Nagios监控系统
nagios监控系统
前言:Nagios是一款开源的免费网络监视工具,可以监控Windows、Linux和Unix的主机状态,交换机路由器等网络设备,在系统或服务状态异常时发出邮件或短信报警,第一时间通知网站运维人员。流量监控不是他的强项,流量监控建议使用cacti(可以绘制非常直观的图形。
总结一下nagios主要可以监控以下方面:
l 主机是否宕机(通过ping命令,如果ping不通会认为主机属于宕机状态,但不影响所监控的其他服务)
l 服务器资源(cpu使用率、硬盘剩余空间等)
l 网络服务(smtp\pop3\http\)
l 监控网络设备(路由器、交换机等)
一、需要了解的知识点
1、nagios工作原理
Nagios本身不包括监控主机和服务的功能。所有的监控、监测功能都是通过各种插件来完成的。安装完nagios之后,在nagios主目录下的/libexex里面放有nagios自带的插件,如:check_disk是检查磁盘空间的插件,check_load是检查cpu负载的插件,每一个插件可以通过运行./check_xxx -h命令来检查其使用方法和功能。
2、nagios的四种监控状态
Nagios可以识别四种状态返回信息。0(OK)表示状态正常(绿色显示),1(WARNING)表示出现警告(×××),2(CRITICAL)表示出现非常严重错误(红色),3(UNKNOWN)表示未知错误(深×××),nagios根据插件返回来的值来判断监控对象的状态,并通过web显示出来,以供管理员即时发现故障。
3、nagios通过nrpe插件来远程管理服务的工作过程
1) Nagios执行安装在它里面的check_nrpe插件,并告诉check_nrpe去检测哪些服务。
2) 通过ssl,check_nrpe连接远端机器上的NRPE daemon。
3) NRPE运行本地的各种插件去检测本地服务器和状态(check_disk,...etc)。
4) NRPE把检测的结果传给主机端的check_nrpe,check_nrpe再把结果送到nagios状态队列中。
5) Nagios依次读取队列中的信息,再把结果显示出来。
二、实验环境
1、实验拓扑
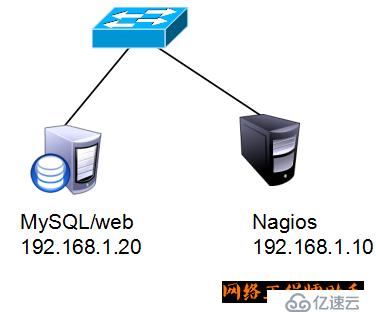
2、虚拟机上的实验环境

三、实验步骤
1、搭建nagios监控系统
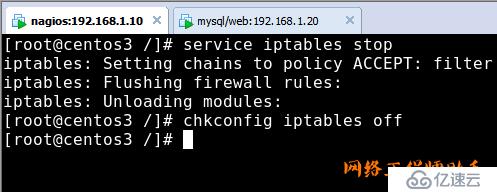
1)关闭防火墙
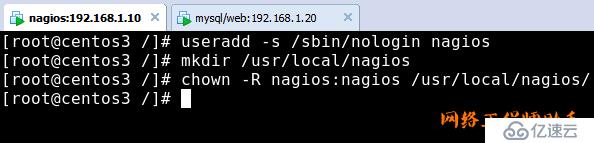
2)创建nagios用户和用户组
3)编译安装nagios(需要提前配置yum)
安装支持包:

配置:

编译和安装:

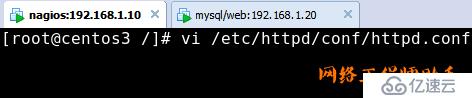
注意:安装install-webconf是为了生成配置文件,后面在/etc/httpd/conf/httpd.conf最后添加的信息就不用手工打了,可以到/etc/httpd/conf.d/nagios.conf文件中复制。
以上命令的解释:
make install //安装主程序,CGI和HTML文件
make install-init //在/etc/rc.d/init.d安装启动脚本
make install-commandmode //配置目录权限
make install-config //安装示例配置文件
make install-webconf //安装nagios的web接口,会在/etc/httpd/conf.d目录中创建nagios.conf文件。
安装完成之后会在/usr/local/nagios目录下产生6个目录,下面分别解释一下。
bin:nagios执行程序所在的目录,nagios文件即为主程序。
etc:nagios配置文件目录,当make install-config完以后etc下面就会出现默认的配置文件。
sbin:nagios CGI文件所在目录,这里存放的是一些外部命令执行程序。
share:nagios网页文件目录,存放一些html文件。
var:nagios日志文件、pid等文件目录。
Libexec:系统默认插件的存储位置
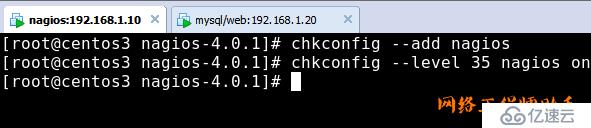
4)添加为系统服务器
5)安装nagios插件(监控功能通过插件完成)

编译并安装:

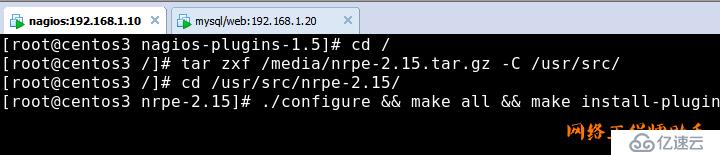
6)安装nrpe(为了监控远程服务器)
7)在/etc/httpd/conf/httpd.conf文件最后添加授权,我们可以到/etc/httpd/conf.d/nagios.conf文件中复制,不用手打。
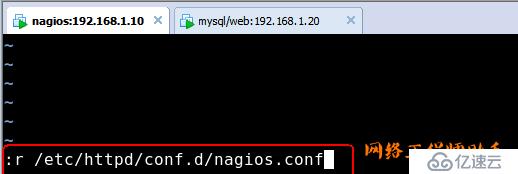
使用:r导入即可(定位到文档的最后)
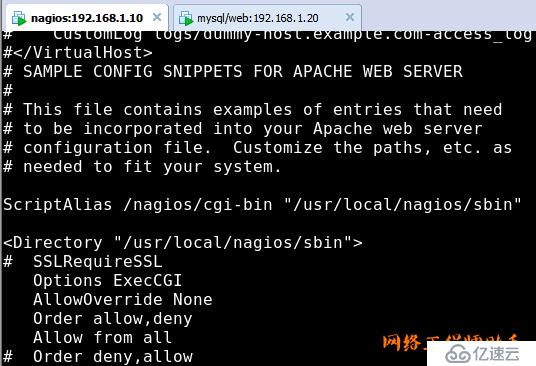
导入即可,不用修改,保存退出。
8)执行htpasswd命令添加一个访问nagios页面的授权用户

