基于binlog的离线分析平台的一些初步实践
参考文档:
http://quarterback.cn/%e9%80%9a%e8%bf%87kafka-nifi%e5%bf%ab%e9%80%9f%e6%9e%84%e5%bb%ba%e5%bc%82%e6%ad%a5%e6%8c%81%e4%b9%85%e5%8c%96mongodb%e6%9e%b6%e6%9e%84/
http://seanlook.com/2018/01/13/maxwell-binlog/
https://yq.aliyun.com/articles/338423
直接上图
方案1:
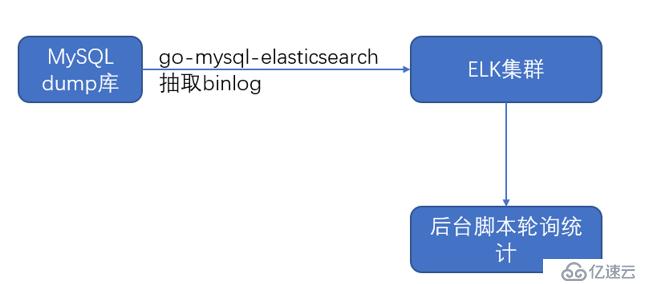
方案2:

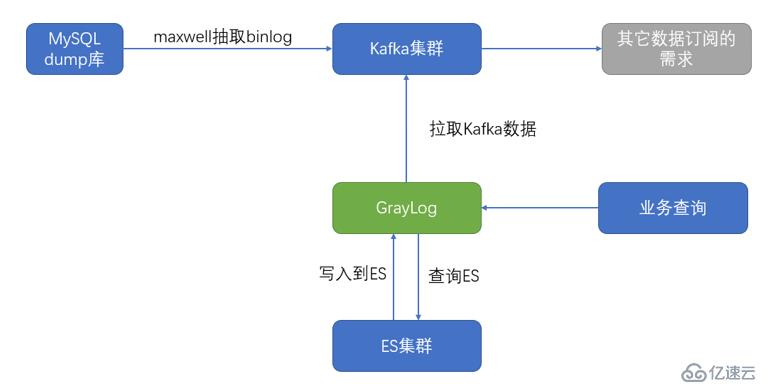
方案3
方案1的比较简单,基本上也是满足使用,也是不错的选择。但是功能上比较单一。
方案2比较复杂,引入了更多的组件,将数据存到MongoDB里面。这种引入了kafka的比较适合有多个异构数据库或者DW数仓抽数的场景。
方案3也比较复杂,和方案2类似,区别就是将数据存到ES里面,并且graylog自带了一个web查询的界面。
这里我们实验采用的是方案2,先把binlog采集到kafka,然后就可以任意自由消费binlog,更加灵活些。
实验涉及到的软件:
OS 版本:CentOS7.5
maxwell 版本:1.22.4
nifi 版本:1.9.2
kafka-eagle 版本:1.3.9
maxwell部署节点: 192.168.20.10
zk+kafka部署节点: 192.168.2.4
kafka-eagle部署的节点: 192.168.2.4
nifi部署的节点: 192.168.2.4
模拟的业务MySQL数据库:192.168.2.4:3306
kafka 和 zk的部署,不是这里的重点。我这里的zk和kafka都是部署在 192.168.2.4上面的,这里的具体操作我直接跳过。
我实验中, zk和kafka都是单机部署的,生产环境下一定要使用集群模式。
1、最好将主机名和ip关系,写到各主机的 /etc/hosts 中,不然可能遇到解析失败的情况
2、需要注意的是,我这里的zk是高版本的,默认会监听 8080端口,建议改成其他的,把8080端口留给其它服务使用。
[root@Test-dba01 /usr/local/zookeeper-3.5.5-bin ] # cat conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=./data/
clientPort=2181
admin.serverPort=12345
启动后,可以看到监听的端口起来了
[root@Test-dba01 /usr/local/kafka ] # ss -lnt| egrep 2181
LISTEN 0 50 :::2181 :::*
[root@Test-dba01 /usr/local/kafka ] # ss -lnt| egrep 12345
LISTEN 0 50 :::12345 :::*
kafka-eagle 是国内的一个大佬开发出来的, 我这里用到它主要是喜欢它附带的ksql功能,支持直接查询kafka的topic里面的数据。
此外,这个工具还有很多好用的功能,这里我就不介绍了。
贴下我的配置
cd /root/kafka-eagle-bin-1.3.9/kafka-eagle-web-1.3.9
egrep -v '^$|^#' /root/kafka-eagle-bin-1.3.9/kafka-eagle-web-1.3.9/conf/system-config.properties
