Kotlinзҡ„CollectionдёҺSequenceж“ҚдҪңејӮеҗҢзӮ№жҳҜд»Җд№Ҳ
жң¬ж–Үе°Ҹзј–дёәеӨ§е®¶иҜҰз»Ҷд»Ӣз»ҚвҖңKotlinзҡ„CollectionдёҺSequenceж“ҚдҪңејӮеҗҢзӮ№жҳҜд»Җд№ҲвҖқпјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢз»ҶиҠӮеӨ„зҗҶеҰҘеҪ“пјҢеёҢжңӣиҝҷзҜҮвҖңKotlinзҡ„CollectionдёҺSequenceж“ҚдҪңејӮеҗҢзӮ№жҳҜд»Җд№ҲвҖқж–Үз« иғҪеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘеӯҰд№ ж–°зҹҘиҜҶеҗ§гҖӮ
Collection зҡ„еёёи§Ғж“ҚдҪң
Collection йӣҶеҗҲпјҢKotlinзҡ„йӣҶеҗҲзұ»еһӢе’ҢJavaдёҚдёҖж ·пјҢKotlinзҡ„йӣҶеҗҲеҲҶдёәеҸҜеҸҳпјҲиҜ»еҶҷпјүе’ҢдёҚеҸҜеҸҳпјҲеҸӘиҜ»пјүзұ»еһӢпјҲlists, sets, maps, etcпјүпјҢеҸҜеҸҳзұ»еһӢжҳҜеңЁдёҚеҸҜеҸҳзұ»еһӢеүҚйқўеҠ MutableпјҢд»ҘжҲ‘们常用зҡ„дёүз§ҚйӣҶеҗҲзұ»еһӢдёәдҫӢпјҡ
List<out E> - MutableList<E>
Set<out E> - MutableSet<E>
Map<K, out V> - MutableMap<K, V>
е…¶е®һ他们зҡ„еҢәеҲ«е°ұжҳҜListе®һзҺ°дәҶCollectionжҺҘеҸЈпјҢиҖҢMutableListе®һзҺ°зҡ„жҳҜListе’ҢMutableCollectionжҺҘеҸЈгҖӮиҖҢ MutableCollection жҺҘеҸЈе®һзҺ°дәҶCollection жҺҘеҸЈпјҢ并且еңЁйҮҢйқўж·»еҠ дәҶaddе’Ңremoveзӯүж“ҚдҪңж–№жі•гҖӮ
еҸҜеҸҳдёҚеҸҜеҸҳеҸӘжҳҜдёәдәҶеҢәеҲҶеҸӘиҜ»е’ҢиҜ»еҶҷзҡ„ж“ҚдҪңпјҢ他们зҡ„ж“ҚдҪңз¬Ұж–№ејҸйғҪжҳҜзӣёеҗҢзҡ„гҖӮ
йӣҶеҗҲзҡ„ж“ҚдҪңз¬ҰиҜҙиө·жқҘеҸҜе°ұеӨӘеӨҡдәҶ
зҙҜи®Ў
//еҜ№жүҖжңүе…ғзҙ жұӮе’Ң
list.sum()
//е°ҶйӣҶеҗҲдёӯзҡ„жҜҸдёҖдёӘе…ғзҙ д»Је…ҘlambdaиЎЁиҫҫејҸпјҢ然еҗҺеҜ№lambdaиЎЁиҫҫејҸзҡ„иҝ”еӣһеҖјжұӮе’Ң
list.sumBy {
it % 2
}
//еңЁдёҖдёӘеҲқе§ӢеҖјзҡ„еҹәзЎҖдёҠ,д»Һ第дёҖйЎ№еҲ°жңҖеҗҺдёҖйЎ№йҖҡиҝҮдёҖдёӘеҮҪж•°зҙҜи®ЎжүҖжңүзҡ„е…ғзҙ
list.fold(100) { accumulator, element ->
accumulator + element / 2
}
//еҗҢfoldпјҢеҸӘжҳҜиҝӯд»Јзҡ„ж–№еҗ‘зӣёеҸҚ
list.foldRight(100) { accumulator, element ->
accumulator + element / 2
}
//еҗҢfoldпјҢеҸӘжҳҜaccumulatorзҡ„еҲқе§ӢеҖје°ұжҳҜйӣҶеҗҲзҡ„第дёҖдёӘе…ғзҙ пјҢelementд»Һ第дәҢдёӘе…ғзҙ ејҖе§Ӣ
list.reduce { accumulator, element ->
