pythonдёӯйҖ»иҫ‘еӣһеҪ’дёҺйқһзӣ‘зқЈеӯҰд№ зҡ„зӨәдҫӢеҲҶжһҗ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іpythonдёӯйҖ»иҫ‘еӣһеҪ’дёҺйқһзӣ‘зқЈеӯҰд№ зҡ„зӨәдҫӢеҲҶжһҗпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒйҖ»иҫ‘еӣһеҪ’
1.жЁЎеһӢзҡ„дҝқеӯҳдёҺеҠ иҪҪ
жЁЎеһӢи®ӯз»ғеҘҪд№ӢеҗҺпјҢеҸҜд»ҘзӣҙжҺҘдҝқеӯҳпјҢйңҖиҰҒз”ЁеҲ°joblibеә“гҖӮдҝқеӯҳзҡ„ж—¶еҖҷжҳҜpklж јејҸпјҢдәҢиҝӣеҲ¶пјҢйҖҡиҝҮdumpж–№жі•дҝқеӯҳгҖӮеҠ иҪҪзҡ„ж—¶еҖҷйҖҡиҝҮloadж–№жі•еҚіеҸҜгҖӮ
е®үиЈ…joblibпјҡconda install joblib
дҝқеӯҳпјҡjoblib.dump(rf, 'test.pkl')
еҠ иҪҪпјҡestimator = joblib.load('жЁЎеһӢи·Ҝеҫ„')
еҠ иҪҪеҗҺзӣҙжҺҘе°ҶжөӢиҜ•йӣҶд»Је…ҘеҚіеҸҜиҝӣиЎҢйў„жөӢгҖӮ
2.йҖ»иҫ‘еӣһеҪ’еҺҹзҗҶ
йҖ»иҫ‘еӣһеҪ’жҳҜдёҖз§ҚеҲҶзұ»з®—жі•пјҢдҪҶиҜҘеҲҶзұ»зҡ„ж ҮеҮҶпјҢжҳҜйҖҡиҝҮh(x)иҫ“е…ҘеҗҺпјҢдҪҝз”ЁsigmoidеҮҪж•°иҝӣиЎҢиҪ¬жҚўпјҢеҗҢж—¶ж №жҚ®йҳҲеҖјпјҢе°ұиғҪеӨҹй’ҲеҜ№дёҚеҗҢзҡ„h(x)еҖјпјҢиҫ“еҮә0-1д№Ӣй—ҙзҡ„ж•°гҖӮжҲ‘们е°ҶиҝҷдёӘ0-1д№Ӣй—ҙзҡ„иҫ“еҮәпјҢи®ӨдёәжҳҜжҰӮзҺҮгҖӮеҒҮи®ҫйҳҲеҖјжҳҜ0.5пјҢйӮЈд№ҲпјҢеӨ§дәҺ0.5зҡ„жҲ‘们и®ӨдёәжҳҜ1пјҢеҗҰеҲҷи®ӨдёәжҳҜ0гҖӮйҖ»иҫ‘еӣһеҪ’йҖӮз”ЁдәҺдәҢеҲҶзұ»й—®йўҳгҖӮ
в‘ йҖ»иҫ‘еӣһеҪ’зҡ„иҫ“е…Ҙ
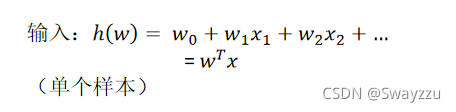
