иҝҷзҜҮвҖңејҖжәҗж—Ҙеҝ—еә“Loggerжһ¶жһ„жҳҜд»Җд№ҲвҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңејҖжәҗж—Ҙеҝ—еә“Loggerжһ¶жһ„жҳҜд»Җд№ҲвҖқж–Үз« еҗ§гҖӮ
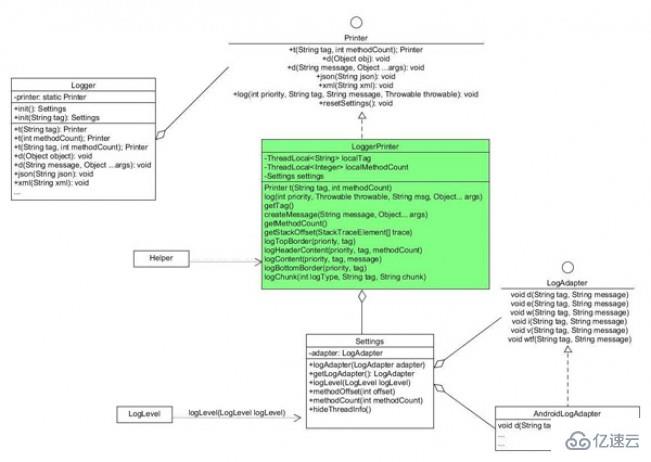
еә“зҡ„ж•ҙдҪ“жһ¶жһ„еӣҫ иҜҰз»Ҷеү–жһҗ жҲ‘们д»ҺдҪҝз”Ёзҡ„и§’еәҰжқҘеҜ№Loggerеә“жҠҪиҢ§еүҘдёқпјҡ
String userName = "Jerry";
Logger.i(userName); зңӢзңӢLogger.i()иҝҷдёӘж–№жі•пјҡ
public static void i(String message, Object... args) {
printer.i(message, args);
} иҝҳжңүдёӘеҸҜеҸҳеҸӮж•°пјҢжқҘзңӢзңӢprinter.i(message, args)жҳҜе•Ҙпјҡ
public Interface Printer{
void i(String message, Object... args);
} жҳҜдёӘжҺҘеҸЈпјҢйӮЈжҲ‘们е°ұиҰҒжүҫеҲ°иҝҷдёӘжҺҘеҸЈзҡ„е®һзҺ°зұ»пјҢжүҫеҲ°printerеҜ№иұЎеңЁLoggerзұ»дёӯеЈ°жҳҺзҡ„ең°ж–№пјҡ
private static Printer printer = new LoggerPrinter(); е®һзҺ°зұ»жҳҜLoggerPrinterпјҢиҖҢдё”иҝҷиҝҳжҳҜдёӘйқҷжҖҒзҡ„жҲҗе‘ҳеҸҳйҮҸпјҢиҝҷдёӘйқҷжҖҒжҳҜжңүз”ЁеӨ„зҡ„пјҢеҗҺйқўдјҡи®ІеҲ°пјҢйӮЈе°ұ继з»ӯи·ҹиёӘLoggerPrinterзұ»зҡ„i(String message, Object… args)ж–№жі•зҡ„е®һзҺ°пјҡ
@Override public void i(String message, Object... args) {log(INFO, null, message, args);
}
/**
* This method is synchronized in order to avoid messy of logs' order.