accumulator + element / 2
}
//еҗҢreduceдҪҶж–№еҗ‘зӣёеҸҚпјҡaccumulatorзҡ„еҲқе§ӢеҖје°ұжҳҜйӣҶеҗҲзҡ„жңҖеҗҺдёҖдёӘе…ғзҙ пјҢelementд»ҺеҖ’数第дәҢдёӘе…ғзҙ ејҖе§ӢеҫҖеүҚиҝӯд»Ј
list.reduceRight { accumulator, element ->
accumulator + element / 2
}
val list = listOf(1, 2, 3, 4, 5, 6)
//еҸӘиҰҒйӣҶеҗҲдёӯзҡ„д»»дҪ•дёҖдёӘе…ғзҙ ж»Ўи¶іжқЎд»¶(дҪҝеҫ—lambdaиЎЁиҫҫејҸиҝ”еӣһtrue)пјҢanyеҮҪж•°е°ұиҝ”еӣһtrue
list.any {
it >= 0
}
//йӣҶеҗҲдёӯзҡ„е…ЁйғЁе…ғзҙ йғҪж»Ўи¶іжқЎд»¶(дҪҝеҫ—lambdaиЎЁиҫҫејҸиҝ”еӣһtrue)пјҢallеҮҪж•°жүҚиҝ”еӣһtrue
list.all {
it >= 0
}
//иӢҘйӣҶеҗҲдёӯжІЎжңүе…ғзҙ ж»Ўи¶іжқЎд»¶пјҲдҪҝlambdaиЎЁиҫҫејҸиҝ”еӣһtrueпјүпјҢеҲҷnoneеҮҪж•°иҝ”еӣһtrue
list.none {
it < 0
}
//countеҮҪж•°зҡ„иҝ”еӣһеҖјдёәпјҡйӣҶеҗҲдёӯж»Ўи¶іжқЎд»¶зҡ„е…ғзҙ зҡ„жҖ»ж•°
list.count {
it >= 0
}йҒҚеҺҶ
//йҒҚеҺҶжүҖжңүе…ғзҙ
list.forEach {
print(it)
}
//еҗҢforEachпјҢеҸӘжҳҜеҸҜд»ҘеҗҢж—¶жӢҝеҲ°е…ғзҙ зҡ„зҙўеј•
list.forEachIndexed { index, value ->
println("position $index contains a $value")
}
showFields.forEach { (key, value) ->жңҖеӨ§жңҖе°Ҹ
//иҝ”еӣһйӣҶеҗҲдёӯжңҖеӨ§зҡ„е…ғзҙ пјҢйӣҶеҗҲдёәз©ә(empty)еҲҷиҝ”еӣһnull
list.max()
//иҝ”еӣһйӣҶеҗҲдёӯдҪҝеҫ—lambdaиЎЁиҫҫејҸиҝ”еӣһеҖјжңҖеӨ§зҡ„е…ғзҙ пјҢйӣҶеҗҲдёәз©ә(empty)еҲҷиҝ”еӣһnull
list.maxBy { it }
//иҝ”еӣһйӣҶеҗҲдёӯжңҖе°Ҹзҡ„е…ғзҙ пјҢйӣҶеҗҲдёәз©ә(empty)еҲҷиҝ”еӣһnull
list.min()
//иҝ”еӣһйӣҶеҗҲдёӯдҪҝеҫ—lambdaиЎЁиҫҫејҸиҝ”еӣһеҖјжңҖе°Ҹзҡ„е…ғзҙ пјҢйӣҶеҗҲдёәз©ә(empty)еҲҷиҝ”еӣһnull
list.minBy { it }иҝҮж»Ө(еҺ»йҷӨ)
//иҝ”еӣһдёҖдёӘж–°ListпјҢеҺ»йҷӨйӣҶеҗҲзҡ„еүҚnдёӘе…ғзҙ
list.drop(2)
//иҝ”еӣһдёҖдёӘж–°ListпјҢеҺ»йҷӨйӣҶеҗҲзҡ„еҗҺnдёӘе…ғзҙ
list.dropLast(2)
//иҝ”еӣһдёҖдёӘж–°ListпјҢеҺ»йҷӨйӣҶеҗҲдёӯж»Ўи¶іжқЎд»¶(lambdaиҝ”еӣһtrue)зҡ„第дёҖдёӘе…ғзҙ
list.dropWhile {
it > 3
}
//иҝ”еӣһдёҖдёӘж–°ListпјҢеҺ»йҷӨйӣҶеҗҲдёӯж»Ўи¶іжқЎд»¶(lambdaиҝ”еӣһtrue)зҡ„жңҖеҗҺдёҖдёӘе…ғзҙ