еҸҜд»ҘзңӢеҮәпјҢиҫ“е…ҘиҝҳжҳҜзәҝжҖ§еӣһеҪ’зҡ„жЁЎеһӢпјҢйҮҢйқўиҝҳжҳҜжңүжқғйҮҚwпјҢд»ҘеҸҠзү№еҫҒеҖјxпјҢжҲ‘们зҡ„зӣ®ж Үдҫқж—§жҳҜжүҫеҮәжңҖеҗҲйҖӮзҡ„wгҖӮ
в‘ЎsigmoidеҮҪж•°
иҜҘеҮҪж•°еӣҫеғҸеҰӮдёӢпјҡ
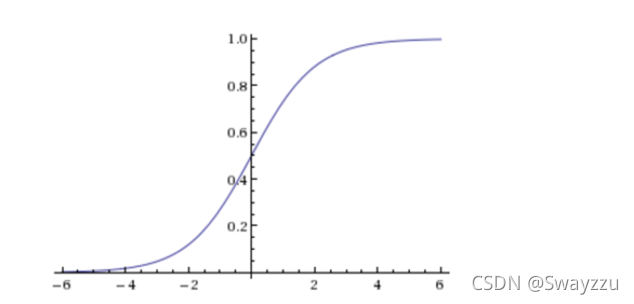
иҜҘеҮҪж•°е…¬ејҸеҰӮдёӢпјҡ

zе°ұжҳҜеӣһеҪ’зҡ„з»“жһңh(x)пјҢйҖҡиҝҮsigmoidеҮҪж•°зҡ„иҪ¬еҢ–пјҢж— и®әzжҳҜд»Җд№ҲеҖјпјҢиҫ“еҮәйғҪжҳҜеңЁ0-1д№Ӣй—ҙгҖӮйӮЈд№ҲжҲ‘们йңҖиҰҒйҖүжӢ©жңҖеҗҲйҖӮзҡ„жқғйҮҚwпјҢдҪҝеҫ—иҫ“еҮәзҡ„жҰӮзҺҮеҸҠжүҖеҫ—з»“жһңпјҢиғҪеӨҹе°ҪеҸҜиғҪең°иҙҙиҝ‘и®ӯз»ғйӣҶзҡ„зӣ®ж ҮеҖјгҖӮеӣ жӯӨпјҢйҖ»иҫ‘еӣһеҪ’д№ҹжңүдёҖдёӘжҚҹеӨұеҮҪж•°пјҢз§°дёәеҜ№ж•°дјјз„¶жҚҹеӨұеҮҪж•°гҖӮе°Ҷе…¶жңҖе°ҸеҢ–пјҢдҫҝеҸҜжұӮеҫ—зӣ®ж ҮwгҖӮ
в‘ўйҖ»иҫ‘еӣһеҪ’зҡ„жҚҹеӨұеҮҪж•°

жҚҹеӨұеҮҪж•°еңЁy=1е’Ң0зҡ„ж—¶еҖҷзҡ„еҮҪж•°еӣҫеғҸеҰӮдёӢпјҡ
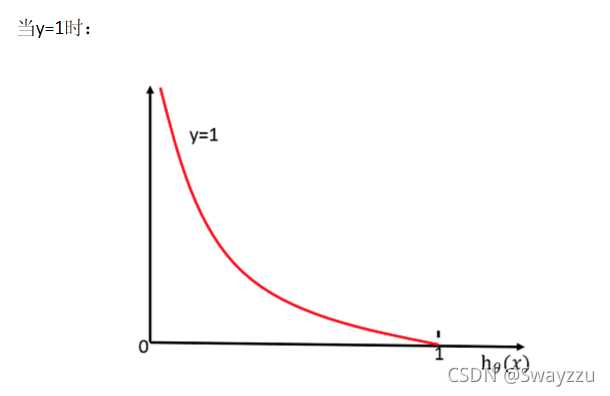
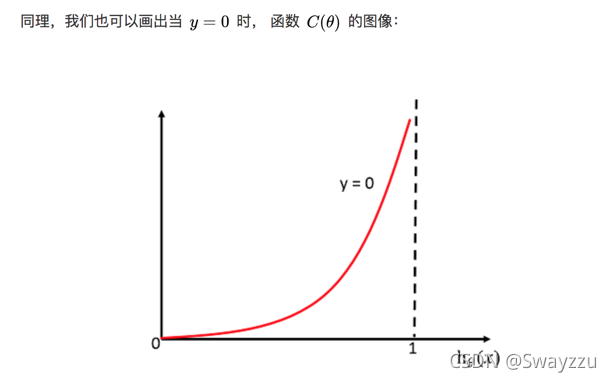
з”ұдёҠеӣҫеҸҜзңӢеҮәпјҢиӢҘзңҹе®һеҖјзұ»еҲ«жҳҜ1пјҢеҲҷh(x)з»ҷеҮәзҡ„иҫ“еҮәпјҢи¶ҠжҺҘиҝ‘дәҺ1пјҢжҚҹеӨұеҮҪж•°и¶Ҡе°ҸпјҢеҸҚд№Ӣи¶ҠеӨ§гҖӮеҪ“y=0ж—¶еҗҢзҗҶгҖӮжүҖд»ҘеҸҜжҚ®жӯӨпјҢеҪ“жҚҹеӨұеҮҪж•°жңҖе°Ҹзҡ„ж—¶еҖҷпјҢжҲ‘们зҡ„зӣ®ж Үе°ұжүҫеҲ°дәҶгҖӮ
в‘ЈйҖ»иҫ‘еӣһеҪ’зү№зӮ№