用户名和密码都是nagiosadmin
9)启动nagios和httpd

10)在浏览器上访问nagios页面
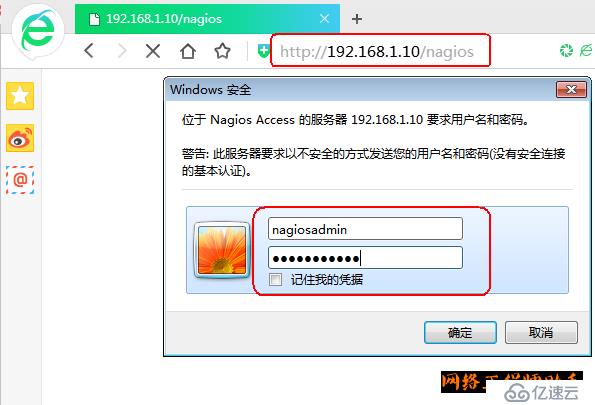

目前只能是打开网页,很多的监控选项不能看到,如果需要监控远程的服务器,还需要做很多配置,下面开始配置。
2、配置nagios监控系统涉及知识点
1)nagios的配置文件:
Nagios.cfg:主配置文件,定义各种配置文件的名称和位置
Cgi.cfg:控制CGI的配置文件
Resource.cfg:资源文件,定义各种变量,以便于其他文件调用
Objects:其他配置文件存放目录,此目录下主要有:
Command.cfg:命令配置文件,定义各种命令格式,以备其他文件调用
contacts.cfg:联系人和组,发邮件等告警信息时可以调用
localhost.cfg:监控本机的配置文件
timeperiods.cfg:定义监控时间的配置文件,便于其他文件调用
Hostgroups.cfg:定义监控的主机(组),需手动创建。
2)配置文件之间的关系
在nagios的配置过程中涉及的几个定义有主机、主机组、服务、服务组、联系人、联系人组、监控时间和监控命令等。从这些定义可以看出,nagios各个配置文件之间互为关联、彼此引用的。成功配置出一台nagios监控系统,必须要弄清楚每个配置文件之间依赖与被依赖的关系,最重要的有四点
n 定义监控那些主机,主机组,服务和服务组
n 定义这个监控要用什么命令实现
n 定义监控的时间段
n 定义主机或服务器出现问题时要通知的联系人和联系人祖
3)配置nagios
为了能更清楚的说明问题,同时也为了维护方便,建议将nagios各个定义的对象创建独立的配置文件。
n 创建conf目录来定义host主机
n 创建hostgroups.cfg文件来定义主机组
n 用默认的contacts.cfg文件来定义联系人和联系人组
n 用默认的commands.cfg文件来定义命令
n 用默认的timeperiods.cfg来定义监控时间段
n 用默认的templetes.cfg文件作为资源引用文件
3、配置nagios
1)修改/usr/local/nagios/etc/nagios.cgf主配置文件
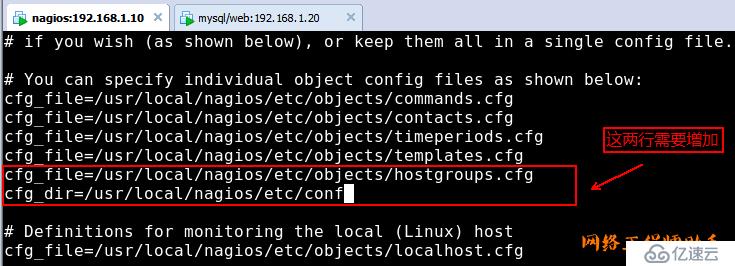

2)修改/usr/local/nagios/etc/objects/commands.cfg

添加如下内容(定义check_nrpe监控命令)
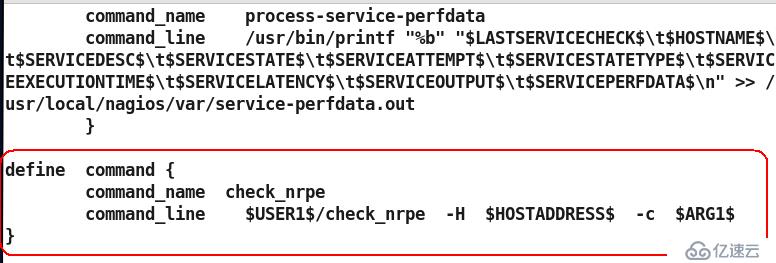
3)修改/usr/local/nagios/etc/objects/contacts.cfg(定义监控服务器联系人)