list.dropLastWhile {
it > 3
}
//иҝ”еӣһдёҖдёӘж–°ListпјҢеҢ…еҗ«еүҚйқўзҡ„nдёӘе…ғзҙ
list.take(2)
//иҝ”еӣһдёҖдёӘж–°ListпјҢеҢ…еҗ«жңҖеҗҺзҡ„nдёӘе…ғзҙ
list.takeLast(2)
//иҝ”еӣһдёҖдёӘж–°ListпјҢд»…дҝқз•ҷйӣҶеҗҲдёӯж»Ўи¶іжқЎд»¶(lambdaиҝ”еӣһtrue)зҡ„第дёҖдёӘе…ғзҙ
list.takeWhile {
it>3
}
//иҝ”еӣһдёҖдёӘж–°ListпјҢд»…дҝқз•ҷйӣҶеҗҲдёӯж»Ўи¶іжқЎд»¶(lambdaиҝ”еӣһtrue)зҡ„жңҖеҗҺдёҖдёӘе…ғзҙ
list.takeLastWhile {
it>3
}
//иҝ”еӣһдёҖдёӘж–°ListпјҢд»…дҝқз•ҷйӣҶеҗҲдёӯж»Ўи¶іжқЎд»¶(lambdaиҝ”еӣһtrue)зҡ„е…ғзҙ пјҢе…¶д»–зҡ„йғҪеҺ»жҺү
list.filter {
it > 3
}
//иҝ”еӣһдёҖдёӘж–°ListпјҢд»…дҝқз•ҷйӣҶеҗҲдёӯдёҚж»Ўи¶іжқЎд»¶зҡ„е…ғзҙ пјҢе…¶д»–зҡ„йғҪеҺ»жҺү
list.filterNot {
it > 3
}
//иҝ”еӣһдёҖдёӘж–°ListпјҢд»…дҝқз•ҷйӣҶеҗҲдёӯзҡ„йқһз©әе…ғзҙ
list.filterNotNull()
//иҝ”еӣһдёҖдёӘж–°ListпјҢд»…дҝқз•ҷжҢҮе®ҡзҙўеј•еӨ„зҡ„е…ғзҙ
list.slice(listOf(0, 1, 2))жҳ е°„
//е°ҶйӣҶеҗҲдёӯзҡ„жҜҸдёҖдёӘе…ғзҙ д»Је…ҘlambdaиЎЁиҫҫејҸпјҢlambdaиЎЁиҫҫејҸеҝ…йЎ»иҝ”еӣһдёҖдёӘе…ғзҙ
//mapзҡ„иҝ”еӣһеҖјжҳҜжүҖжңүlambdaиЎЁиҫҫејҸзҡ„иҝ”еӣһеҖјжүҖз»„жҲҗзҡ„ж–°List
//дҫӢеҰӮдёӢйқўзҡ„д»Јз Ғе’ҢlistOf(2,4,6,8,10,12)е°Ҷдә§з”ҹзӣёеҗҢзҡ„List
list.map {
it * 2
}
//е°ҶйӣҶеҗҲдёӯзҡ„жҜҸдёҖдёӘе…ғзҙ д»Је…ҘlambdaиЎЁиҫҫејҸпјҢlambdaиЎЁиҫҫејҸеҝ…йЎ»иҝ”еӣһдёҖдёӘйӣҶеҗҲ
//иҖҢflatMapзҡ„иҝ”еӣһеҖјжҳҜжүҖжңүlambdaиЎЁиҫҫејҸиҝ”еӣһзҡ„йӣҶеҗҲдёӯзҡ„е…ғзҙ жүҖз»„жҲҗзҡ„ж–°List
//дҫӢеҰӮдёӢйқўзҡ„д»Јз Ғе’ҢlistOf(1,2,2,3,3,4,4,5,5,6,6,7)е°Ҷдә§з”ҹзӣёеҗҢзҡ„List
list.flatMap {
listOf(it, it + 1)
}
//е’ҢmapдёҖж ·пјҢеҸӘжҳҜlambdaиЎЁиҫҫејҸзҡ„еҸӮж•°еӨҡдәҶдёҖдёӘindex
list.mapIndexed { index, it ->
index * it
}
//е’ҢmapдёҖж ·пјҢеҸӘдёҚиҝҮеҸӘжңүlambdaиЎЁиҫҫејҸзҡ„йқһз©әиҝ”еӣһеҖјжүҚдјҡиў«еҢ…еҗ«еңЁж–°Listдёӯ
list.mapNotNull {
it * 2
}
//ж №жҚ®lambdaиЎЁиҫҫејҸеҜ№йӣҶеҗҲе…ғзҙ иҝӣиЎҢеҲҶз»„пјҢиҝ”еӣһдёҖдёӘMap
//lambdaиЎЁиҫҫејҸзҡ„иҝ”еӣһеҖје°ұжҳҜmapдёӯе…ғзҙ зҡ„key
