这篇文章主要为大家展示了“python的正则表达式怎么用”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“python的正则表达式怎么用”这篇文章吧。
re 模块使 Python 语言拥有全部的正则表达式功能

# 提取大小写字母混合的单词
import re
a = 'Excel 12345Word23456PPT12Lr'
r = re.findall('[a-zA-Z]{3,5}',a)
# 提取字母的数量3个到5个
print(r)
# ['Excel', 'Word', 'PPT']
# 贪婪 与 非贪婪 【Python默认使用贪婪模式】
# 贪婪:'[a-zA-Z]{3,5}'
# 非贪婪:'[a-zA-Z]{3,5}?' 或 '[a-zA-Z]{3}'
# 建议使用后者,不要使用?号,否则你会与下面的?号混淆
# 匹配0次或无限多次 *号,*号前面的字符出现0次或无限次
import re
a = 'exce0excell3excel3'
r = re.findall('excel*',a)
r = re.findall('excel.*',a) # ['excell3excel3']
# excel 没有l 有很多l都可以匹配出来
print(r)
# ['exce', 'excell', 'excel']
# 匹配1次或者无限多次 +号,+号前面的字符至少出现1次
import re
a = 'exce0excell3excel3'
r = re.findall('excel+',a)
print(r)
# ['excell', 'excel']
# 匹配0次或1次 ?号,?号经常用来去重复
import re
a = 'exce0excell3excel3'
r = re.findall('excel?',a)
print(r)
# ['exce', 'excel', 'excel']
line = 'xyz,xcz.xfc.xdz,xaz,xez,xec'
r = re.findall('x[de]z', line)
# pattern 是x开始,z结束,含d或e
print(r)
# ['xdz', 'xez']
r = re.findall('x[^de]z', line)
# pattern 是x开始,z结束,不是含d或e
print(r)
# ['xyz', 'xcz', 'xaz']# \w 可以提取中文,英文,数字和下划线,不能提取特殊字符
import re
a = 'Excel 12345Word\n23456_PPT12lr'
r = re.findall('\w',a)
print(r)
# ['E', 'x', 'c', 'e', 'l', '1', '2', '3', '4', '5', 'W', 'o', 'r', 'd', '2', '3', '4', '5', '6', '_', 'P', 'P', 'T', '1', '2', 'l', 'r']
# \W 提取特殊字符,空格 \n \t
import re
a = 'Excel 12345Word\n23456_PPT12lr'
r = re.findall('\W',a)
print(r)
# [' ', '\n']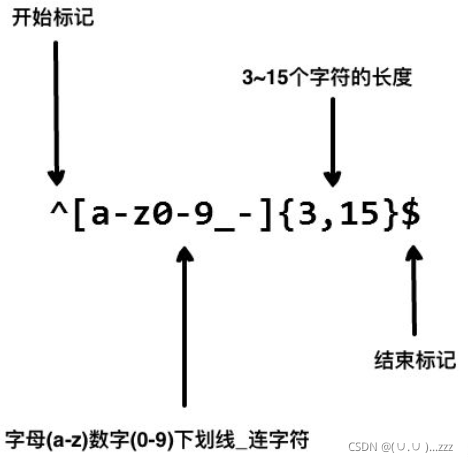
# 限制电话号码的位置必需是8-11位才能提取
import re
tel = '13811115888'
r = re.findall('^\d{8,11}$',tel)
print(r)
# ['13811115888']# 将abc打成一个组,{2}指的是重复几次,匹配abcabc
import re
a = 'abcabcabcxyzabcabcxyzabc'
r = re.findall('(abc){2}',a) # 与
# ['abc', 'abc']
print(r)
r = re.findall('(abc){3}',a)
# ['abc']
# findall第三参数 re.I忽略大小写
import re
a = 'abcFBIabcCIAabc'
r = re.findall('fbi',a,re.I)
print(r)
# ['FBI']
# 多个模式之间用 | 连接在一起
import re
a = 'abcFBI\nabcCIAabc'
r = re.findall('fbi.{1}',a,re.I | re.S)
# 匹配fbi然后匹配任意一个字符包括\n
print(r)
# ['FBI\n']匹配出字符串中所有 与制定值相关的值
以列表的形式返回
未匹配则返回空列表
import re re.findall(pattern, string, flags=0) pattern.findall(string[ , pos[ , endpos]])
import re
line = "111aaabbb222小呼噜奥利奥"
r = re.findall('[0-9]',line)
print(r)
# ['1', '1', '1', '2', '2', '2']re.match 尝试从字符串的起始位置匹配一个模式
如果不是起始位置匹配成功的话,match()就返回none。
re.match(pattern, string, flags=0) # (标准,要匹配的,标志位)
print(re.match('www','www.xxxx.com'))
print(re.match('www','www.xxxx.com').span())
print(re.match('com','www.xxxx.com'))<re.Match object; span=(0, 3), match='www'> (0, 3) None
import re
a = 'life is short,i use python,i love python'
r = re.search('life(.*)python(.*)python',a)
print(r.group(0)) # 完整正则匹配 ,life is short,i use python,i love python
print(r.group(1)) # 第1个分组之间的取值 is short,i use
print(r.group(2)) # 第2个分组之间的取值 ,i love
print(r.group(0,1,2)) # 以元组形式返回3个结果取值 ('life is short,i use python,i love python', ' is short,i use ', ',i love ')
print(r.groups()) # 返回就是group(1)和group(2) (' is short,i use ', ',i love ')import re
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