*/
private synchronized void log(int priority, Throwable throwable, String msg, Object... args) {
// еҲӨж–ӯеҪ“еүҚи®ҫзҪ®зҡ„ж—Ҙеҝ—зә§еҲ«пјҢдёәNONEеҲҷдёҚжү“еҚ°ж—Ҙеҝ—
if (settings.getLogLevel() == LogLevel.NONE) {
return;
}
// иҺ·еҸ–tag
String tag = getTag();
// еҲӣе»әжү“еҚ°зҡ„ж¶ҲжҒҜ
String message = createMessage(msg, args);
// жү“еҚ°
log(priority, tag, message, throwable);
}
public enum LogLevel {
/**
* Prints all logs
*/
FULL,
/**
* No log will be printed
*/
NONE
} йҰ–е…ҲпјҢlogж–№жі•жҳҜдёҖдёӘзәҝзЁӢе®үе…Ёзҡ„еҗҢжӯҘж–№жі•пјҢдёәдәҶйҳІжӯўж—Ҙеҝ—жү“еҚ°ж—¶еҖҷйЎәеәҸзҡ„й”ҷд№ұпјҢеңЁеӨҡзәҝзЁӢзҺҜеўғдёӢпјҢиҝҷжҳҜйқһеёёжңүеҝ…иҰҒзҡ„гҖӮ е…¶ж¬ЎпјҢеҲӨж–ӯж—Ҙеҝ—й…ҚзҪ®зҡ„жү“еҚ°зә§еҲ«пјҢFULLжү“еҚ°е…ЁйғЁж—Ҙеҝ—пјҢNONEдёҚжү“еҚ°ж—Ҙеҝ—гҖӮ еҶҚжқҘпјҢgetTag()пјҡ
private final ThreadLocal localTag = new ThreadLocal();
/**
* @return the appropriate tag based on local or global */
private String getTag() {
// д»ҺThreadLocal localTagйҮҢиҺ·еҸ–жң¬ең°дёҖдёӘзј“еӯҳзҡ„tag
String tag = localTag.get();if (tag != null) {
localTag.remove();return tag;
}return this.tag;
} иҝҷдёӘж–№жі•жҳҜиҺ·еҸ–жң¬ең°жҲ–иҖ…е…ЁеұҖзҡ„tagеҖјпјҢеҪ“localTagдёӯжңүtagзҡ„ж—¶еҖҷе°ұиҝ”еӣһеҮәеҺ»пјҢ并且清з©әlocalTagзҡ„еҖј
жҺҘзқҖпјҢcreateMessageж–№жі•пјҡ
private String createMessage(String message, Object... args) {return args == null || args.length == 0 ? message : String.format(message, args);
} иҝҷйҮҢе°ұеҫҲжё…жҘҡдәҶпјҢдёәд»Җд№ҲжҲ‘们用Logger.i(message, args)зҡ„ж—¶еҖҷжІЎжңүеҶҷargsпјҢд№ҹе°ұжҳҜnullпјҢд№ҹеҸҜд»Ҙжү“еҚ°пјҢиҖҢдё”жҳҜзӣҙжҺҘжү“еҚ°зҡ„messageж¶ҲжҒҜзҡ„еҺҹеӣ гҖӮеҗҢж ·еҚҡдё»дёҠдёҖзҜҮж–Үз« д№ҹжҸҗеҲ°дәҶпјҡ
Logger.i("еҚҡдё»д»Ҡе№ҙжүҚ%dпјҢиӢұж–ҮеҗҚжҳҜ%s", 16, "Jerry"); еғҸиҝҷж ·зҡ„еҸҜд»ҘжӢјжҺҘдёҚеҗҢж јејҸзҡ„ж•°жҚ®зҡ„жү“еҚ°ж—Ҙеҝ—пјҢеҺҹжқҘе®һзҺ°зҡ„ж–№ејҸжҳҜз”ЁString.formatж–№жі•пјҢиҝҷдёӘжғіеҝ…е°Ҹдјҷдјҙ们еңЁејҖеҸ‘Androidеә”з”Ёзҡ„ж—¶еҖҷString.xmlйҮҢзҡ„еҠЁжҖҒеӯ—з¬ҰеҚ дҪҚз¬Ұз”Ёзҡ„д№ҹдёҚе°‘пјҢеә”иҜҘеҫҲе®№жҳ“зҗҶи§ЈиҝҷдёӘformatж–№жі•зҡ„з”Ёжі•гҖӮ
йҮҚеӨҙжҲҸпјҢжҲ‘们жҠҠtagпјҢжү“еҚ°зә§еҲ«пјҢжү“еҚ°зҡ„ж¶ҲжҒҜеӨ„зҗҶеҘҪдәҶпјҢжҺҘдёӢжқҘиҜҘжү“еҚ°еҮәжқҘдәҶпјҡ