//дҫӢеҰӮдёӢйқўзҡ„д»Јз Ғе’ҢmapOf("even" to listOf(2,4,6),"odd" to listOf(1,3,5))е°Ҷдә§з”ҹзӣёеҗҢзҡ„map
list.groupBy {
if (it % 2 == 0) "even" else "odd"
}е…ғзҙ
list.contains(2)
list.elementAt(0)
//иҝ”еӣһжҢҮе®ҡзҙўеј•еӨ„зҡ„е…ғзҙ пјҢиӢҘзҙўеј•и¶Ҡз•ҢпјҢеҲҷиҝ”еӣһnull
list.elementAtOrNull(10)
//иҝ”еӣһжҢҮе®ҡзҙўеј•еӨ„зҡ„е…ғзҙ пјҢиӢҘзҙўеј•и¶Ҡз•ҢпјҢеҲҷиҝ”еӣһlambdaиЎЁиҫҫејҸзҡ„иҝ”еӣһеҖј
list.elementAtOrElse(10) { index ->
index * 2
}
//иҝ”еӣһlistзҡ„第дёҖдёӘе…ғзҙ
list.first()
//иҝ”еӣһlistдёӯж»Ўи¶іжқЎд»¶зҡ„第дёҖдёӘе…ғзҙ
list.first {
it > 1
}
//иҝ”еӣһlistзҡ„第дёҖдёӘе…ғзҙ ,listдёәemptyеҲҷиҝ”еӣһnull
list.firstOrNull()
//иҝ”еӣһlistдёӯж»Ўи¶іжқЎд»¶зҡ„第дёҖдёӘе…ғзҙ пјҢжІЎжңүж»Ўи¶іжқЎд»¶зҡ„еҲҷиҝ”еӣһnull
list.firstOrNull {
it > 1
}
list.last()
list.last { it > 1 }
list.lastOrNull()
list.lastOrNull { it > 1 }
//иҝ”еӣһе…ғзҙ 2第дёҖж¬ЎеҮәзҺ°еңЁlistдёӯзҡ„зҙўеј•пјҢиӢҘдёҚеӯҳеңЁеҲҷиҝ”еӣһ-1
list.indexOf(2)
//иҝ”еӣһе…ғзҙ 2жңҖеҗҺдёҖж¬ЎеҮәзҺ°еңЁlistдёӯзҡ„зҙўеј•пјҢиӢҘдёҚеӯҳеңЁеҲҷиҝ”еӣһ-1
list.lastIndexOf(2)
//иҝ”еӣһж»Ўи¶іжқЎд»¶зҡ„第дёҖдёӘе…ғзҙ зҡ„зҙўеј•
list.indexOfFirst {
it > 2
}
//иҝ”еӣһж»Ўи¶іжқЎд»¶зҡ„жңҖеҗҺдёҖдёӘе…ғзҙ зҡ„зҙўеј•
list.indexOfLast {
it > 2
}
//иҝ”еӣһж»Ўи¶іжқЎд»¶зҡ„е”ҜдёҖе…ғзҙ пјҢеҰӮжһңжІЎжңүж»Ўи¶іжқЎд»¶зҡ„е…ғзҙ жҲ–ж»Ўи¶іжқЎд»¶зҡ„е…ғзҙ еӨҡдәҺдёҖдёӘпјҢеҲҷжҠӣеҮәејӮеёё
list.single {
it == 5
}
//иҝ”еӣһж»Ўи¶іжқЎд»¶зҡ„е”ҜдёҖе…ғзҙ пјҢеҰӮжһңжІЎжңүж»Ўи¶іжқЎд»¶зҡ„е…ғзҙ жҲ–ж»Ўи¶іжқЎд»¶зҡ„е…ғзҙ еӨҡдәҺдёҖдёӘпјҢеҲҷиҝ”еӣһnull
list.singleOrNull {
it == 5
}жҺ’еәҸ&йҖҶеәҸ
val list = listOf(1, 2, 3, 4, 5, 6)
//иҝ”еӣһдёҖдёӘйў еҖ’е…ғзҙ йЎәеәҸзҡ„ж–°йӣҶеҗҲ
list.reversed()
/**
* иҝ”еӣһдёҖдёӘеҚҮеәҸжҺ’еәҸеҗҺзҡ„ж–°йӣҶеҗҲ
*/
list.sorted()
//е°ҶжҜҸдёӘе…ғзҙ д»Је…ҘlambdaиЎЁиҫҫејҸпјҢж №жҚ®lambdaиЎЁиҫҫејҸиҝ”еӣһеҖјзҡ„еӨ§е°ҸжқҘеҜ№йӣҶеҗҲиҝӣиЎҢжҺ’еәҸ
