack,еҰӮжһңеңЁж¶Ҳиҙ№иҖ…жӢҝеҲ°ж¶ҲжҒҜпјҢжІЎжқҘеҫ—еҸҠеӨ„зҗҶзҡ„жғ…еҶөдёӢиҮӘе·ұжҢӮдәҶпјҢжӯӨж—¶MQйӣҶзҫӨдјҡиҮӘеҠЁж„ҹзҹҘеҲ°пјҢе®ғе°ұдјҡиҮӘи§үзҡ„йҮҚеҸ‘ж¶ҲжҒҜз»ҷе…¶д»–зҡ„ж¶Ҳиҙ№иҖ…жңҚеҠЎе®һдҫӢгҖӮ
ж №жҚ®дёҠйқўзҡ„жҖқи·ҜдҪ йңҖиҰҒе®ҢжҲҗдёӢйқўзҡ„дёӨжӯҘж“ҚдҪңпјҡ
第дёҖпјҡж¶Ҳиҙ№иҖ…зӣ‘еҗ¬и®ҫзҪ®жүӢеҠЁack
this.channel = channelManager.getListenerChannel(namespace);
this.queue = queue;
this.channel.basicConsume(queue, false, consumerTag, this);
this.disconnectedCallback.setChannel(channel);
ж ёеҝғд»Јз Ғпјҡ this.channel.basicConsume(queue, false, consumerTag, this); 第дәҢдёӘеҸӮж•°и®ҫзҪ® false д»ЈиЎЁдёҚиҮӘеҠЁack
第дәҢпјҡдёҡеҠЎжү§иЎҢе®ҢжҲҗеҗҺжүӢеҠЁack
public static void ack(MessageContext context) {
long deliveryTag = context.getEnvelope().getDeliveryTag();
try {
context.getChannel().basicAck(deliveryTag, false);
} catch (IOException e) {
throw new MqAckException("ж¶ҲжҒҜackеҮәй”ҷпјҡиҝһжҺҘејӮеёёжҲ–иҝңз«Ҝе…ій—ӯ", context, e);
}
}ж ёеҝғд»Јз Ғпјҡ context.getChannel().basicAck(deliveryTag, false);
иҝҷйҮҢе°ҒиЈ…жқҘпјҢйңҖиҰҒдёҡеҠЎеңЁжү§иЎҢе®ҢиҮӘе·ұзҡ„дёҡеҠЎд»Јз ҒеҗҺпјҢи°ғз”ЁеҜ№иұЎchannel зҡ„ackж–№жі•йҖҡзҹҘMQServerпјҢиҜҙжҲ‘иҝҷиҫ№жү§иЎҢе®ҢдәҶпјҢдҪ еҸҜд»ҘеҲ йҷӨдәҶгҖӮ