@Override public synchronized void log(int priority, String tag, String message, Throwable throwable) {
// еҗҢж ·еҲӨж–ӯдёҖж¬Ўеә“й…ҚзҪ®зҡ„жү“еҚ°ејҖе…іпјҢдёәNONEеҲҷдёҚжү“еҚ°ж—Ҙеҝ—if (settings.getLogLevel() == LogLevel.NONE) {return;
}
// ејӮеёёе’Ңж¶ҲжҒҜдёҚдёәз©әзҡ„ж—¶еҖҷпјҢиҺ·еҸ–ејӮеёёзҡ„еҺҹеӣ иҪ¬жҚўжҲҗеӯ—з¬ҰдёІеҗҺжӢјжҺҘеҲ°жү“еҚ°зҡ„ж¶ҲжҒҜдёӯif (throwable != null && message != null) {
message += " : " + Helper.getStackTraceString(throwable);
}if (throwable != null && message == null) {
message = Helper.getStackTraceString(throwable);
}if (message == null) {
message = "No message/exception is set";
}
// иҺ·еҸ–ж–№жі•ж•°
int methodCount = getMethodCount();
// еҲӨж–ӯж¶ҲжҒҜжҳҜеҗҰдёәз©әif (Helper.isEmpty(message)) {
message = "Empty/NULL log message";
}
// жү“еҚ°ж—Ҙеҝ—дҪ“зҡ„дёҠиҫ№з•Ң
logTopBorder(priority, tag);
// жү“еҚ°ж—Ҙеҝ—дҪ“зҡ„еӨҙйғЁеҶ…е®№
logHeaderContent(priority, tag, methodCount);
//get bytes of message with system's default charset (which is UTF-8 for Android)
byte[] bytes = message.getBytes();
int length = bytes.length;
// ж¶ҲжҒҜеӯ—иҠӮй•ҝеәҰе°ҸдәҺзӯүдәҺ4000
if (length 0) {
// ж–№жі•ж•°еӨ§дәҺ0пјҢжү“еҚ°еҮәеҲҶеүІзәҝ
logDivider(priority, tag);
}
// жү“еҚ°ж¶ҲжҒҜеҶ…е®№
logContent(priority, tag, message);
// жү“еҚ°ж—Ҙеҝ—дҪ“еә•йғЁиҫ№з•Ң
logBottomBorder(priority, tag);
return;
}
if (methodCount > 0) {
logDivider(priority, tag);
}
for (int i = 0; i s default charset (which is UTF-8 for Android)
logContent(priority, tag, new String(bytes, i, count));
}
logBottomBorder(priority, tag);
} жҲ‘们йҮҚзӮ№жқҘзңӢзңӢlogHeaderContentж–№жі•е’ҢlogContentж–№жі•пјҡ
@SuppressWarnings("StringBufferReplaceableByString")
private void logHeaderContent(int logType, String tag, int methodCount) {
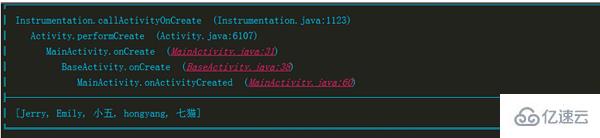
// иҺ·еҸ–еҪ“еүҚзәҝзЁӢе Ҷж Ҳи·ҹиёӘе…ғзҙ ж•°з»„
//пјҲйҮҢйқўеӯҳеӮЁдәҶиҷҡжӢҹжңәи°ғз”Ёзҡ„ж–№жі•зҡ„дёҖдәӣдҝЎжҒҜпјҡж–№жі•еҗҚгҖҒзұ»еҗҚгҖҒи°ғз”ЁжӯӨж–№жі•еңЁж–Ү件дёӯзҡ„иЎҢж•°пјү
// иҝҷд№ҹжҳҜиҝҷдёӘеә“зҡ„ вҖңж ёеҝғвҖқ
StackTraceElement[] trace = Thread.currentThread().getStackTrace();
