selenium如何 在python中使用?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
python的五大特点:1.简单易学,开发程序时,专注的是解决问题,而不是搞明白语言本身。2.面向对象,与其他主要的语言如C++和Java相比, Python以一种非常强大又简单的方式实现面向对象编程。3.可移植性,Python程序无需修改就可以在各种平台上运行。4.解释性,Python语言写的程序不需要编译成二进制代码,可以直接从源代码运行程序。5.开源,Python是 FLOSS(自由/开放源码软件)之一。
1.案例分析:
- 需求:爬取网易新闻的国内、国际、军事、无人机板块下的新闻数据
- 需求分析:当点击国内超链进入国内对应的页面时,会发现当前页面展示的新闻数据是被动态加载出来的,如果直接通过程序对url进行请求,是获取不到动态加载出的新闻数据的。则需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的新闻数据。
2.selenium在scrapy中使用的原理分析:
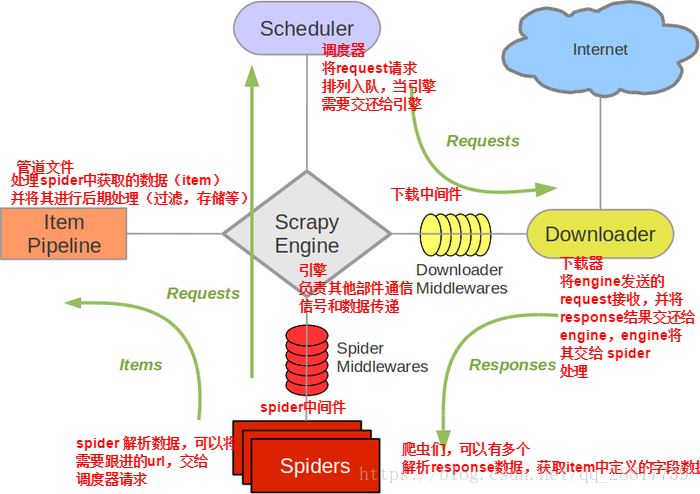
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response再转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3.selenium在scrapy中的使用流程:
重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
在配置文件中开启下载中间件
4.实例:
# 1.spider文件
import scrapy
from wangyiPro.items import WangyiproItem
from selenium import webdriver
class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['www.xxx.con']
start_urls = ['https://news.163.com/']
# 浏览器实例化的操作只会被执行一次
bro = webdriver.Chrome(executable_path='chromedriver.exe')
urls = []# 最终存放的就是5个板块对应的url
def parse(self, response):
li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
for index in [3,4,6,7,8]:
li = li_list[index]
new_url = li.xpath('./a/@herf').extract_first()
self.urls.append(new_url)
# 对5大板块对应的url进行请求发送
yield scrapy.Request(url=new_url,callback=self.parse_news)
# 用来解析每一个板块对应的新闻数据【只能解析到新闻的标题】
def parse_news(self,response):
div_list = response.xpath('//div[@class="ndi_main"]/div')
for div in div_list:
title = div.xpath('./div/div[1]/h4/a/text()').extract_first()
news_detail_url = div.xpath('./div/div[1]/h4/a/@href').extract_first()
# 实例化item对象,将解析到的标题和内容存储到item对象中
item = WangyiproItem()
item['title'] = title
# 对详情页的url进行手动请求发送获得新闻内容
yield scrapy.Request(url=news_detail_url,callback=self.parse_detail,meta={'item':item})
def parse_detail(self,response):
item = response.meta['item']
# 通过response解析出新闻内容
content = response.xpath('//div[@id="endText"]//text()').extract()
content = ''.join(content)
item['content'] = content
yield item
def close(self,spider):
# 当爬虫结束之后,调用关闭浏览器方法
print('爬虫整体结束~~~~~~~~~~~~~~~~~~~')
self.bro.quit()
----------------------------------------------------------------------------------------
# 2.items文件
import scrapy
class WangyiproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
----------------------------------------------------------------------------------------
# 3.middlewares文件
from scrapy import signals
from scrapy.http import HtmlResponse
from time import sleep
class WangyiproDownloaderMiddleware(object):
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
# 判断哪些响应对象是5个板块的,如果在就对响应对象进行处理
if response.url in spider.urls:
# 获取在爬虫类中定义好的浏览器
bro = spider.bro
bro.get(response.url)
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(1)
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(1)
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(1)
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(1)
# 获取携带了新闻数据的页面源码数据
page_text = bro.page_source
# 实例化一个新的响应对象
new_response = HtmlResponse(url=response.url,body=page_text,encoding='utf-8',request=request)
return new_response
else:
return response
def process_exception(self, request, exception, spider):
pass
----------------------------------------------------------------------------------------
# 4.pipelines文件
class WangyiproPipeline(object):
def process_item(self, item, spider):
print(item)
return item
----------------------------------------------------------------------------------------
# 5.setting文件
BOT_NAME = 'wangyiPro'
SPIDER_MODULES = ['wangyiPro.spiders']
NEWSPIDER_MODULE = 'wangyiPro.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'wangyiPro.pipelines.WangyiproPipeline': 300,
}
LOG_LEVEL = 'ERROR'关于selenium如何 在python中使用问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





