本篇内容主要讲解“Python爬虫如何获取数据并保存到数据库中”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Python爬虫如何获取数据并保存到数据库中”吧!
-网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
-一般在浏览器上可以获取到的,通过爬虫也可以获取到,常见的爬虫语言有PHP,JAVA,C#,C++,Python,为啥我们经常听到说的都是Python爬虫,这是因为python爬虫比较简单,功能比较齐全。
通过Xpath进行爬虫就是获取到页面html后通过路径的表达式来选取标签节点,沿着路径选取需要爬取的数据。
Xpath常用表达式:
| 表达式 | 描述 |
|---|---|
| / | 从根节点选取(取子节点) |
| // | 选择的当前节点选择文档中的节点 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性 |
| * | 表示任意内容(通配符) |
| | | 运算符可以选取多个路径 |
Xpath常用函数:
| 函数 | 用法 | 解释 |
|---|---|---|
| startswith() | xpath(‘//div[starts-with(@id,”celent”)]‘) | #选取id值以celent开头的div节点 |
| contains() | xpath(‘//div[contains(@id,”celent”)]‘) | #选取id值包含celent的div节点 |
| and() | xpath(‘//div[contains(@id,”celent”) and contains(@id,”in”)]‘) | #选取id值包含celent的div节点 |
| text() | _.xpath(’./div/div[4]/a/em/text()’) | #选取em标签下文本内容 |
Xpath实操解析:
# 案例1
# //为从当前html中选取节点;[@class="c1text1"]为获取所有的class为c1text1的节点;/h2[1]为选取的节点下的第一个h2节点,如果没有[1]则是获取所有的,可以通过循环进行获取数据
etreeHtml.xpath('//*[@class="c1text1"]/h2[1]/text()')
# 案例2
#//为从当前html中选取节点;[@class="c1text1"]为获取所有的class为c1text1的节点;/a为获取当前节点下的所有a标签节点,得到一个ObjectList;通过for循环获取里面每个标签数据,./@src为获取当前节点的src属性值
etreeHtml2 = etreeHtml.xpath('//*[@class="c1text1"]/a')
for _ in etreeHtml2:
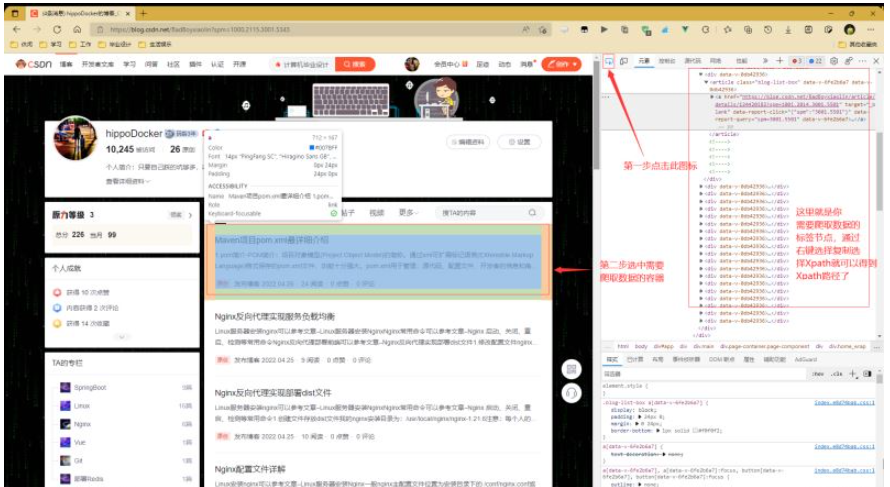
etreeHtml.xpath(./@src)通过F12打开开发者模式,点击左上角图标可参考下图,选择需要爬取数据的容器,在右边选择复制选择xpath就可以得到xpath路径了(//*[@id=“userSkin”]/div[2]/div/div[2]/div[1]/div[2]/div/div);
# 导入需要的库 import requests from lxml import etree import pymysql # 文章详情信息类 class articleData(): def __init__(self, title, abstract, path,date): self.title = title #文章名称 self.abstract = abstract #文章摘要 self.path = path #文章路径 self.date = date #发布时间 def to_string(self): print("文章名称:"+self.title +";文章摘要:"+self.abstract +";文章路径:"+self.path +";发布时间:"+self.date) #保存狗狗详情数据 #保存数据 def saveData(DataObject): count = pymysql.connect( host='xx.xx.xx.xx', # 数据库地址 port=3306, # 数据库端口 user='xxxxx', # 数据库账号 password='xxxxxx', # 数据库密码 db='xxxxxxx' # 数据库名 ) # 创建数据库对象 db = count.cursor() # 写入sql # print("写入数据:"+DataObject.to_string()) sql = f"insert into article_detail(title,abstract,alias,path,date) " \ f"values ('{DataObject.title}','{DataObject.abstract}','{DataObject.path}','{DataObject.date}')" # 执行sql print(sql) db.execute(sql) # 保存修改内容 count.commit() db.close() # 爬取数据的方向 def getWebData(): # 网站页面路径 url = "https://blog.csdn.net/BadBoyxiaolin?spm=1000.2115.3001.5343" # 请求头,模拟浏览器请求 header = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36" } # 获取页面所有节点代码 html = requests.get(url=url, headers=header) # 打印页面代码查看 # print(html.text) # 如果乱码可以设置编码格式 # html.encoding = 'gb2312' # 通过xpath获取数据对应节点 etreeHtml = etree.HTML(html.text) dataHtml = etreeHtml.xpath('//*[@class="mainContent"]/div/div/div') # 循环获取数据 for _ in dataHtml: # ''.join()是将内容转换为字符串可以后面接replace数据进行处理 title = ''.join(_.xpath('./article/a/div[1]/h5/text()'))#文章标题 abstract = ''.join(_.xpath('./article/a/div[2]/text()'))#文章摘要 path = ''.join(_.xpath('./article/a/@href'))#文章路径 date = ''.join(_.xpath('./article/a/div[3]/div/div[2]/text()')).replace(' ','').replace('·','').replace('发布博客','')#发布时间 #初始化文章类数据 article_data = articleData(title,abstract,path,date) article_data.to_string() #打印数据看看是否对 #保存数据到数据库 # saveData(article_data) if __name__ == "__main__": getWebData()
到此,相信大家对“Python爬虫如何获取数据并保存到数据库中”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





