第一天
1.大数据典型特性与分布式开发难点
| 1. | 大数据典型特性与分布式开发难点 |
| 2. | Hadoop框架介绍与搜索技术体系介绍 |
| 3. | Hadoop版本与特性介绍 |
| 4. | Hadoop核心模块之HDFS分布式文件系统架构介绍 |
| 5. | Hadoop核心模块之Yarn操作系统架构介绍 |
| 6. | Linux安全禁用设置与JDK安装讲解 |
| 7. | Hadoop伪分布式环境部署HDFS部分 |
| 8. | Hadoop伪分布式环境部署Yarn和MR部分 |
| 9. | Hadoop环境使用常见的错误集合 |
| 10. | Hadoop环境常规设置与辅助功能讲解(-) |
| 11. | Hadoop环境常规设置与辅助功能讲解(二) |
| 12. | Windows环境下部署Eclipse插件注意事项 |
1.大数据典型特性与分布式开发难点
1.大数据典型特性
没有大数据据技术之前,我就以抽样统计为例(统计一个城市的男女人口比例),我们的做法是不是找个人多的地方,随机抽取一部分人,统计出男女比例,作为城市的男女人口比例,这样的误差非常大,数据量越大,统计出来的结果越准确。这样我们就要先解决这么大数据量的存储问题,(这个例子不能体现出数据类型繁多),接下来是不是要解决数据计算的问题,总不能人工一个一个数吧,大数据技术就能为我们解决这些问题。
传统RDBMS 的瓶颈,关系型数据的特点是各个数据项之间有一定的关系,这个在设计数据库的设计阶段必须设计好,但是当今需求中,我们往往分析的数据之间没有关系,例如我们在设计一个推荐系统的时候,要分析客户的行为,客户的行为数据之间就没有相应的关系,结构化数据和非结构化数据共存使数据多样化。
海量的数据,这么大的数据量,我们还要处理的非常快。这对技术是很大的挑战。这就是大数据的特性