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=192.168.2.4:2181
kafka.zk.limit.size=25
kafka.eagle.webui.port=8048
cluster1.kafka.eagle.offset.storage=kafka
cluster2.kafka.eagle.offset.storage=zk
kafka.eagle.metrics.charts=false
kafka.eagle.sql.fix.error=false
kafka.eagle.sql.topic.records.max=5000
kafka.eagle.mail.enable=false
kafka.eagle.mail.sa=alert_sa@163.com
kafka.eagle.mail.username=alert_sa@163.com
kafka.eagle.mail.password=mqslimczkdqabbbh322222
kafka.eagle.mail.server.host=smtp.163.com
kafka.eagle.mail.server.port=25
kafka.eagle.topic.token=keadmin
cluster1.kafka.eagle.sasl.enable=false
cluster1.kafka.eagle.sasl.protocol=SASL_PLAINTEXT
cluster1.kafka.eagle.sasl.mechanism=PLAIN
cluster1.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="kafka-eagle";
cluster2.kafka.eagle.sasl.enable=false
cluster2.kafka.eagle.sasl.protocol=SASL_PLAINTEXT
cluster2.kafka.eagle.sasl.mechanism=PLAIN
cluster2.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="kafka-eagle";
kafka.eagle.driver=org.sqlite.JDBC
kafka.eagle.url=jdbc:sqlite:./db/ke.db
kafka.eagle.username=root
kafka.eagle.password=www.kafka-eagle.org
主要就是修改了下zk的地址和sqlite数据库的路径,其它保持默认
启动进程:
export KE_HOME=/root/kafka-eagle-bin-1.3.9/kafka-eagle-web-1.3.9
export PATH=$PATH:$KE_HOME/bin
./bin/ke.sh start
登录web页面
http://192.168.2.4:8048/ke/
用户名 admin
密码 123456
具体功能,大家自由探索,整个工具还是很强大的。
maxwell 使用的是 1.22.4 版本
0、在 192.168.2.4的mysql开通账号,便于maxwell连接上去拉取binlog
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'XXXXXX';
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
1、在192.168.20.10上部署 maxwell