4)新建/usr/local/nagios/etc/objects/hostgroups.cfg(定义主机组)
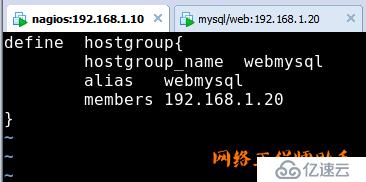
5)在/usr/local/nagios/etc/conf下面新建192.168.1.20.cfg文件(用于监控192.168.1.20的主机存活,负载,进程)(所有内容需要手工输入)
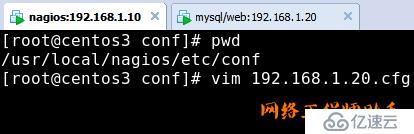
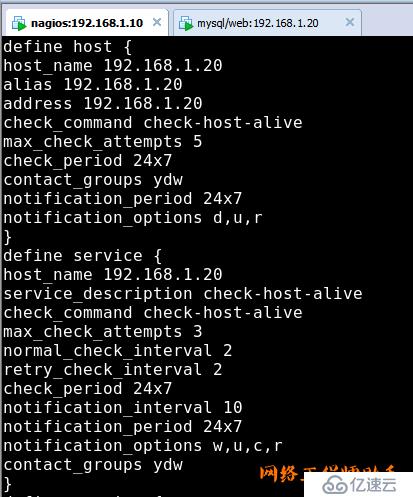
未完接下图:
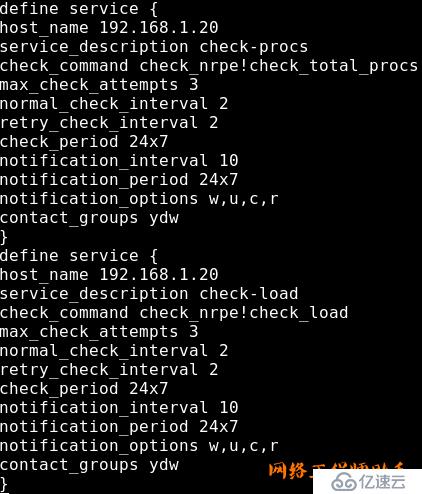
命令解释:
define host{
use linux-server //定义使用的模板
host_name nagios //被监控主机的名称,最好别带空格
alias nagios //别名
address 127.0.0.1 //被监控主机的IP地址
check_command check-host-alive
normal_check_interval 3 //正常检测间隔时间
retry_check_interval 2 //重试检测间隔时间
//监控的命令check-host-alive,这个命令来自commands.cfg,用来监控主机是否存活
max_check_attempts 5 //检查失败后重试的次数
check_period 24x7 //检查的时间段24x7,同样来自timeperiods.cfg中定义
notification_interval 10 //提醒的间隔,每隔10秒提醒一次
notification_period 24x7 //提醒的周期, 24x7,同样来自timeperiods.cfg中定义
contact_groups admins //联系人组,上面在contactgroups.cfg中定义的admins
notification_options d,u,r //指定什么情况下提醒
}
当服务出现w-报警(warning),u-未知(unkown),c-严重(critical),或者r-从异常情况恢复正常,在这四种情况下通知联系人
当主机出现d-当机(down),u-返回不可达(unreachable),r-从异常情况恢复正常,在这3种情况下通知联系人
6)重启nagios服务
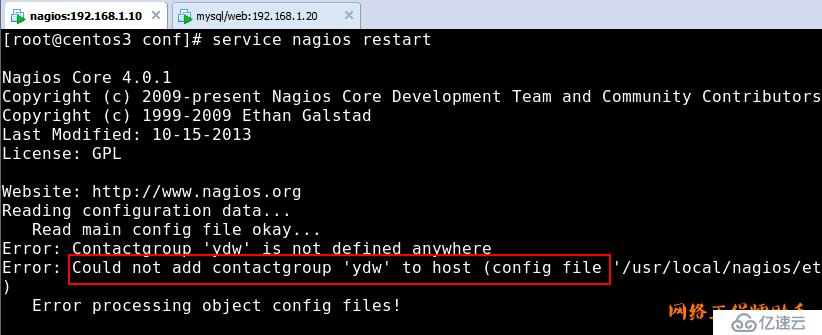
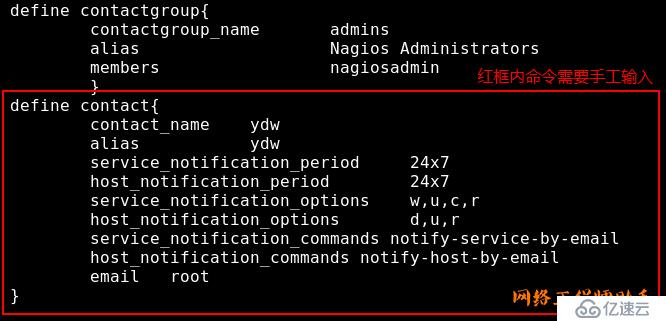
7)发现错误,提示没有添加联系人组,解决方法:在
/usr/local/nagios/etc/objects/contacts.cfg文件的最后添加代码,如下图:

8)重启nagios服务器成功
9)访问网页查看状态
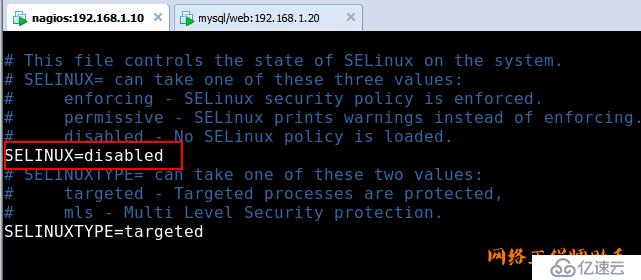
(注意:关闭selinux或者开例外)
或者:
如果你开启了selinux 需要配置如下二步:
chcon -R -t httpd_sys_content_t /usr/local/nagios/sbin/
chcon -R -t httpd_sys_content_t /usr/local/nagios/share/
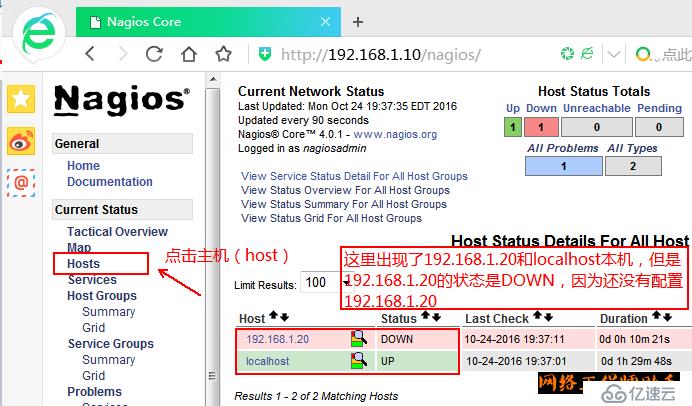
点击上图中的localhost,可以查看本机的状态
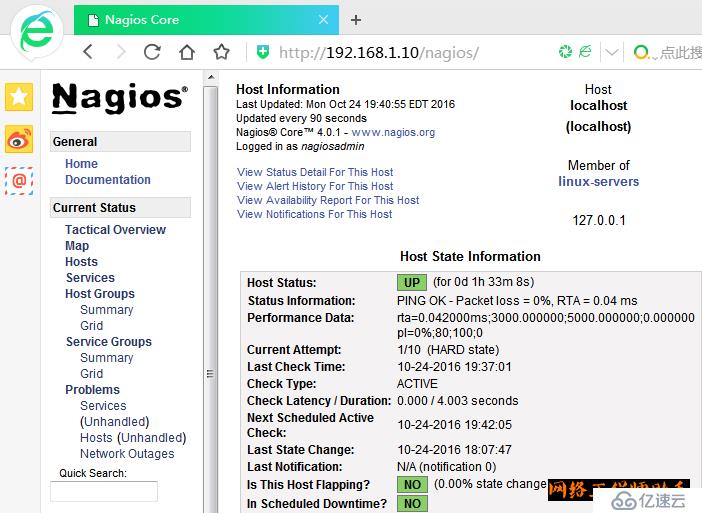
4、配置被控端192.168.1.20(mysql和web)
1)安装nagios插件
yum -y install openssl openssl-devel
useradd nagios -s /sbin/nologin
tar zxf nagios-plugins-1.5.tar.gz
cd nagios-plugins-1.5
./configure --prefix=/usr/local/nagios
make && make install
chown -R nagios:nagios /usr/local/nagios
tar zxf nrpe-2.15.tar.gz
cd nrpe-2.15
./configure --prefix=/usr/local/nagios
make all && make install-plugin && make install-daemon
make install-daemon-config
2)安装完成之后,需要打开vim /usr/local/nagios/etc/nrpe.cfg
添加nagios服务器的地址
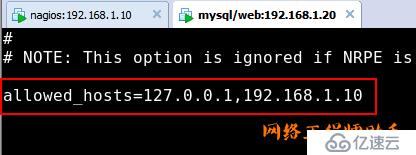
3)启动nrpe

