小编给大家分享一下Tensorflow如何实现XOR运算的方式,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
对于“XOR”大家应该都不陌生,我们在各种课程中都会遇到,它是一个数学逻辑运算符号,在计算机中表示为“XOR”,在数学中表示为“ ”,学名为“异或”,其来源细节就不详细表明了,说白了就是两个a、b两个值做异或运算,若a=b则结果为0,反之为1,即“相同为0,不同为1”.
”,学名为“异或”,其来源细节就不详细表明了,说白了就是两个a、b两个值做异或运算,若a=b则结果为0,反之为1,即“相同为0,不同为1”.
在计算机早期发展中,逻辑运算广泛应用于电子管中,这一点如果大家学习过微机原理应该会比较熟悉,那么在神经网络中如何实现它呢,早先我们使用的是感知机,可理解为单层神经网络,只有输入层和输出层(在吴恩达老师的系列教程中曾提到过这一点,关于神经网络的层数,至今仍有异议,就是说神经网络的层数到底包不包括输入层,现今多数认定是不包括的,我们常说的N层神经网络指的是隐藏层+输出层),但是感知机是无法实现XOR运算的,简单来说就是XOR是线性不可分的,由于感知机是有输入输出层,无法线性划分XOR区域,于是后来就有了使用多层神经网络来解决这一问题的想法~~
关于多层神经网络实现XOR运算可大致这么理解:
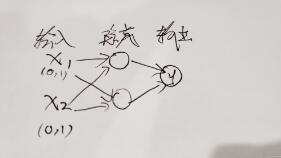
两个输入均有两个取值0和1,那么组合起来就有四种可能,即[0,0]、[0,1]、[1,0]、[1,1],这样就可以通过中间的隐藏层进行异或运算了~
咱们直接步入正题吧,对于此次试验我们只需要一个隐藏层即可,关于神经网络 的基础知识建议大家去看一下吴恩达大佬的课程,真的很棒,百看不厌,真正的大佬是在认定学生是绝对小白的前提下去讲解的,所以一般人都能听懂~~接下来的图纯手工操作,可能不是那么准确,但中心思想是没有问题的,我们开始吧:
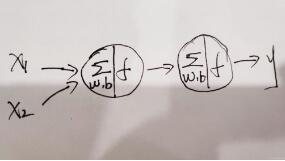
上图是最基本的神经网络示意图,有两个输入x1、x2,一个隐藏层,只有一个神经元,然后有个输出层,这就是最典型的“输入层+隐藏层+输出层”的架构,对于本题目,我们的输入和输出以及整体架构如下图所示:
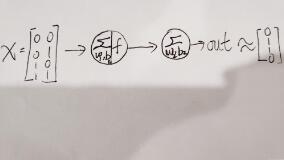
输入量为一个矩阵,0和0异或结果为0,0和1异或结果为1,依次类推,对应我们的目标值为[0,1,1,0],最后之所以用约等号是因为我们的预测值与目标值之间会有一定的偏差,如果训练的好那么这二者之间是无限接近的。
我们直接上全部代码吧,就不分步进行了,以为这个实验本身难度较低,且代码注释很清楚,每一步都很明确,如果大家有什么不理解的可以留言给我,看到必回:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import numpy as np
import tensorflow as tf
#定义输入值与目标值
X=np.array([[0,0],[0,1],[1,0],[1,1]])
Y=np.array([[0],[1],[1],[0]])
#定义占位符,从输入或目标中按行取数据
x=tf.placeholder(tf.float32,[None,2])
y=tf.placeholder(tf.float32,[None,1])
#初始化权重,使其满足正态分布,w1和w2分别为输入层到隐藏层和隐藏层到输出层的权重矩阵
w1=tf.Variable(tf.random_normal([2,2]))
w2=tf.Variable(tf.random_normal([2,1]))
#定义b1和b2,分别为隐藏层和输出层的偏移量
b1=tf.Variable([0.1,0.1])
b2=tf.Variable([0.1])
#使用Relu激活函数得到隐藏层的输出值
a=tf.nn.relu(tf.matmul(x,w1)+b1)
#输出层不用激活函数,直接获得其值
out=tf.matmul(a,w2)+b2
#定义损失函数MSE
loss=tf.reduce_mean(tf.square(out-y))
#优化器选择Adam
train=tf.train.AdamOptimizer(0.01).minimize(loss)
#开始训练,迭代1001次(方便后边的整数步数显示)
with tf.Session() as session:
session.run(tf.global_variables_initializer()) #初始化变量
for i in range(1001):
session.run(train,feed_dict={x:X,y:Y}) #训练模型
loss_final=session.run(loss,feed_dict={x:X,y:Y}) #获取损失
if i%100==0:
print("step:%d loss:%2f" % (i,loss_final))
print("X: %r" % X)
print("pred_out: %r" % session.run(out,feed_dict={x:X}))对照第三张图片理解代码更加直观,我们的隐藏层神经元功能就是将输入值和相应权重做矩阵乘法,然后加上偏移量,最后使用激活函数进行非线性转换;而输出层没有用到激活函数,因为本次我们不是进行分类或者其他操作,一般情况下隐藏层使用激活函数Relu,输出层若是分类则用sigmode,当然你也可以不用,本次实验只是单纯地做异或运算,那输出层就不劳驾激活函数了~
对于标准神经元内部的操作可理解为下图:
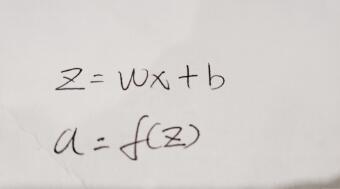
这里的x和w一般写成矩阵形式,因为大多数都是多个输入,而矩阵的乘积要满足一定的条件,这一点属于线代中最基础的部分,大家可以稍微了解一下,这里对设定权重的形状还是很重要的;
看下效果吧:
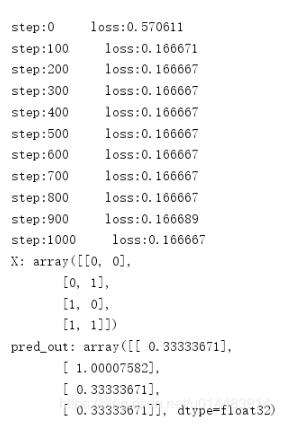
这是我们在学习率为0.1,迭代1001次的条件下得到的结果
然后我们学习率不变,迭代2001次,看效果:
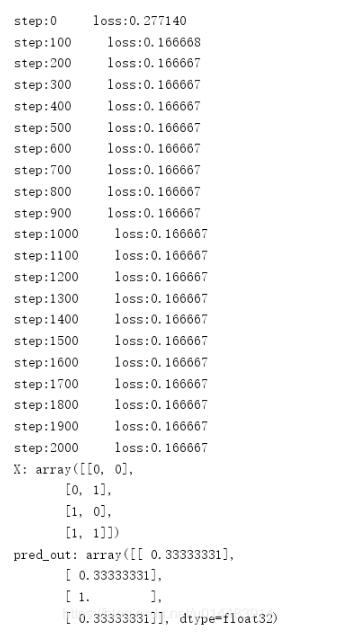
没有改进,这就说明不是迭代次数的问题,我们还是保持2001的迭代数,将学习率改为0.01,看效果:

以上是“Tensorflow如何实现XOR运算的方式”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