cd /usr/local/
curl -sLo - https://github.com/zendesk/maxwell/releases/download/v1.22.4/maxwell-1.22.4.tar.gz | tar zxvf -
cd maxwell-1.22.4/
2、输出到kafka的方式
2.1 拷贝 kafka-clients-2.3.0.jar 到 maxwell的lib/kafka-clients/目录下
2.2 修改配置文件
cp config.properties.example config.properties 然后修改下, 修改后的内容如下:
log_level=info
producer=kafka
# maxwell的元数据存放的MySQL的连接信息
host=localhost
user=maxwell
password=maxwell
producer=kafka
host=127.0.0.1
port=3306
user=maxwell
password=XXXXXX
schema_database=maxwell
gtid_mode=true
ssl=DISABLED
replication_ssl=DISABLED
schema_ssl=DISABLED
# 上游MySQL的连接信息
replication_host=192.168.2.4
replication_user=maxwell
replication_password=XXXXXX
replication_port=3306
# 定义需要输出哪些数据
output_binlog_position=true
output_gtid_position=true
output_nulls=true
output_server_id=true
output_ddl=true
output_commit_info=true
kafka.bootstrap.servers=192.168.2.4:9092 # 生产环境上,这里需要填多个kafka的连接方式
kafka_topic=maxwell
ddl_kafka_topic=maxwell_ddl
kafka.compression.type=snappy
kafka.retries=5
kafka.acks=1
producer_partition_by=database
# 下面是复制的过滤规则,不符合下面条件的binlog不会被保留下来【支持正则表达式】
# filter= exclude: test.*, include: db.*, include: coupons.*, include: testdb.user
# 暴露metrics地址用于监控
metrics_type=http
metrics_prefix=MaxwellMetrics
metrics_jvm=true
http_port=8081
2.3 前台启动
启动前,先去创建2个topic:
bin/kafka-topics.sh --zookeeper 192.168.2.4:2181 --create --topic maxwell --partitions 20 --replication-factor 2
bin/kafka-topics.sh --zookeeper 192.168.2.4:2181 --create --topic maxwell_ddl --partitions 6 --replication-factor 2
测试期间,我们先前台启动maxwell进程
bin/maxwell --config config.properties --producer=kafka --kafka_version=2.3.0