йҖ»иҫ‘еӣһеҪ’д№ҹжҳҜйҖҡиҝҮжўҜеәҰдёӢйҷҚиҝӣиЎҢзҡ„жұӮи§ЈгҖӮеҜ№дәҺеқҮж–№иҜҜе·®жқҘиҜҙпјҢеҸӘжңүдёҖдёӘжңҖе°ҸеҖјпјҢдёҚеӯҳеңЁеұҖйғЁжңҖдҪҺзӮ№пјӣдҪҶеҜ№дәҺеҜ№ж•°дјјз„¶жҚҹеӨұпјҢеҸҜиғҪдјҡеҮәзҺ°еӨҡдёӘеұҖйғЁжңҖе°ҸеҖјпјҢзӣ®еүҚжІЎжңүдёҖдёӘиғҪе®Ңе…Ёи§ЈеҶіеұҖйғЁжңҖе°ҸеҖјй—®йўҳзҡ„ж–№жі•гҖӮеӣ жӯӨпјҢжҲ‘们еҸӘиғҪйҖҡиҝҮеӨҡж¬ЎйҡҸжңәеҲқе§ӢеҢ–пјҢд»ҘеҸҠи°ғж•ҙеӯҰд№ зҺҮзҡ„ж–№жі•жқҘе°ҪйҮҸйҒҝе…ҚгҖӮдёҚиҝҮпјҢеҚідҪҝжңҖеҗҺзҡ„з»“жһңжҳҜеұҖйғЁжңҖдјҳи§ЈпјҢдҫқж—§жҳҜдёҖдёӘдёҚй”ҷзҡ„жЁЎеһӢгҖӮ
3.йҖ»иҫ‘еӣһеҪ’API
sklearn.linear_model.LogisticRegression

е…¶дёӯpenaltyжҳҜжӯЈеҲҷеҢ–ж–№ејҸпјҢCжҳҜжғ©зҪҡеҠӣеәҰгҖӮ
4.йҖ»иҫ‘еӣһеҪ’жЎҲдҫӢ
в‘ жЎҲдҫӢжҰӮиҝ°
з»ҷе®ҡзҡ„ж•°жҚ®дёӯпјҢжҳҜйҖҡиҝҮеӨҡдёӘзү№еҫҒпјҢз»јеҗҲеҲӨж–ӯиӮҝзҳӨжҳҜеҗҰдёәжҒ¶жҖ§гҖӮ
в‘Ўе…·дҪ“жөҒзЁӢ
з”ұдәҺз®—жі•зҡ„жөҒзЁӢеҹәжң¬дёҖиҮҙпјҢйҮҚзӮ№йғҪеңЁдәҺж•°жҚ®е’Ңзү№еҫҒзҡ„еӨ„зҗҶпјҢеӣ жӯӨжң¬ж–ҮдёӯдёҚеҶҚиҜҰз»Ҷйҳҗиҝ°пјҢд»Јз ҒеҰӮдёӢпјҡ
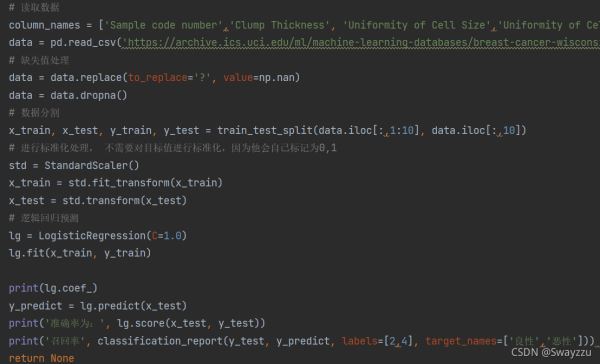
жіЁж„Ҹпјҡ
йҖ»иҫ‘еӣһеҪ’зҡ„зӣ®ж ҮеҖјдёҚжҳҜ0е’Ң1пјҢиҖҢжҳҜ2е’Ң4пјҢдҪҶдёҚйңҖиҰҒиҝӣиЎҢеӨ„зҗҶпјҢз®—жі•дёӯдјҡиҮӘеҠЁж Үи®°дёә0е’Ң1
