算法介绍
概念
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
原理
在一份给定的文件里,词频(termfrequency,TF)指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
逆向文件频率(inversedocumentfrequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF*IDF,TF词频(TermFrequency),IDF反文档频率(InverseDocumentFrequency)。TF表示词条在文档d中出现的频率(另一说:TF词频(TermFrequency)指的是某一个给定的词语在该文件中出现的次数)。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。(另一说:IDF反文档频率(InverseDocumentFrequency)是指果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。)但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
最近要做领域概念的提取,TFIDF作为一个很经典的算法可以作为其中的一步处理。
计算公式比较简单,如下:

预处理
由于需要处理的候选词大约后3w+,并且语料文档数有1w+,直接挨个文本遍历的话很耗时,每个词处理时间都要一分钟以上。
为了缩短时间,首先进行分词,一个词输出为一行方便统计,分词工具选择的是HanLp。
然后,将一个领域的文档合并到一个文件中,并用“$$$”标识符分割,方便记录文档数。

下面是选择的领域语料(PATH目录下):
代码实现
package edu.heu.lawsoutput;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @ClassName: TfIdf
* @Description: TODO
* @author LJH
* @date 2017年11月12日 下午3:55:15
*/
public class TfIdf {
static final String PATH = "E:\\corpus";
// 语料库路径
public static void main(String[] args) throws Exception {
String test = "离退休人员";
// 要计算的候选词
computeTFIDF(PATH, test);
}
/**
* @param @param path 语料路经
* @param @param word 候选词
* @param @throws Exception
* @return void
*/
static void computeTFIDF(String path, String word) throws Exception {
File fileDir = new File(path);
File[] files = fileDir.listFiles();
// 每个领域出现候选词的文档数
Map<String, Integer> containsKeyMap = new HashMap<>();
// 每个领域的总文档数
Map<String, Integer> totalDocMap = new HashMap<>();
// TF = 候选词出现次数/总词数
Map<String, double> tfMap = new HashMap<>();
// scan files
for (File f : files) {
// 候选词词频
double termFrequency = 0;
// 文本总词数
double totalTerm = 0;
// 包含候选词的文档数
int containsKeyDoc = 0;
// 词频文档计数
int totalCount = 0;
int fileCount = 0;
// 标记文件中是否出现候选词
Boolean flag = false;
FileReader fr = new FileReader(f);
BufferedReader br = new BufferedReader(fr);
String s = "";
// 计算词频和总词数
while ((s = br.readLine()) != null) {
if (s.equals(word)) {
termFrequency++;
flag = true;
}
// 文件标识符
if (s.equals("$$$")) {
if (flag) {