另外建议:在 192.168.2.4 上我们启动2个前台consumer进程,用于观察数据进入kafka的情况:
cd /opt/kafka1/bin/
./kafka-console-consumer.sh --bootstrap-server 192.168.2.4:9092 --topic maxwell
./kafka-console-consumer.sh --bootstrap-server 192.168.2.4:9092 --topic maxwell_ddl
maxwell topic里面的数据;类似这样:
{"database":"test","table":"resourcesinfo","type":"delete","ts":1571644826,"xid":5872872,"xoffset":78,"position":"mysql-bin.0003306,"data":{"id":94,"name":"222","hostname":"33","spec":"","belong":"","createtime":"0000-00-00 00:00:00.000000"}}
maxwell_ddl topic里面的数据;类似这样:
{"type":"table-create","database":"leaf","table":"d2sf","def":{"database":"leaf","charset":"utf8mb4","table":"d2sf","columns":[{"type":"varchar","name":"biz_tag","charset":"utf8mb4"},{"type":"bigint","name":"max_id","signed":true},{"type":"int","name":"step","signed":true},{"type":"varchar","name":"description","charset":"utf8mb4"},{"type":"timestamp","name":"update_time","column-length":0}],"primary-key":["biz_tag"]},"ts":1571642076000,"sql":"create table d2sf like leaf_alloc","position":"mysql-bin.000003:172413504","gtid":"fd2adbd9-e263-11e8-847a-141877487b3d:1386014"}
不是这里的重点步骤。
我这里是在 192.168.2.4上,部署的单机多实例的mongodb复制集。
192.168.2.4:27017 standby
192.168.2.4:27017 primary
192.168.2.4:27019 ARBITER
没有设置密码登录。
然后,创建个测试用的数据库和表
production:PRIMARY> use testdb
production:PRIMARY> db.createCollection("maxwell")
NIFI是一个ETL工具,比较简单。
cd /root/
tar xf nifi-1.9.2.tar.gz -C ./
cd /root/nifi-1.9.2
我们这里也不优化相关参数了,先尝试跑起来看看效果
./bin/nifi.sh start
稍等3分钟,查看下状态
./bin/nifi.sh status
Java home: /usr/local/jdk
NiFi home: /root/nifi-1.9.2