list.sortedBy {
it*2
}
/**
* еҠҹиғҪе’ҢдёҠйқўдёҖж · -> дёҠйқўжҳҜд»Һе°ҸеҲ°еӨ§жҺ’еҲ—пјҢиҝҷдёӘиҝ”еӣһзҡ„жҳҜд»ҺеӨ§еҲ°е°Ҹ
*/
list.sortedDescending()
list.sortedByDescending {
it*2
}
/**
* ж №жҚ®еӨҡдёӘжқЎд»¶жҺ’еәҸ
* е…Ҳж №жҚ®age еҚҮеәҸжҺ’еҲ—пјҢиӢҘageзӣёеҗҢпјҢж №жҚ®nameеҚҮеәҸжҺ’еҲ—пјҢдҪҶжҳҜйғҪжҳҜй»ҳи®Өзҡ„еҚҮеәҸжҺ’еҲ—
*/
personList.sortWith(compareBy({ it.age }, { it.name }))
/**
* ж №жҚ®еӨҡдёӘжқЎд»¶жҺ’еәҸпјҢиҮӘе®ҡд№үзҡ„规еҲҷ
* жһ„йҖ дёҖдёӘComparatorеҜ№иұЎпјҢе®ҢжҲҗжҺ’еәҸйҖ»иҫ‘пјҡе…ҲжҢүageйҷҚеәҸжҺ’еҲ—пјҢиӢҘageзӣёеҗҢпјҢеҲҷжҢүnameеҚҮеәҸжҺ’еҲ—
*/
val c1: Comparator<Person> = Comparator { o1, o2 ->
if (o2.age == o1.age) {
o1.name.compareTo(o2.name)
} else {
o2.age - o1.age
}
}
personList.sortWith(c1)
//дёҠйқўзҡ„иҮӘе®ҡд№үж–№ејҸеҸҜд»ҘйҖҡиҝҮJavaBeanе®һзҺ°Comparable жҺҘеҸЈе®һзҺ°иҮӘе®ҡд№үзҡ„жҺ’еәҸ
data class Person(var name: String, var age: Int) : Comparable<Person> {
override fun compareTo(other: Person): Int {
if (this.age == other.age) {
return this.name.compareTo(other.name)
} else {
return other.age - this.age
}
}
}
//sorted ж–№жі•иҝ”еӣһжҺ’еәҸеҘҪзҡ„listпјҲе·ІжңүжңүжҺ’еәҸ规еҲҷзҡ„з”Ёsorted,дёҚиҰҒз”ЁsortedbyдәҶпјү
val sorted = personList.sorted()Sequence зҡ„еёёи§Ғж“ҚдҪң
Sequence жҳҜ Kotlin дёӯдёҖдёӘж–°зҡ„жҰӮеҝөпјҢз”ЁжқҘиЎЁзӨәдёҖдёӘ延иҝҹи®Ўз®—зҡ„йӣҶеҗҲгҖӮSequence еҸӘеӯҳеӮЁж“ҚдҪңиҝҮзЁӢпјҢ并дёҚеӨ„зҗҶд»»дҪ•е…ғзҙ пјҢзӣҙеҲ°йҒҮеҲ°з»Ҳз«Ҝж“ҚдҪңз¬ҰжүҚејҖе§ӢеӨ„зҗҶе…ғзҙ пјҢжҲ‘们д№ҹеҸҜд»ҘйҖҡиҝҮ asSequence жү©еұ•еҮҪж•°пјҢе°ҶзҺ°жңүзҡ„йӣҶеҗҲиҪ¬жҚўдёә Sequence пјҢд»Јз ҒеҰӮдёӢжүҖзӨә
val list = mutableListOf<Person>()
for (i in 1..10000) {
list.add(Person("name$i", (0..100).random()))
}
list.asSequence()еҪ“жҲ‘们жӢҝеҲ°з»“жһңд№ӢеҗҺжҲ‘们иҝҳиғҪйҖҡиҝҮtoListеҶҚиҪ¬жҚўдёәйӣҶеҗҲгҖӮ