жіЁж„ҸиҝҷйҮҢжңүдёӘй—®йўҳпјҡ еҰӮжһңеҝҳи®°и°ғз”ЁиҝҷдёӘ context.getChannel().basicAck(deliveryTag, false);
жҲ–иҖ…еӣ дёәд»Јз ҒејӮеёёпјҢиҝҷдёӘд»Јз ҒжІЎиў«жү§иЎҢпјҢдјҡжҖҺд№Ҳж ·пјҹеҗҺйқўжүҫж—¶й—ҙеҶҚеҶҷдёҖзҜҮж–Үз« и®ІиҝҷдёӘй—®йўҳгҖӮ
RabbitMQ ServerдёӯеӯҳеӮЁзҡ„ж¶ҲжҒҜй«ҳеҸҜз”Ё
еҪ“жҲ‘们解еҶідәҶпјҢз”ҹдә§з«Ҝе’Ңж¶Ҳиҙ№з«Ҝзҡ„й—®йўҳеҗҺпјҢеҹәжң¬дҝқиҜҒж¶ҲжҒҜзҡ„дёҚдёўй—®йўҳпјҢдҪҶжҳҜиҝҳжңүдёҖдёӘжҳҜж¶ҲжҒҜзҡ„й«ҳеҸҜз”Ёй—®йўҳпјҢеҚ•иҠӮзӮ№й—®йўҳпјҢжҷ®йҖҡиҠӮзӮ№зҡ„й—®йўҳйғҪдјҡеҪұе“Қж¶ҲжҒҜзҡ„дёҙж—¶дёҚеҸҜз”ЁпјҢиҝҷдёӘж—¶еҖҷиҰҒз”ЁдёҠжҲ‘们зҡ„HA й•ңеғҸйӣҶзҫӨжЁЎејҸжқҘдҝқиҜҒгҖӮ
дёҠдёҖзҜҮж–Үз« и§ЈеҶіRabbitMQж¶ҲжҒҜдёўеӨұй—®йўҳе’ҢдҝқиҜҒж¶ҲжҒҜеҸҜйқ жҖ§пјҲдёҖпјү е·Із»ҸжҸҗеҲ°иҝҮпјҢжңҚеҠЎз«Ҝж¶ҲжҒҜйғЁзҪІзҡ„дёүз§ҚжЁЎејҸзҡ„еҢәеҲ«пјҢд»ҠеӨ©е°ұдё“й—Ёи®Ій•ңеғҸжЁЎејҸзҡ„д»Ӣз»ҚгҖӮ
й•ңеғҸжЁЎејҸиҮіе°‘йҮҮз”Ё3иҠӮзӮ№пјҢ2дёӘзЈҒзӣҳиҠӮзӮ№е’Ң1дёӘеҶ…еӯҳиҠӮзӮ№жқҘдҝқиҜҒпјҢжһ¶жһ„еӣҫпјҡ
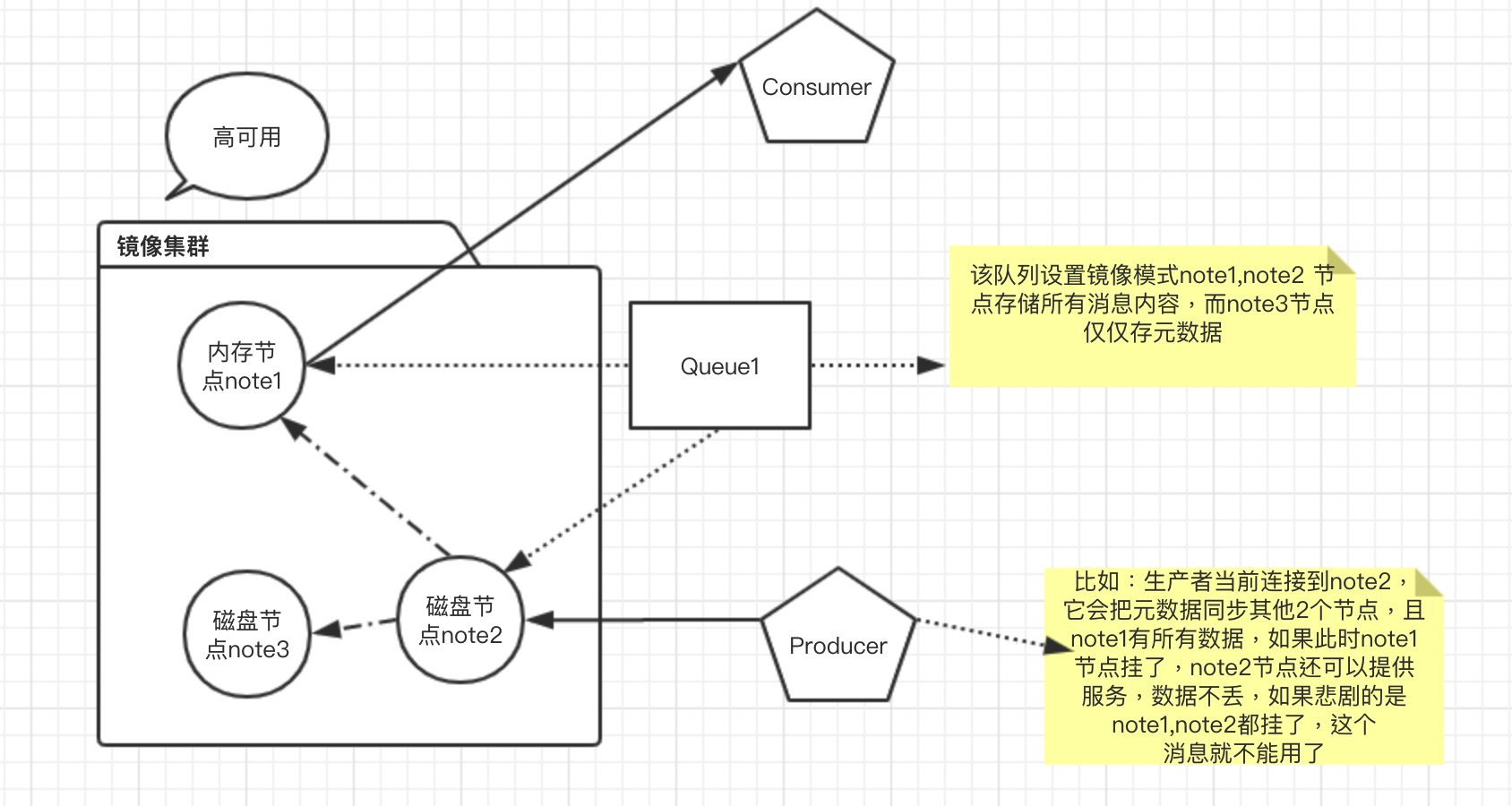
и®ҫзҪ®й•ңеғҸд№ҹжңүдёҖдәӣзӯ–з•Ҙпјҡ
> е‘Ҫд»ӨеӨ„зҗҶHAзӯ–з•ҘжЁЎзүҲпјҡrabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
дёәжҜҸдёӘд»ҘвҖңrock.wechatвҖқејҖеӨҙзҡ„йҳҹеҲ—и®ҫзҪ®жүҖжңүиҠӮзӮ№зҡ„й•ңеғҸпјҢ并且и®ҫзҪ®дёәиҮӘеҠЁеҗҢжӯҘжЁЎејҸ
