一、概述
1.实验使用的Hadoop集群为伪分布式模式,eclipse相关配置已完成;
2.软件版本为hadoop-2.7.3.tar.gz、apache-maven-3.5.0.rar。
二、使用eclipse连接hadoop集群进行开发
1.在开发主机上配置hadoop
①将hadoop-2.7.3.tar.gz解压到本地主机上
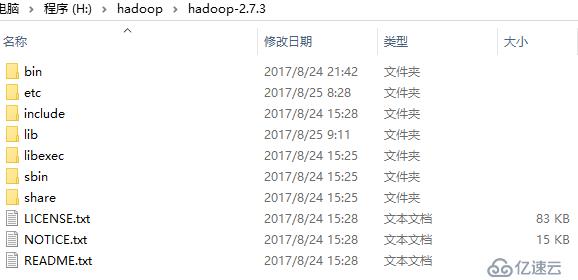
②使用windows版本的hadoop中的bin替换目标中的bin文件夹
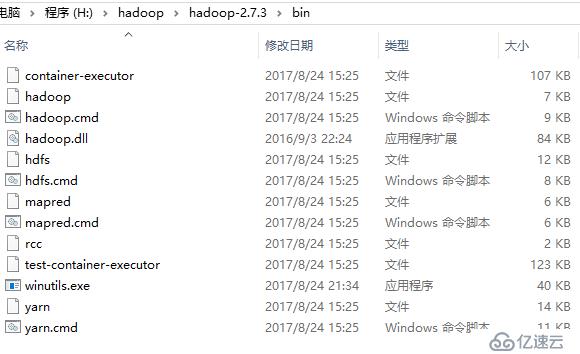
③配置windows上的hadoop环境变量
2.在eclipse上配置hadoop集群信息
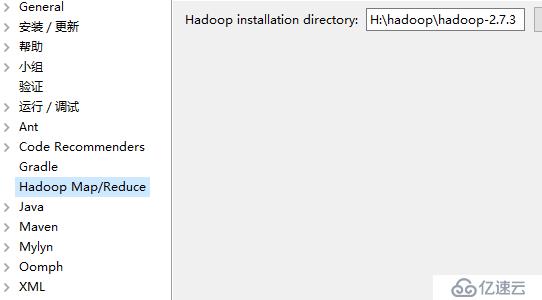
①在eclipse中添加hadoop路径
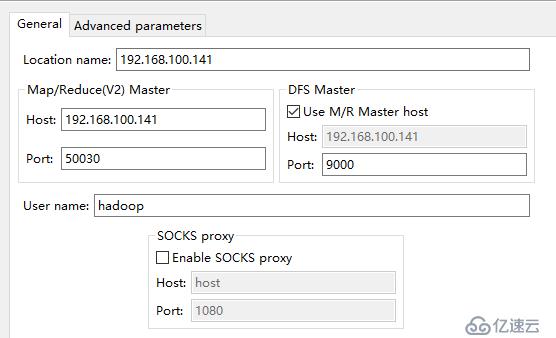
②配置hadoop集群访问信息
3.在hadoop集群中取消权限验证
hdfs-site.xml <property> <name>dfs.permissions</name> <value>false</value> </property>
4.创建一个文件测试连接权限
5.安装maven
①将maven解压到开发主机上
②在eclipse上添加maven路径
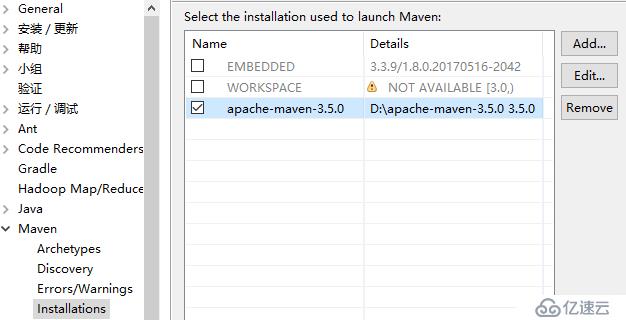
5.新建maven工程
6.修改maven配置文件(maven/pom.xml)
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> </dependencies>
7.新建一个类用于测试(WordCount)
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}8.配置WordCount
①将log4j.properties移动到WordCount类下
②设置WordCount的运行自变量
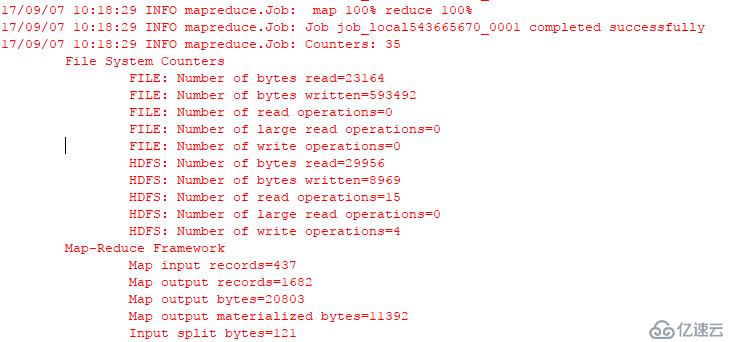
8.运行测试
三、jar包的导出与提交执行
1.导出WordCount
2.将导出的jar包上传到hadoop集群
[hadoop@hadoop ~]$ ls wc.jar
3.运行
[hadoop@hadoop ~]$ hadoop jar wc.jar WordCount /user/hadoop/input/* /user/hadoop/output/out 17/09/06 22:36:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop/192.168.100.141:8032 17/09/06 22:36:57 INFO input.FileInputFormat: Total input paths to process : 1 17/09/06 22:36:58 INFO mapreduce.JobSubmitter: number of splits:1 17/09/06 22:36:58 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1504744740212_0001 17/09/06 22:36:59 INFO impl.YarnClientImpl: Submitted application application_1504744740212_0001 17/09/06 22:36:59 INFO mapreduce.Job: The url to track the job: http://hadoop:8088/proxy/application_1504744740212_0001/ 17/09/06 22:36:59 INFO mapreduce.Job: Running job: job_1504744740212_0001 17/09/06 22:37:36 INFO mapreduce.Job: Job job_1504744740212_0001 running in uber mode : false 17/09/06 22:37:36 INFO mapreduce.Job: map 0% reduce 0% 17/09/06 22:38:26 INFO mapreduce.Job: map 100% reduce 0% 17/09/06 22:38:42 INFO mapreduce.Job: map 100% reduce 100% 17/09/06 22:38:46 INFO mapreduce.Job: Job job_1504744740212_0001 completed successfully
4.查看运行结果
[hadoop@hadoop ~]$ hdfs dfs -cat /user/hadoop/output/out/part-r-00000 "AS 1 "GCC 1 "License"); 1 & 1 'Aalto 1 'Apache 4 'ArrayDeque', 1 'Bouncy 1 'Caliper', 1 'Compress-LZF', 1 ……
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