list.asSequence().toList()
Sequenceзҡ„ж“ҚдҪңз¬Ұз»қеӨ§йғЁеҲҶйғҪжҳҜе’Ң Collection зұ»дјјзҡ„гҖӮеёёз”Ёзҡ„дёҖдәӣж“ҚдҪңз¬ҰжҳҜеҸҜд»ҘзӣҙжҺҘе№іжӣҝдҪҝз”Ёзҡ„гҖӮ
val list2 = list.asSequence()
.filter {
it.age > 50
}.map {
it.name
}.take(3).toList()еұ…然他们зҡ„ж“ҚдҪңз¬ҰйғҪй•ҝзҡ„дёҖж ·пјҢж•Ҳжһңд№ҹйғҪдёҖж ·пјҢеҜјиҮҙ Sequence дёҺ Collection е°ұеҫҲзұ»дјјпјҢйӮЈд№Ҳж—ўз”ҹз‘ңдҪ•з”ҹдә®пјҒдёәд»Җд№ҲйңҖиҰҒиҝҷд№ҲдёӘдёңиҘҝпјҹ既然 Collection иғҪе®һзҺ°ж•Ҳжһңдёәд»Җд№ҲиҝҳйңҖиҰҒ Sequence е‘ўпјҹ他们зҡ„еҢәеҲ«еҸҲжҳҜд»Җд№Ҳе‘ўпјҹ
еҢәеҲ«дёҺеҜ№жҜ”
Collection жҳҜз«ӢеҚіжү§иЎҢзҡ„пјҢжҜҸдёҖж¬Ўдёӯй—ҙж“ҚдҪңйғҪдјҡз«ӢеҚіжү§иЎҢпјҢ并且жҠҠжү§иЎҢзҡ„з»“жһңеӯҳеӮЁеҲ°дёҖдёӘе®№еҷЁдёӯпјҢжІЎеӨҡдёҖдёӘдёӯй—ҙж“ҚдҪңз¬Ұе°ұеӨҡдёҖдёӘе®№еҷЁеӯҳеӮЁз»“жһңгҖӮ
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> {
return filterTo(ArrayList<T>(), predicate)
}жҜ”еҰӮеёёз”Ёзҡ„ map е’Ң filter йғҪжҳҜдјҡж–°е»әдёҖдёӘ ArrayList еҺ»еӯҳеӮЁз»“жһңпјҢ
Sequence жҳҜ延иҝҹжү§иЎҢзҡ„пјҢе®ғжңүдёӨз§Қзұ»еһӢпјҢдёӯй—ҙж“ҚдҪңе’Ңжң«з«Ҝж“ҚдҪң пјҢдё»иҰҒзҡ„еҢәеҲ«жҳҜдёӯй—ҙж“ҚдҪңдёҚдјҡз«ӢеҚіжү§иЎҢпјҢе®ғ们еҸӘжҳҜиў«еӯҳеӮЁиө·жқҘпјҢдёӯй—ҙж“ҚдҪңз¬Ұдјҡиҝ”еӣһеҸҰдёҖдёӘSequenceпјҢд»…еҪ“жң«з«Ҝж“ҚдҪңиў«и°ғз”Ёж—¶пјҢжүҚдјҡжҢүз…§йЎәеәҸеңЁжҜҸдёӘе…ғзҙ дёҠжү§иЎҢдёӯй—ҙж“ҚдҪңпјҢ然еҗҺжү§иЎҢжң«з«Ҝж“ҚдҪңгҖӮ
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {
return TransformingSequence(this, transform)
}
public fun <T> Sequence<T>.filter(predicate: (T) -> Boolean): Sequence<T> {
return FilteringSequence(this, true, predicate)
}жҜ”еҰӮеёёз”Ёзҡ„ map е’Ң filter йғҪжҳҜзӣҙжҺҘиҝ”еӣһ Sequence зҡ„this еҜ№иұЎгҖӮ
public inline fun <T> Sequence<T>.first(predicate: (T) -> Boolean): T {
for (element in this) if (predicate(element)) return element
throw NoSuchElementException("Sequence contains no element matching the predicate.")