containsKeyDoc++;
}
fileCount++;
flag = false;
}
totalCount++;
}
// 减去文件标识符的数量得到总词数
totalTerm += totalCount - fileCount;
br.close();
// key都为领域的名字
containsKeyMap.put(f.getName(), containsKeyDoc);
totalDocMap.put(f.getName(), fileCount);
tfMap.put(f.getName(), (double) termFrequency / totalTerm);
System.out.println("----------" + f.getName() + "----------");
System.out.println("该领域文档数:" + fileCount);
System.out.println("候选词出现词数:" + termFrequency);
System.out.println("总词数:" + totalTerm);
System.out.println("出现候选词文档总数:" + containsKeyDoc);
System.out.println();
}
//计算TF*IDF
for (File f : files) {
// 其他领域包含候选词文档数
int otherContainsKeyDoc = 0;
// 其他领域文档总数
int otherTotalDoc = 0;
double idf = 0;
double tfidf = 0;
System.out.println("~~~~~" + f.getName() + "~~~~~");
Set<Map.Entry<String, Integer>> containsKeyset = containsKeyMap.entrySet();
Set<Map.Entry<String, Integer>> totalDocset = totalDocMap.entrySet();
Set<Map.Entry<String, double>> tfSet = tfMap.entrySet();
// 计算其他领域包含候选词文档数
for (Map.Entry<String, Integer> entry : containsKeyset) {
if (!entry.getKey().equals(f.getName())) {
otherContainsKeyDoc += entry.getValue();
}
}
// 计算其他领域文档总数
for (Map.Entry<String, Integer> entry : totalDocset) {
if (!entry.getKey().equals(f.getName())) {
otherTotalDoc += entry.getValue();
}
}
// 计算idf
idf = log((float) otherTotalDoc / (otherContainsKeyDoc + 1), 2);
// 计算tf*idf并输出
for (Map.Entry<String, double> entry : tfSet) {
if (entry.getKey().equals(f.getName())) {
tfidf = (double) entry.getValue() * idf;
System.out.println("tfidf:" + tfidf);
}
}
}
}
static float log(float value, float base) {
return (float) (Math.log(value) / Math.log(base));
}
}
运行结果
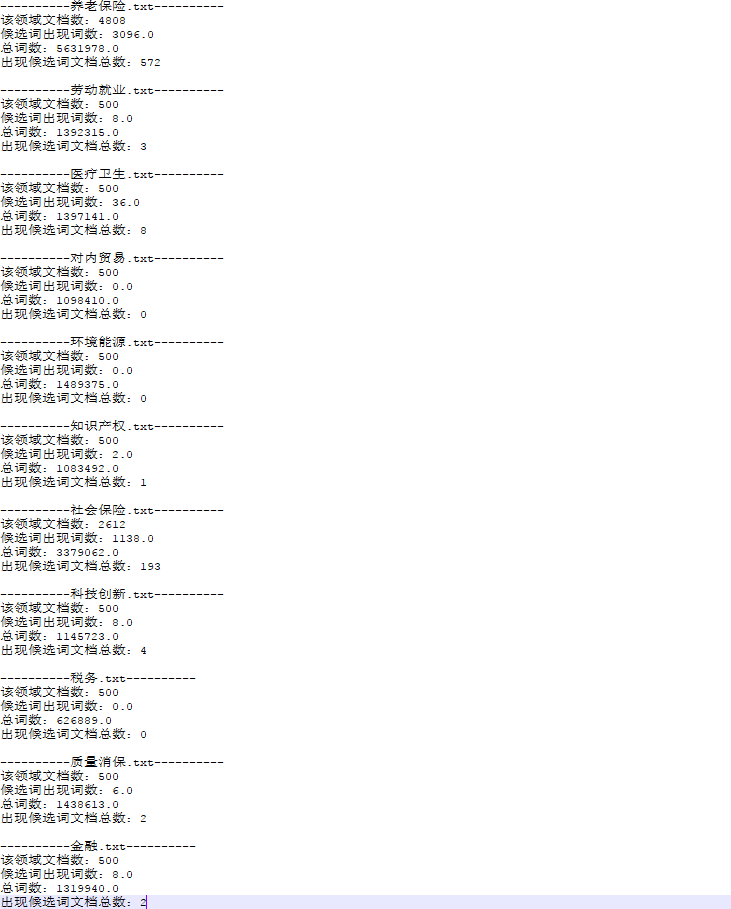
测试词为“离退休人员”,中间结果如下:
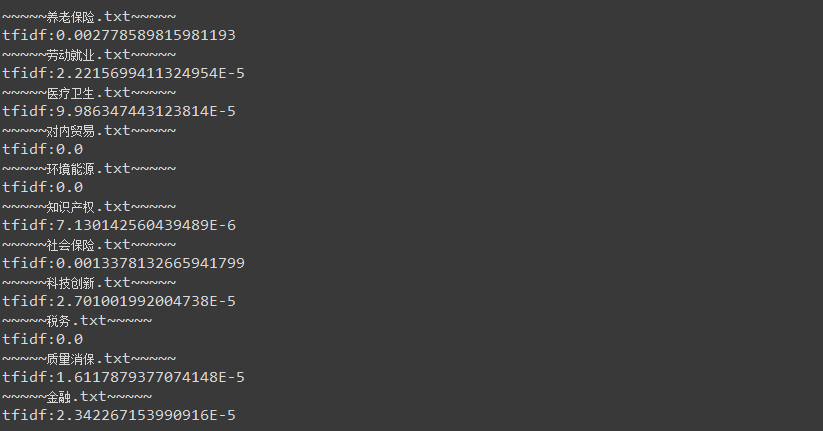
最终结果:
结论
可以看到“离退休人员”在养老保险和社保领域,tfidf值比较高,可以作为判断是否为领域概念的一个依据。
当然TF-IDF算法虽然很经典,但还是有许多不足,不能单独依赖其结果做出判断。
以上就是本文关于Java实现TFIDF算法代码分享的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:
Java 蒙特卡洛算法求圆周率近似值实例详解
java算法实现红黑树完整代码示例
java实现的各种排序算法代码示例
如有不足之处,欢迎留言指出。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