多:这里的多就是海量数据,我们要解决海量数据的存储问题
繁:结构化,非结构化,半结构化数据的共存
快:这么大的数据量,这么繁多的不同类型的数据,还要处理的快,不然就会成为系统的瓶颈。
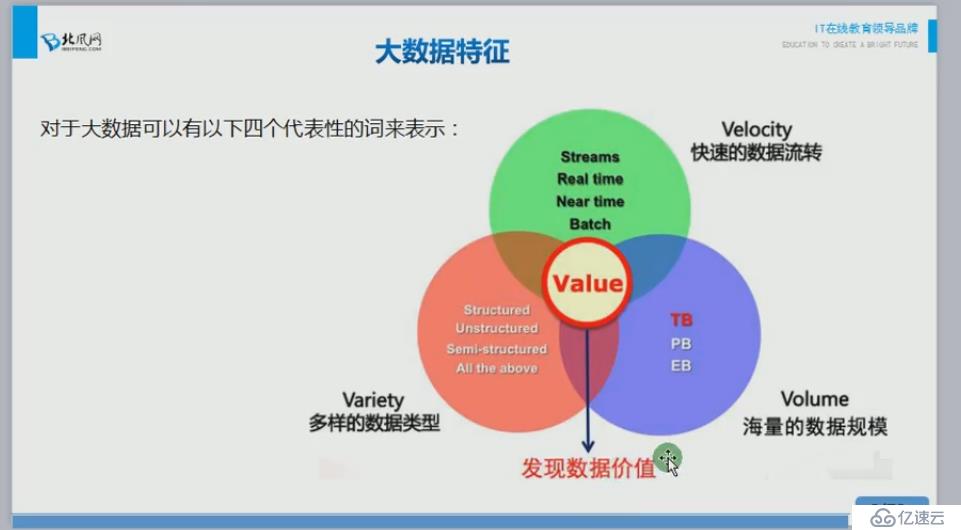
我们的最终目的是挖掘出有用的,有价值的数据。
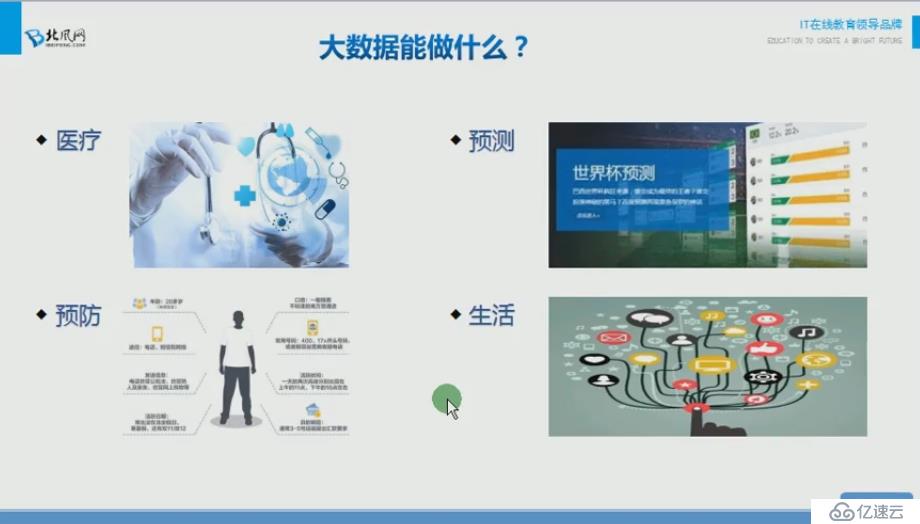
2.大数据的能做什么?
3.一个数据平台的工作(完整的平台)
3.1离线
-》批量计算
3.2 实时
-》流式计算
-》在线分析
3.3数据共享
4.数据平台指标
-》设备台数:5000台
-》总存储数量:100PB+
-》日新增数量:200TB+,月数据增长比率10%
-》有多个数据产品
-》存储表10w+
-》日均运行JOB数
-》日均计算量5PB+
5.分布式开发的难点
-》平台搭建
-》分布式
-》同步,一致性(配置(会搭建很多框架),时间(微妙误差))
-》自动化部署管理平台
-》cloudera 发布的hadoop版本 CDH
-》cloudera manager,简称:CM
-》框架是开源的 不可靠
所以很多公司都是以开源框架为基础,开发自己的框架,例如:淘宝的 TFS文件系统
任务调度框架oozie,淘宝自己的框架 宙斯 。
-》成本的问题
由于集群用到的机器比较廉价,所以会出现节点故障,我们必须有相应的容错机制,保证集群的健壮性。
6.学习大数据的基础:
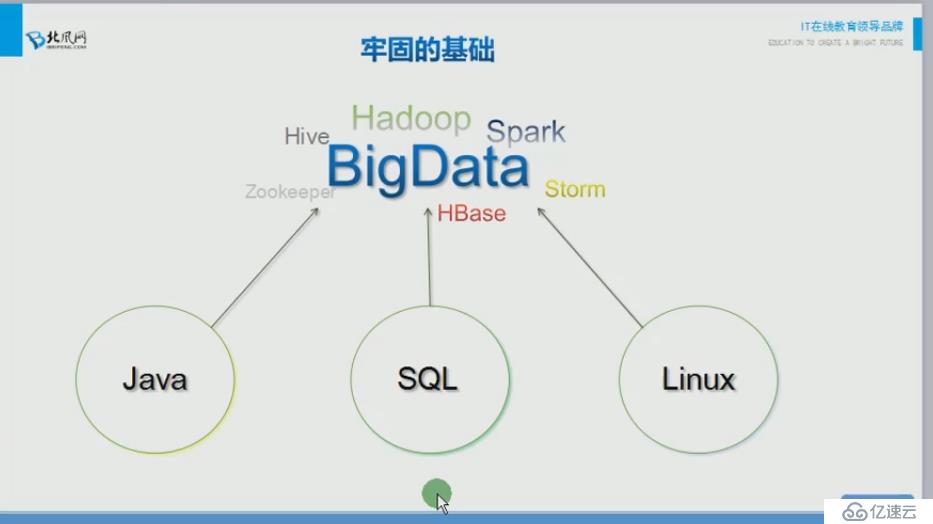
自己学习的随笔,在组织存在问题,不喜勿说
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