Bootstrap Config File: /root/nifi-1.9.2/conf/bootstrap.conf
2019-10-21 17:46:48,372 INFO [main] org.apache.nifi.bootstrap.Command Apache NiFi is currently running, listening to Bootstrap on port 43024, PID=130790
访问web界面
http://192.168.2.4:8080/nifi/
拖动 "process group" 这个按钮,到网页中间,创建一个名为test的 "process group"
然后双击 test这个方框,在这个页面上,创建一个2个processpor,并用线条连接起来
高能预警: 下面的配置操作,有点难度,我贴的图也不太好叙述,不一定能帮到您,如果有问题需要自己再摸索下!
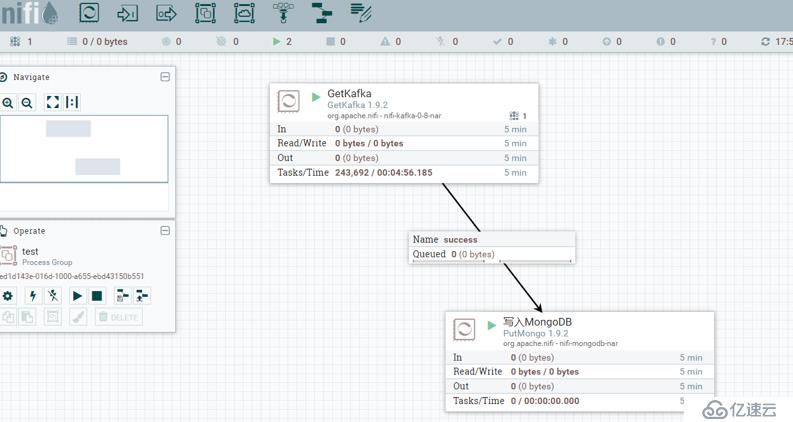

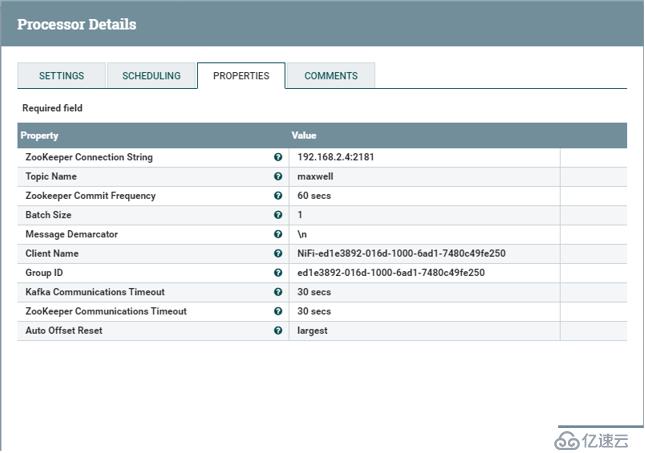
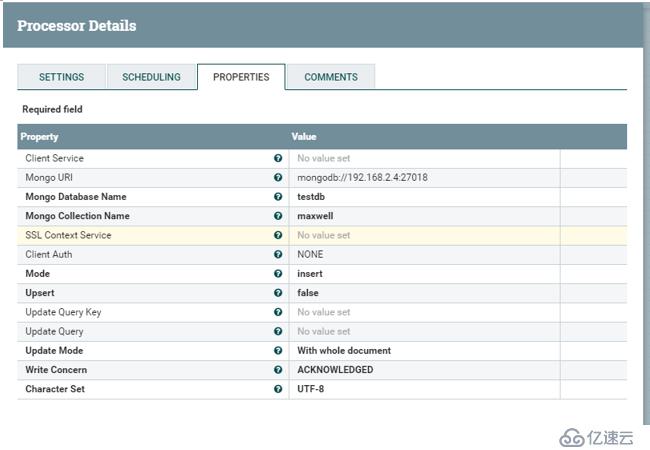
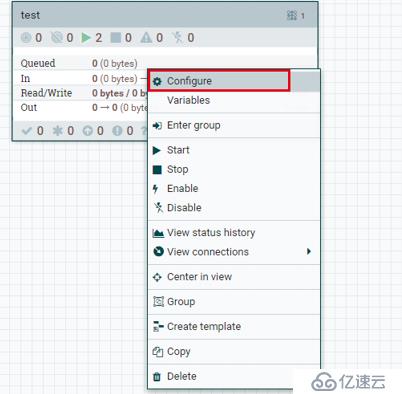
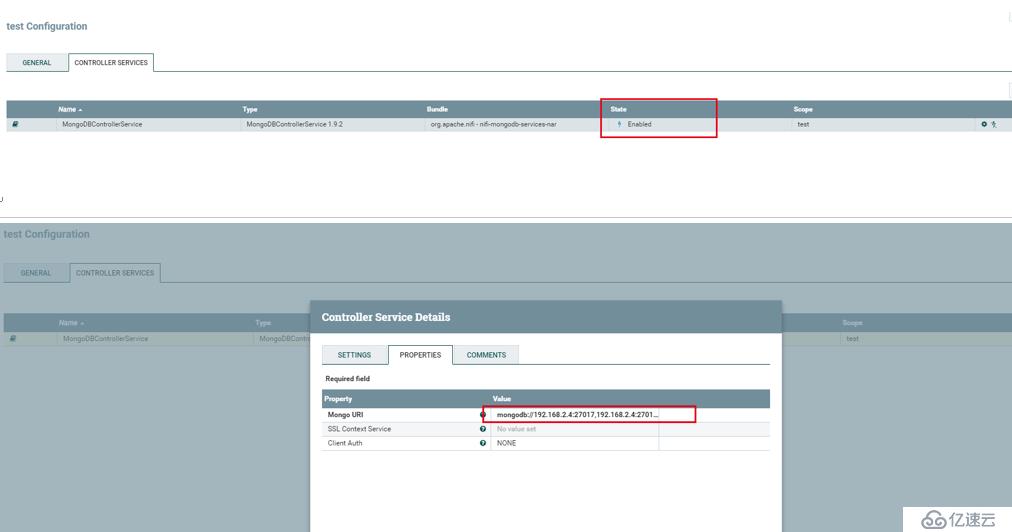
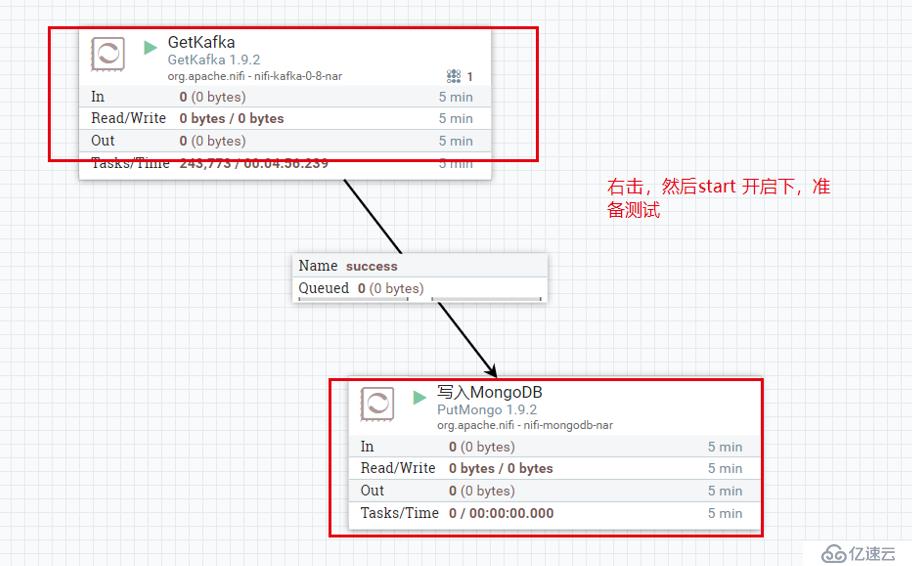
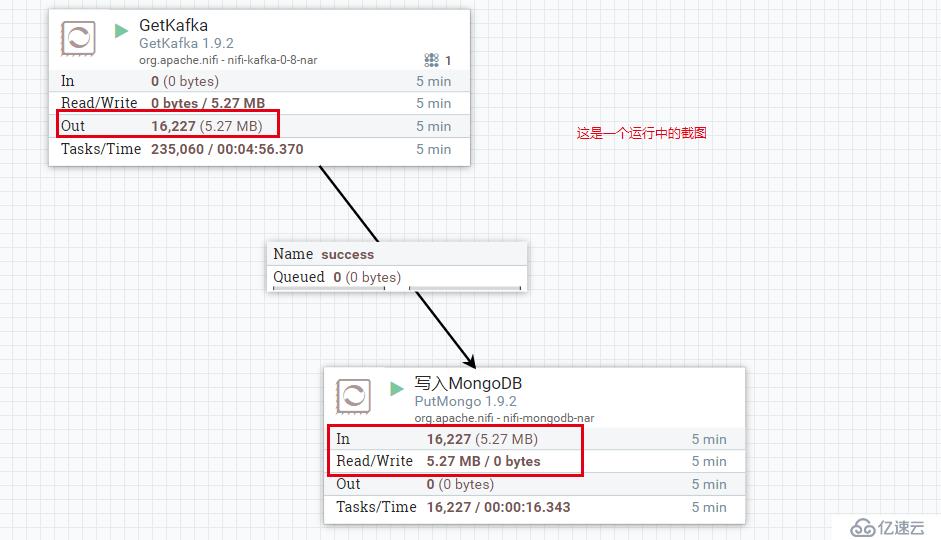
然后,我们再 192.168.2.4 上,随便的crud些数据, 看看 NIFI 界面上是否有数值的变化。
如果,这里没问题后。我们到mongodb数据库里面看看数据是否进去了。
到mongodb里面,查看是否有数据进来
use maxwell
db.maxwell.findOne()
有数据后,我们就可以继续基于mongodb的各种操作了
db.maxwell.createIndex({ts:1},{background:true})
db.maxwell.createIndex({table:1},{background:true})
db.maxwell.createIndex({database:1},{background:true})
db.maxwell.createIndex({database:1,table:1},{background:true})
db.maxwell.find({"table":"tbsdb"}).pretty()
db.maxwell.find({"table":"leaf_alloc"}).pretty()
db.maxwell.find({"database":"leaf"}).pretty()
db.maxwell.find({"database":"test"}).pretty() 日志类似这样:
统计某个时间范围内的操作:
db.maxwell.count({'ts':{$lt:1571673600,$gt:1571587200},"database":"test","type":"delete"})
db.maxwell.count({'ts':{$lt:1571673600,$gt:1571587200},"database":"test","type":"update"})
db.maxwell.count({'ts':{$lt:1571673600,$gt:1571587200},"database":"test","type":"insert"})
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





