这篇文章给大家分享的是有关使用Jsoup如何实现爬虫技术的内容。小编觉得挺实用的,因此分享给大家做个参考。一起跟随小编过来看看吧。
1.Jsoup简述
Java中支持的爬虫框架有很多,比如WebMagic、Spider、Jsoup等。今天我们使用Jsoup来实现一个简单的爬虫程序。
Jsoup拥有十分方便的api来处理html文档,比如参考了DOM对象的文档遍历方法,参考了CSS选择器的用法等等,因此我们可以使用Jsoup快速地掌握爬取页面数据的技巧。
2.快速开始
1)编写HTML页面

页面中表格的商品信息是我们要爬取的数据。其中属性pname类的商品名称,以及属于pimg类的商品图片。
2)使用HttpClient读取HTML页面
HttpClient是一个处理Http协议数据的工具,使用它可以将HTML页面作为输入流读进java程序中。可以从http://hc.apache.org/下载HttpClient的jar包。

3)使用Jsoup解析html字符串
通过引入Jsoup工具,直接调用parse方法来解析一个描述html页面内容的字符串来获得一个Document对象。该Document对象以操作DOM树的方式来获得html页面上指定的内容。相关API可以参考Jsoup官方文档:https://jsoup.org/cookbook/
下面我们使用Jsoup来获取上述html中指定的商品名称和价格的信息。

至此,我们已经实现使用HttpClient+Jsoup爬取HTML页面数据的功能。接下来,我们让效果更直观一些,比如将爬取的数据存到数据库中,将图片存到服务器上。
3.保存爬取的页面数据
1)保存普通数据到数据库中
将爬取的数据封装进实体Bean中,并存到数据库内。

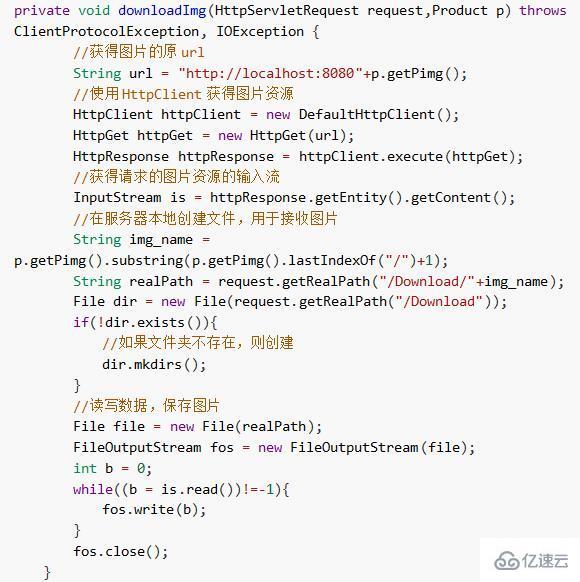
2)保存图片到服务器上
直接通过下载图片的方式将图片保存到服务器本地。
感谢各位的阅读!关于使用Jsoup如何实现爬虫技术就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