# (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
# re.M 多行匹配,影响 ^ 和 $
# re.I 使匹配对大小写不敏感
line = "Cats are smarter than dogs"
matchObj1 = re.match(r'(.*) are (.*?) .*', line, re.M|re.I)
matchObj2 = re.match(r'(.*) smarter (.*?) .*', line, re.M|re.I)
matchObj3 = re.match(r'(.*) than (.*)', line, re.M|re.I)
print(matchObj1)
print(matchObj2)
print(matchObj3)
# <re.Match object; span=(0, 26), match='Cats are smarter than dogs'>
# <re.Match object; span=(0, 26), match='Cats are smarter than dogs'>
# None
if matchObj1:
print ("matchObj1.group() : ", matchObj1.group())
print ("matchObj1.group(1) : ", matchObj1.group(1))
print ("matchObj1.group(2) : ", matchObj1.group(2))
else:
print ("No match!!")
if matchObj2:
print ("matchObj2.group() : ", matchObj2.group())
print ("matchObj2.group(1) : ", matchObj2.group(1))
print ("matchObj2.group(2) : ", matchObj2.group(2))
else:
print ("No match!!")
if matchObj3:
print ("matchObj3.group() : ", matchObj3.group())
print ("matchObj3.group(1) : ", matchObj3.group(1))
print ("matchObj3.group(2) : ", matchObj3.group(2))
else:
print ("No match!!")
# matchObj1.group() : Cats are smarter than dogs
# matchObj1.group(1) : Cats
# matchObj1.group(2) : smarter
# matchObj2.group() : Cats are smarter than dogs
# matchObj2.group(1) : Cats are
# matchObj2.group(2) : than
# matchObj3.group() : Cats are smarter than dogs
# matchObj3.group(1) : Cats are smarter
# matchObj3.group(2) : dogsimport re
# 点 是匹配单个字符
# 星是前面的东西出现0次或无数次
# 点星就是任意字符出现0次或无数次
str = "a b a b"
matchObj1 = re.match(r'a(.*)b', str, re.M|re.I)
matchObj2 = re.match(r'a(.*?)b', str, re.M|re.I)
print("matchObj1.group() : ", matchObj1.group())
print("matchObj2.group() : ", matchObj2.group())
# matchObj1.group() : a b a b
# matchObj2.group() : a b扫描整个字符串并返回第一个成功的匹配。
re.search(pattern, string, flags=0)
import re
line = "cats are smarter than dogs"
matchObj = re.match(r'dogs',line,re.M|re.I)
matchObj1= re.search(r'dogs',line,re.M|re.I)
matchObj2= re.match(r'(.*) dogs',line,re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
if matchObj1:
print ("match --> matchObj1.group() : ", matchObj1.group())
else:
print ("No match!!")
if matchObj2:
print ("match --> matchObj2.group() : ", matchObj2.group())
else:
print ("No match!!")
# No match!!
# match --> matchObj1.group() : dogs
# match --> matchObj2.group() : cats are smarter than dogsre.compile是将正则表达式转换为模式对象
这样可以更有效率匹配。使用compile转换一次之后,以后每次使用模式时就不用进行转换
re.sub('被替换的','替换成的',a)# 把FBI替换成BBQ
import re
a = 'abcFBIabcCIAabc'
r = re.sub('FBI','BBQ',a)
print(r)
# 把FBI替换成BBQ,第4参数写1,证明只替换第一次,默认是0(无限替换)
import re
a = 'abcFBIabcFBIaFBICIAabc'
r = re.sub('FBI','BBQ',a,1)
print(r)
# abcBBQabcCIAabc
# abcBBQabcFBIaFBICIAabc# 把函数当参数传到sub的列表里,实现把业务交给函数去处理,例如将FBI替换成$FBI$
import re
a = 'abcFBIabcFBIaFBICIAabc'
def 函数名(形参):
分段获取 = 形参.group() # group()在正则表达式中用于获取分段截获的字符串,获取到FBI
return '$' + 分段获取 + '$'
r = re.sub('FBI',函数名,a)
print(r)以上是“python的正则表达式怎么用”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