}然еҗҺеңЁжң«з«Ҝж“ҚдҪңдёӯпјҢдјҡеҜ№ Sequence дёӯзҡ„е…ғзҙ иҝӣиЎҢйҒҚеҺҶпјҢзӣҙеҲ°йў„зҪ®жқЎд»¶еҢ№й…ҚдёәжӯўгҖӮ
иҝҷйҮҢжҲ‘们дёҫдёҖдёӘзӨәдҫӢжқҘжј”зӨәдёҖдёӢпјҡ
жҲ‘们дҪҝз”ЁеҗҢж ·зҡ„зӯӣйҖүдёҺиҪ¬жҚўпјҢжқҘзңӢзңӢж•Ҳжһң
val list = mutableListOf<Person>()
for (i in 1..10000) {
list.add(Person("name$i", (0..100).random()))
}
val time = measureTimeMillis {
val list1 = list.filter {
it.age > 50
}.map {
it.name
}.take(3)
YYLogUtils.w("list1$list1")
}
YYLogUtils.w("иҖ—иҙ№зҡ„ж—¶й—ҙ$time")
val time2 = measureTimeMillis {
val list2 = list.asSequence()
.filter {
it.age > 50
}.map {
it.name
}.take(3).toList()
YYLogUtils.w("list2$list2")
}
YYLogUtils.w("иҖ—иҙ№зҡ„ж—¶й—ҙ2$time2")иҝҗиЎҢз»“жһңпјҡ
еҪ“йӣҶеҗҲж•°йҮҸдёә10000зҡ„ж—¶еҖҷпјҢжү§иЎҢж—¶й—ҙиғҪдјҳз§ҖзҷҫеҲҶд№Ӣ50е·ҰеҸіпјҡ
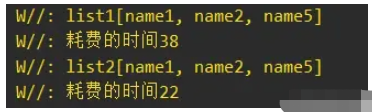
еҪ“йӣҶеҗҲж•°йҮҸдёә5000зҡ„ж—¶еҖҷпјҢжү§иЎҢж—¶й—ҙзӣёе·®жҜ”иҫғжҺҘиҝ‘пјҡ
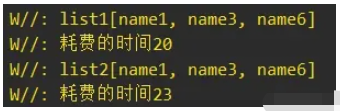
еҪ“йӣҶеҗҲж•°йҮҸдёә3000зҡ„ж—¶еҖҷпјҢжӯӨж—¶зҡ„з»“жһңе°ұеҸҚиҝҮжқҘдәҶпјҢSequence延时жү§иЎҢзҡ„дјҳеҢ–ж•Ҳжһңе°ұдёҚеҰӮListиҪ¬жҚўSequenceеҶҚиҪ¬жҚўListдәҶпјҡ
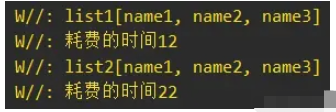
иҜ»еҲ°иҝҷйҮҢпјҢиҝҷзҜҮвҖңKotlinзҡ„CollectionдёҺSequenceж“ҚдҪңејӮеҗҢзӮ№жҳҜд»Җд№ҲвҖқж–Үз« е·Із»Ҹд»Ӣз»Қе®ҢжҜ•пјҢжғіиҰҒжҺҢжҸЎиҝҷзҜҮж–Үз« зҡ„зҹҘиҜҶзӮ№иҝҳйңҖиҰҒеӨ§е®¶иҮӘе·ұеҠЁжүӢе®һи·өдҪҝз”ЁиҝҮжүҚиғҪйўҶдјҡпјҢеҰӮжһңжғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





