小编给大家分享一下Python爬虫中获取Ajax方式加载数据的方法,希望大家阅读完这篇文章后大所收获,下面让我们一起去探讨吧!
获取Ajax方式加载的数据
爬虫最需要关注的不是页面信息,而是页面信息的数据来源。
Ajax方式加载的页面,数据来源一定是JSON,直接对AJAX地址进行post或get,拿到JSON,就是拿到了网页数据。
(1)先通过浏览器访问豆瓣电影排行榜
https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
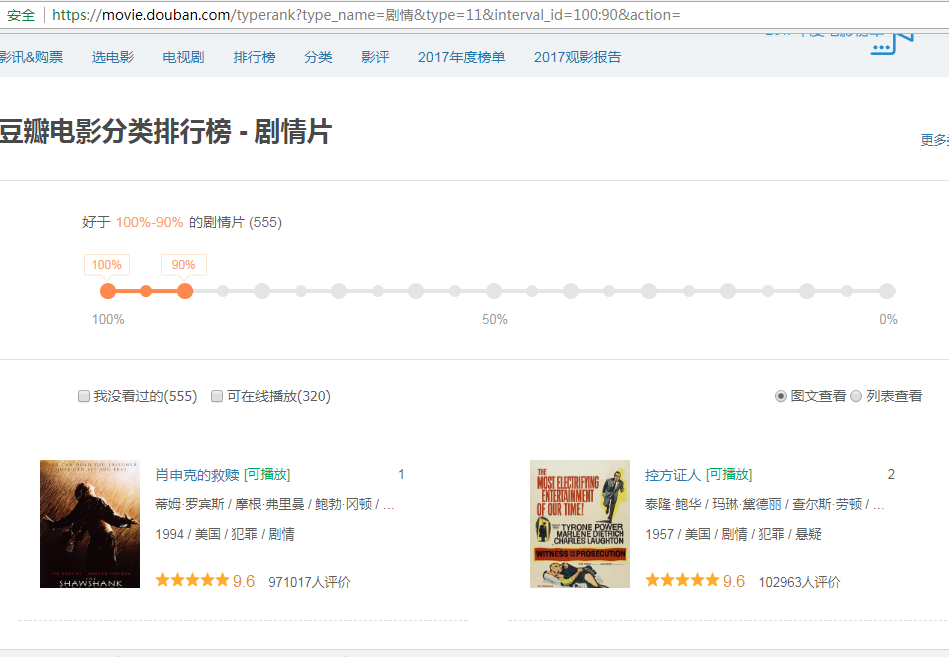
(2)浏览器访问后,通过抓包工具就可以获取我们想要的一些信息。
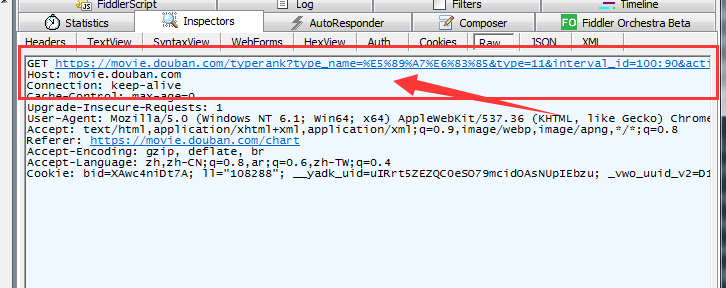
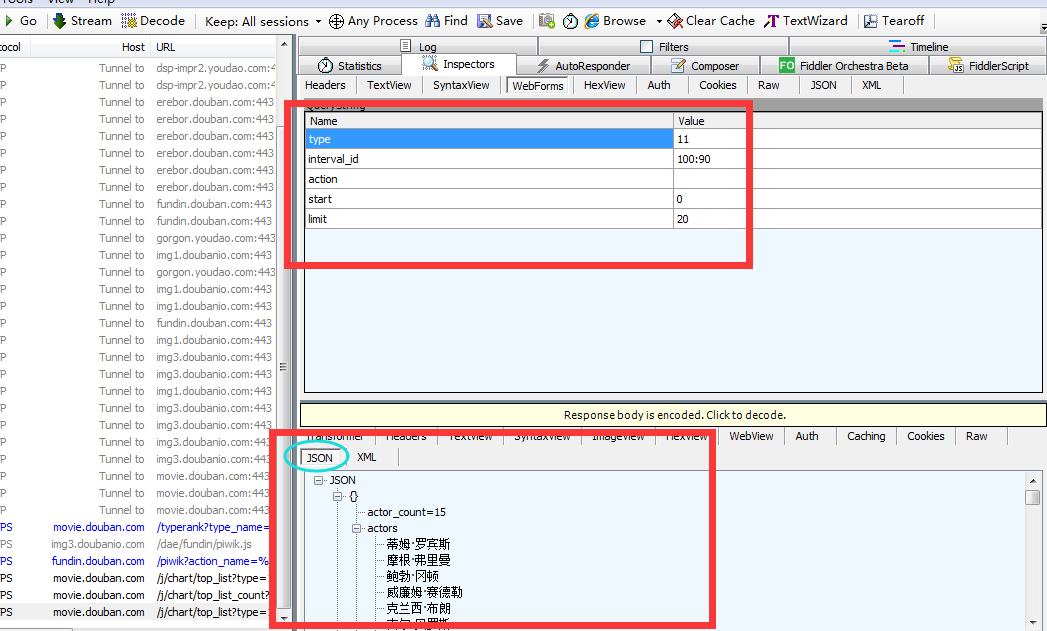
只要response里面有 JSON数据,我们就可以找到服务器的数据来源。
分析发现变动的是start value和limit value, type,interval_id,action,固定不变,这三个url中已经包含了,所以formdata只用传start和limit。
import urllib
import urllib2
url = 'https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action='
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/60.0.3112.101 Safari/537.36'}
# start和limit可以自己随便设置
formdata = {'start':'20','limit':'100'}
data = urllib.urlencode(formdata)
request = urllib2.Request(url,data = data,headers=headers)
response = urllib2.urlopen(request)
print response.read()看完了这篇文章,相信你对Python爬虫中获取Ajax方式加载数据的方法有了一定的了解,想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