rabbitmqctl set_policy ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
rabbitmqctl set_policy -p rock ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}'дёәжҜҸдёӘд»ҘвҖңrock.wechat.вҖқејҖеӨҙзҡ„йҳҹеҲ—и®ҫзҪ®дёӨдёӘиҠӮзӮ№зҡ„й•ңеғҸпјҢ并且и®ҫзҪ®дёәиҮӘеҠЁеҗҢжӯҘжЁЎејҸ
rabbitmqctl set_policy -p rock ha-exacly "^rock.wechat" \
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'дёәжҜҸдёӘд»ҘвҖңnode.вҖқејҖеӨҙзҡ„йҳҹеҲ—еҲҶй…ҚжҢҮе®ҡзҡ„иҠӮзӮ№еҒҡй•ңеғҸ
rabbitmqctl set_policy ha-nodes "^nodes\." \
'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'> дҪҶжҳҜпјҡHA й•ңеғҸйҳҹеҲ—жңүдёҖдёӘеҫҲеӨ§зҡ„зјәзӮ№е°ұжҳҜпјҡ зі»з»ҹзҡ„еҗһеҗҗйҮҸдјҡжңүжүҖдёӢйҷҚ
жүҖд»ҘйҮҮз”Ёй•ңеғҸжЁЎејҸпјҢиҰҒж №жҚ®е…·дҪ“зҡ„дёҡеҠЎи§„еҲҷе®ҡеҲ¶иҜқеӨ„зҗҶпјҢжІЎйӮЈд№ҲйҮҚиҰҒзҡ„дёҡеҠЎпјҢж¶ҲжҒҜдёўдәҶд№ҹжІЎе…ізі»зҡ„еңәжҷҜпјҢеҸҲиҰҒжұӮеҝ…йЎ»й«ҳзҡ„жҖ§иғҪзҡ„ж—¶еҖҷпјҢй•ңеғҸд№ҹеҸҜд»ҘдёҚз”Ёи®ҫзҪ®гҖӮ
е…ідәҺRabbitMQж¶ҲжҒҜдёўеӨұй—®йўҳе’ҢдҝқиҜҒж¶ҲжҒҜеҸҜйқ жҖ§д№Ӣж¶Ҳиҙ№з«ҜдёҚдёўж¶ҲжҒҜе’ҢHAзҡ„зӨәдҫӢеҲҶжһҗй—®йўҳзҡ„и§Јзӯ”е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҰӮжһңдҪ иҝҳжңүеҫҲеӨҡз–‘жғ‘жІЎжңүи§ЈејҖпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“дәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶгҖӮ