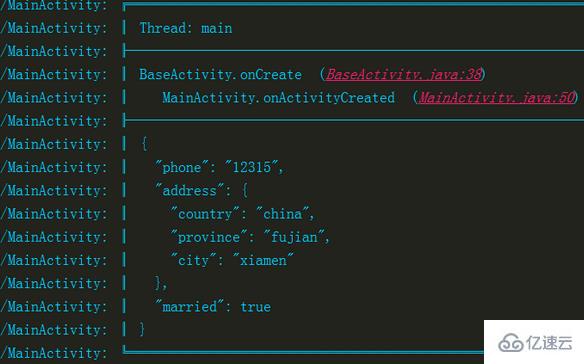
// еҲӨж–ӯеә“зҡ„й…ҚзҪ®жҳҜеҗҰжҳҫзӨәзәҝзЁӢдҝЎжҒҜif (settings.isShowThreadInfo()) {
// иҺ·еҸ–еҪ“еүҚзәҝзЁӢзҡ„еҗҚз§°пјҢ并且жү“еҚ°еҮәжқҘпјҢ然еҗҺжү“еҚ°еҲҶеүІзәҝ
logChunk(logType, tag, HORIZONTAL_DOUBLE_LINE + "Thread: " + Thread.currentThread().getName()); logDivider(logType, tag);
}
String level = "";
// иҺ·еҸ–иҝҪиёӘж Ҳзҡ„ж–№жі•иө·е§ӢдҪҚзҪ®
int stackOffset = getStackOffset(trace) + settings.getMethodOffset();
//corresponding method count with the current stack may exceeds the stack trace. Trims the count
// жү“еҚ°иҝҪиёӘзҡ„ж–№жі•ж•°и¶…иҝҮдәҶеҪ“еүҚзәҝзЁӢиғҪеӨҹиҝҪиёӘзҡ„ж–№жі•ж•°пјҢжҖ»зҡ„иҝҪиёӘж–№жі•ж•°жүЈйҷӨеҒҸ移йҮҸ(д»Һи°ғз”Ёж—Ҙеҝ—зҡ„иө·з®—жүЈйҷӨзҡ„ж–№жі•ж•°)пјҢе°ұжҳҜйңҖиҰҒжү“еҚ°зҡ„ж–№жі•ж•°йҮҸif (methodCount + stackOffset > trace.length) {
methodCount = trace.length - stackOffset - 1;
}for (int i = methodCount; i > 0; i--) {
int stackIndex = i + stackOffset;if (stackIndex >= trace.length) {continue;
}
// жӢјжҺҘж–№жі•е Ҷж Ҳи°ғз”Ёи·Ҝеҫ„иҝҪиёӘеӯ—з¬ҰдёІ
StringBuilder builder = new StringBuilder();
builder.append("U ")
.append(level)
.append(getSimpleClassName(trace[stackIndex].getClassName())) // иҝҪиёӘеҲ°зҡ„зұ»еҗҚ
.append(".")
.append(trace[stackIndex].getMethodName()) // иҝҪиёӘеҲ°зҡ„ж–№жі•еҗҚ
.append(" ")
.append(" (")
.append(trace[stackIndex].getFileName()) // ж–№жі•жүҖеңЁзҡ„ж–Ү件еҗҚ
.append(":")
.append(trace[stackIndex].getLineNumber()) // еңЁж–Ү件дёӯзҡ„иЎҢеҸ·
.append(")");
level += " ";
// жү“еҚ°еҮәеӨҙйғЁдҝЎжҒҜ
logChunk(logType, tag, builder.toString());
}
} жҺҘдёӢжқҘзңӢlogContentж–№жі•пјҡ
private void logContent(int logType, String tag, String chunk) {
// иҝҷдёӘдҪңз”Ёе°ұжҳҜиҺ·еҸ–жҚўиЎҢз¬Ұж•°з»„пјҢgetPropertyж–№жі•иҺ·еҸ–зҡ„е°ұжҳҜ"//n"зҡ„ж„ҸжҖқ
String[] lines = chunk.split(System.getProperty("line.separator"));for (String line : lines) {
// жү“еҚ°еҮәеҢ…еҗ«жҚўиЎҢз¬Ұзҡ„еҶ…е®№
logChunk(logType, tag, HORIZONTAL_DOUBLE_LINE + " " + line);
}
} еҰӮдёҠеӣҫжқҘиҜҙеҶ…е®№жҳҜеӯ—з¬ҰдёІж•°з»„пјҢжң¬иә«йҮҢйқўжҳҜжІЎз”ЁжҚўиЎҢз¬Ұзҡ„пјҢжүҖд»ҘдёҚйңҖиҰҒжҚўиЎҢпјҢжү“еҚ°еҮәжқҘзҡ„ж•Ҳжһңе°ұжҳҜдёҖиЎҢпјҢдҪҶжҳҜjsonгҖҒxmlиҝҷж ·зҡ„ж јејҸжҳҜжңүжҚўиЎҢз¬Ұзҡ„пјҢжүҖд»Ҙжү“еҚ°е‘ҲзҺ°еҮәжқҘзҡ„ж•Ҳжһңе°ұжҳҜпјҡ
дёҠйқўиҜҙдәҶеӨ§еҚҠеӨ©пјҢйғҪиҝҳжІЎзңӢеҲ°е…·дҪ“зҡ„жү“еҚ°жҳҜе•ҘпјҢзҺ°еңЁжқҘзңӢзңӢlogChunkж–№жі•пјҡ
private void logChunk(int logType, String tag, String chunk) {
// жңҖеҗҺж јејҸеҢ–дёӢtag
String finalTag = formatTag(tag);
// ж №жҚ®дёҚеҗҢзҡ„ж—Ҙеҝ—жү“еҚ°зұ»еһӢпјҢ然еҗҺдәӨз»ҷLogAdapterиҝҷдёӘжҺҘеҸЈжқҘжү“еҚ°
switch (logType) {case ERROR:
settings.getLogAdapter().e(finalTag, chunk);break;case INFO:
settings.getLogAdapter().i(finalTag, chunk);break;case VERBOSE:
settings.getLogAdapter().v(finalTag, chunk);break;case WARN:
settings.getLogAdapter().w(finalTag, chunk);break;case ASSERT:
settings.getLogAdapter().wtf(finalTag, chunk);break;case DEBUG:
// Fall through, log debug by default
default:
settings.getLogAdapter().d(finalTag, chunk);break;
}
} иҝҷдёӘж–№жі•еҫҲз®ҖеҚ•пјҢе°ұжҳҜжңҖеҗҺж јејҸеҢ–tagпјҢ然еҗҺж №жҚ®дёҚеҗҢзҡ„ж—Ҙеҝ—зұ»еһӢжҠҠжү“еҚ°зҡ„е·ҘдҪңдәӨз»ҷLogAdapterжҺҘеҸЈжқҘеӨ„зҗҶпјҢжҲ‘们жқҘзңӢзңӢsettings.getLogAdapter()иҝҷдёӘж–№жі•(Settings.javaж–Ү件)пјҡ
public LogAdapter getLogAdapter() {if (logAdapter == null) {
// жңҖз»Ҳзҡ„е®һзҺ°зұ»жҳҜAndroidLogAdapter
logAdapter = new AndroidLogAdapter();
}return logAdapter;
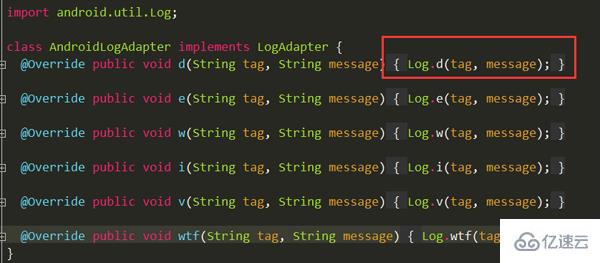
} жүҫеҲ°AndroidLogAdapterзұ»пјҡ
еҺҹжқҘз»•дәҶдёҖеӨ§еңҲпјҢжңҖз»Ҳжү“еҚ°иҝҳжҳҜдҪҝз”ЁдәҶпјҡзі»з»ҹзҡ„LogгҖӮ
еҘҪдәҶLoggerж—Ҙеҝ—жЎҶжһ¶зҡ„жәҗз Ғи§Јжһҗе®ҢдәҶпјҢжңүжІЎжңүжӣҙжё…жҷ°е‘ўпјҢд№ҹи®ёе°ҸдјҷдјҙдјҡиҜҙиҝҷдёӘжңҖз»Ҳзҡ„ж—Ҙеҝ—жү“еҚ°пјҢжҲ‘дёҚжғіз”Ёзі»з»ҹзҡ„LogпјҢжҳҜдёҚжҳҜеҸҜд»ҘжҚўе‘ўгҖӮиҝҷжҳҜиҮӘ然зҡ„пјҢзңӢејҖзҜҮзҡ„йӮЈз§Қж•ҙдҪ“жһ¶жһ„еӣҫпјҢиҝҷдёӘLogAdapterжҳҜдёӘжҺҘеҸЈпјҢеҸӘиҰҒе®һзҺ°иҝҷдёӘжҺҘеҸЈпјҢйҮҢйқўеҒҡдҪ иҮӘе·ұжғіиҰҒжү“еҚ°зҡ„ж–№ејҸпјҢ然еҗҺйҖҡиҝҮSettings зҡ„logAdapter(LogAdapter logAdapter)ж–№жі•и®ҫзҪ®иҝӣеҺ»е°ұеҸҜд»ҘгҖӮ
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңејҖжәҗж—Ҙеҝ—еә“Loggerжһ¶жһ„жҳҜд»Җд№ҲвҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