з®—жі•йў„жөӢе®ҢжҜ•еҗҺпјҢеҰӮжһңжғізңӢеҸ¬еӣһзҺҮпјҢйңҖиҰҒжіЁж„ҸеҜ№жүҖеҲҶзҡ„зұ»еҲ«з»ҷеҮәеҗҚеӯ—пјҢдҪҶз»ҷеҗҚеӯ—д№ӢеүҚйңҖиҰҒе…Ҳиҙҙж ҮзӯҫгҖӮи§ҒдёҠеӣҫгҖӮеҗҰеҲҷж–№жі•дёҚзҹҘйҒ“е“ӘдёӘжҳҜиүҜжҖ§пјҢе“ӘдёӘжҳҜжҒ¶жҖ§гҖӮиҙҙж Үзӯҫзҡ„ж—¶еҖҷйЎәеәҸйңҖеҜ№еә”еҘҪгҖӮ
дёҖиҲ¬жғ…еҶөдёӢпјҢе“ӘдёӘзұ»еҲ«зҡ„ж ·жң¬е°‘пјҢе°ұжҢүз…§е“ӘдёӘжқҘеҺ»еҲӨе®ҡгҖӮжҜ”еҰӮжҒ¶жҖ§зҡ„е°‘пјҢе°ұд»ҘвҖңеҲӨж–ӯеұһдәҺжҒ¶жҖ§зҡ„жҰӮзҺҮжҳҜеӨҡе°‘вҖқжқҘеҺ»еҲӨж–ӯ
5.йҖ»иҫ‘еӣһеҪ’жҖ»з»“
еә”з”Ёпјҡе№ҝе‘ҠзӮ№еҮ»зҺҮйў„жөӢгҖҒжҳҜеҗҰжӮЈз—…зӯүдәҢеҲҶзұ»й—®йўҳ
дјҳзӮ№пјҡйҖӮеҗҲйңҖиҰҒеҫ—еҲ°дёҖдёӘеҲҶзұ»жҰӮзҺҮзҡ„еңәжҷҜ
зјәзӮ№пјҡеҪ“зү№еҫҒз©әй—ҙеҫҲеӨ§ж—¶пјҢйҖ»иҫ‘еӣһеҪ’зҡ„жҖ§иғҪдёҚжҳҜеҫҲеҘҪ пјҲзңӢ硬件иғҪеҠӣпјү
дәҢгҖҒйқһзӣ‘зқЈеӯҰд№
йқһзӣ‘зқЈеӯҰд№ е°ұжҳҜпјҢдёҚз»ҷеҮәжӯЈзЎ®зӯ”жЎҲгҖӮд№ҹе°ұжҳҜиҜҙж•°жҚ®дёӯжІЎжңүзӣ®ж ҮеҖјпјҢеҸӘжңүзү№еҫҒеҖјгҖӮ
1.k-meansиҒҡзұ»з®—жі•еҺҹзҗҶ
еҒҮи®ҫиҒҡзұ»зҡ„зұ»еҲ«дёә3зұ»пјҢжөҒзЁӢеҰӮдёӢпјҡ
в‘ йҡҸжңәеңЁж•°жҚ®дёӯжҠҪеҸ–дёүдёӘж ·жң¬пјҢдҪңдёәзұ»еҲ«зҡ„дёүдёӘдёӯеҝғзӮ№
в‘Ўи®Ўз®—еү©дҪҷзҡ„зӮ№еҲҶеҲ«йҒ“дёүдёӘдёӯеҝғзӮ№зҡ„и·қзҰ»пјҢд»ҺдёӯйҖүеҮәи·қзҰ»жңҖиҝ‘зҡ„зӮ№дҪңдёәиҮӘе·ұзҡ„ж Үи®°гҖӮеҪўжҲҗдёүдёӘж—ҸзҫӨ
в‘ўеҲҶеҲ«и®Ўз®—иҝҷдёүдёӘж—ҸзҫӨзҡ„е№іеқҮеҖјпјҢжҠҠдёүдёӘе№іеқҮеҖјдёҺд№ӢеүҚзҡ„дёүдёӘдёӯеҝғзӮ№иҝӣиЎҢжҜ”иҫғгҖӮеҰӮжһңзӣёеҗҢпјҢз»“жқҹиҒҡзұ»пјҢеҰӮжһңдёҚеҗҢпјҢжҠҠдёүдёӘе№іеқҮеҖјдҪңдёәж–°зҡ„иҒҡзұ»дёӯеҝғпјҢйҮҚеӨҚ第дәҢжӯҘгҖӮ