4)在nagios服务器上测试nrpe运行是否正常,出现下面的信息说明正确。

5)在浏览器上访问
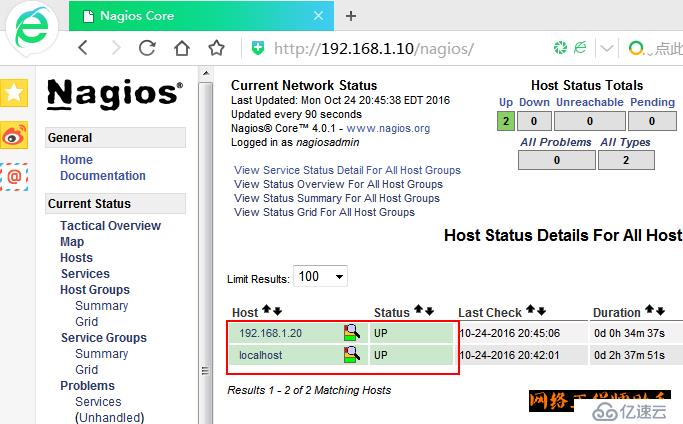
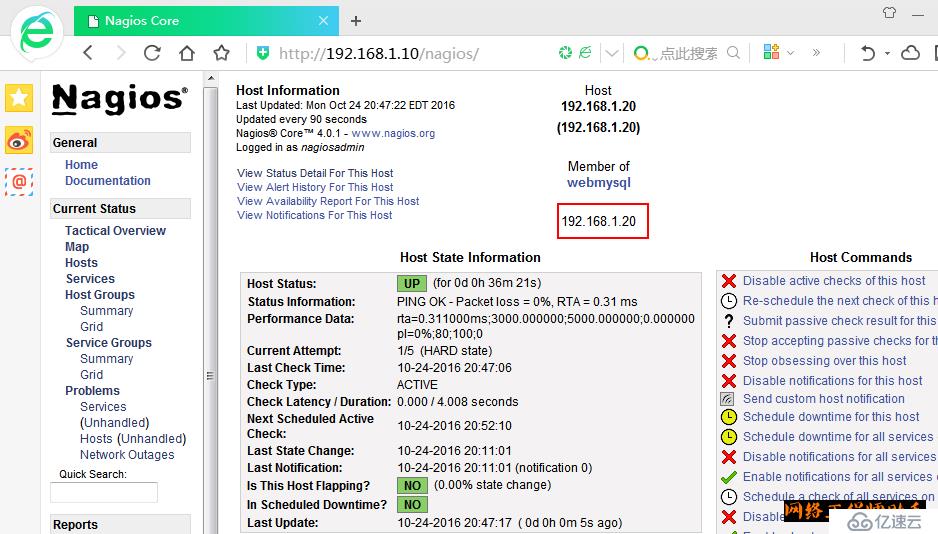
5、补充
也可在services.cfg文件中添加192.168.1.20.cgf文件中的参数
#vi /usr/local/nagios/etc/objects/services.cfg
内容如下:


check_local_users!20!50 //监测远程主机当前的登录用户数量,如果大于20用户则报warning,如果大于50则报critical
check_local_disk!20%!10%!/ //如果可用空间低于20%会报Warning,如果可用空间低于10%则报Critical:
check_local_procs!250!400!RSZDT //监测远程主机当前的进程总数,如果大于250进程则报warning,如果大于400进程则报critical,S(休眠)、R(运行)、Z(僵死)、D (不可中断)、T (停止)
check_load -w 5,4,3 -c 10,6,4这个命令的意义如下
当1分钟多于5个进程等待,5分钟多于4个,15分钟多于3个则为warning状态
当1分钟多于10个进程等待,5分钟多于6个,15分钟多于4个则为critical状态
服务组并不是必须的,这是配合nagios的监控页面的显示
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