2.k-means API
sklearn.cluster.KMeans

йҖҡеёёжғ…еҶөдёӢпјҢиҒҡзұ»жҳҜеҒҡеңЁеҲҶзұ»д№ӢеүҚгҖӮе…ҲжҠҠж ·жң¬иҝӣиЎҢиҒҡзұ»пјҢеҜ№е…¶иҝӣиЎҢж Үи®°пјҢжҺҘдёӢжқҘжңүж–°зҡ„ж ·жң¬зҡ„ж—¶еҖҷпјҢе°ұеҸҜд»ҘжҢүз…§иҒҡзұ»жүҖз»ҷзҡ„ж ҮеҮҶиҝӣиЎҢеҲҶзұ»гҖӮ
3.иҒҡзұ»жҖ§иғҪиҜ„дј°
в‘ жҖ§иғҪиҜ„дј°еҺҹзҗҶ
з®ҖеҚ•жқҘиҜҙпјҢе°ұжҳҜзұ»дёӯзҡ„жҜҸдёҖдёӘзӮ№пјҢдёҺвҖңзұ»еҶ…зҡ„зӮ№вҖқзҡ„и·қзҰ»пјҢд»ҘеҸҠвҖңзұ»еӨ–зҡ„зӮ№вҖқзҡ„и·қзҰ»гҖӮи·қзҰ»зұ»еҶ…зҡ„зӮ№пјҢи¶Ҡиҝ‘и¶ҠеҘҪгҖӮиҖҢи·қзҰ»зұ»еӨ–зҡ„зӮ№пјҢи¶Ҡиҝңи¶ҠеҘҪгҖӮ

еҰӮжһңsc_i е°ҸдәҺ0пјҢиҜҙжҳҺa_i зҡ„е№іеқҮи·қзҰ»еӨ§дәҺжңҖиҝ‘зҡ„е…¶д»–з°ҮгҖӮ иҒҡзұ»ж•ҲжһңдёҚеҘҪ
еҰӮжһңsc_i и¶ҠеӨ§пјҢиҜҙжҳҺa_i зҡ„е№іеқҮи·қзҰ»е°ҸдәҺжңҖиҝ‘зҡ„е…¶д»–з°ҮгҖӮ иҒҡзұ»ж•ҲжһңеҘҪ
иҪ®е»“зі»ж•°зҡ„еҖјжҳҜд»ӢдәҺ [-1,1] пјҢи¶Ҡи¶Ӣиҝ‘дәҺ1д»ЈиЎЁеҶ…иҒҡеәҰе’ҢеҲҶзҰ»еәҰйғҪзӣёеҜ№иҫғдјҳ
в‘ЎжҖ§иғҪиҜ„дј°API
sklearn.metrics.silhouette_score

иҒҡзұ»з®—жі•е®№жҳ“收ж•ӣеҲ°еұҖйғЁжңҖдјҳпјҢеҸҜйҖҡиҝҮеӨҡж¬ЎиҒҡзұ»и§ЈеҶігҖӮ
е…ідәҺвҖңpythonдёӯйҖ»иҫ‘еӣһеҪ’дёҺйқһзӣ‘зқЈеӯҰд№ зҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





