这篇文章主要讲解了“InnoDB的外存数据结构介绍”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“InnoDB的外存数据结构介绍”吧!
“Everything is a file…”这句至理名言告诉我们一切都得从文件说起。那么对 InnoDB 外存数据结构的学习,我们也先从表和文件开始。
当我们使用 CREATE TABLE 创建一个表时,MySQL 会创建一个 .frm 文件和一个 .ibd 文件。.frm 文件是描述表结构定义的文件,而 .ibd 文件是 InnoDB 引擎层特有的,用于记录InnoDB表的数据。举个例子,在 db.CCCtest 下创建一个表”jersey_test”,建表语句如下:
CREATE TABLE `jersey_test` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `requestId` char(64) NOT NULL COMMENT 'request', `type` smallint(6) NOT NULL DEFAULT '0' COMMENT '类型', `name` varchar(64) NOT NULL COMMENT 'name', PRIMARY KEY (`id`), KEY `request` (`requestId`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
同时,我们往表中插入一条记录如下:
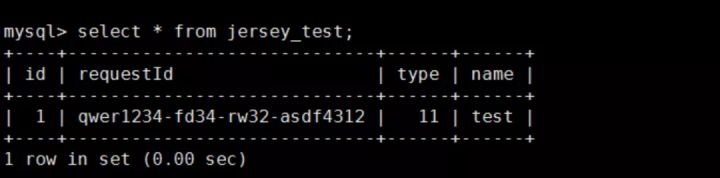
[ jersey_test 表中的数据 ]
我们进入到 MySQL 的 /data 目录下面,可以看到”jersey_test.frm”文件和”jersey_test.ibd”文件。
 [ CCCtest 库中的文件 ]
[ CCCtest 库中的文件 ]
.frm 文件是二进制格式的,我们通过 hexdump 工具稍加分析,可以看到文件中除了一些编码信息外,主要内容就是表结构信息。
 [ .frm 文件内容 ]
[ .frm 文件内容 ]
这和我们使用 DESC TABLE 语法看到的表结构描述一致。
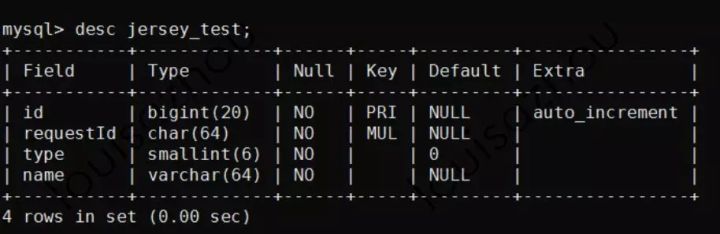 [ 表结构描述 ]
[ 表结构描述 ]
数据文件 .ibd 的分析与之类似。
InnoDB 中的表都是分文件存储的,表中的行数据也按照相应的格式记录在文件中。这里我们简要归纳一下 InnoDB 所支持的文件存储格式和行存储格式。InnoDB 的文件格式由参数 innodb_file_format 指定,它支持 Antelope 和 Barracuda 两种文件格式。Barracuda 是新的文件格式,它是包含 Antelope 格式在内的。Antelope 文件格式支持两种行存储格式,Compact 和 Redundant ,Barracuda 支持的新的行存储格式为 Compressed 和 Dynamic。
 [ InnoDB行存储格式 ]
[ InnoDB行存储格式 ]
InnoDB 表的行存储格式由参数 innodb_default_row_format 指定,在 5.7 版本中的默认值为 Dynamic 。行存储格式决定了表中的记录在文件中是如何进行存储的,不同的行存储格式有其特殊的优势和劣势,也会影响数据库的行为。例如,使用 Compressed 这种格式可以使行记录有更高的压缩比,如果一个物理页能存放的行记录越多,它的索引或记录查找会更快,内存消耗也会更小,但是压缩数据本身也会带回额外的系统开销。另外一个需要注意的地方是,在进行数据库表迁移时,需要关注源实例和目标实例的 Row Format 是否匹配。比如你有一个 MyISAM 的表要迁移到 InnoDB 上,并且 MyISAM 表的 Row Format 为默认值 Fixed ,此时需要改成 Dynamic ,因为这两种格式对变长字段如 varchar/blob/text 等的处理是不一致的。
我们前面谈到,InnoDB 每个表都有自己独立的文件,其实是用到了它的默认行为,即使用独立表空间,它由参数 innodb_file_per_table 控制。事实上 InnoDB 包含多种表空间类型,包括系统表空间 ( System TableSpace ),独立表空间 ( File-Per-Table TableSpace ) 和通用表空间 ( General TableSpace ) 等。
系统表空间存储了 InnoDB 的数据字典(元数据信息),系统表,双写缓冲区 ( doublewrite buffer ),Change Buffer 等。如果将参数 innodb_file_per_table 置为 OFF ,即所有的表数据都存储在系统表空间中。但是在使用 InnoDB 时,更推荐的方法是将 innodb_file_per_table 置为 ON,即使用独立表空间,它有如下几个好处:
当使用 Truncate Table 和 Drop Table 命令删除表时,系统会直接删除表的数据文件,即回收物理空间。而使用系统表空间则无法回收这些物理空间;
和上面类似,当使用重建表的语法时,如 OPTIMIZE TABLE 或者 ALTER TABLE ENGINE = InnoDB 时,系统也能够回收物理空间;
可以单独将某个表指定到对应的存储位置,这个存储位置可以不在 MySQL 的数据目录下。比如你想使用 RAID 或者 SSD 来存储某个表,当你使用独立表空间时,就可以通过 CREATE TABLE … DATA DIRECTORY 这个语法来实现。
使用独立表空间也有一些潜在的问题。例如,每个表都有自己的单独的文件,容易造成物理空间的浪费,如果数据库有很多小表的话,这种空间浪费也会比较明显。通用表空间 ( General TableSpace ) 可以缓解这个问题。通用表空间可以认为是 all-in-one (系统表空间) 和 file-per-table 的一个折中,它允许你使用 CREATE TABLESPACE 语法创建一个大的空间,然后你可以向这个空间中添加一些表的数据文件进行存储,这些表的数据文件是共享存储空间的。
索引可以说是 InnoDB 最重要的数据结构,介绍数据库索引的资料也很多,谈点题外话,什么是索引呢?索引其实就是帮助我们快速查找到数据( data ) 的辅助结构,可以说有数据的地方就需要索引。比如在文件系统里,数据的索引保存在元数据 inode 信息中,它记录着这个文件所有的数据页( data pages ) 具体在哪个位置,比如文件有10个页,它就对应记录10个页框的物理地址。文件系统的索引当然也会有直接索引和间接索引,因为如果直接索引装不下,就会用二级索引来装,其结构如下图所示,
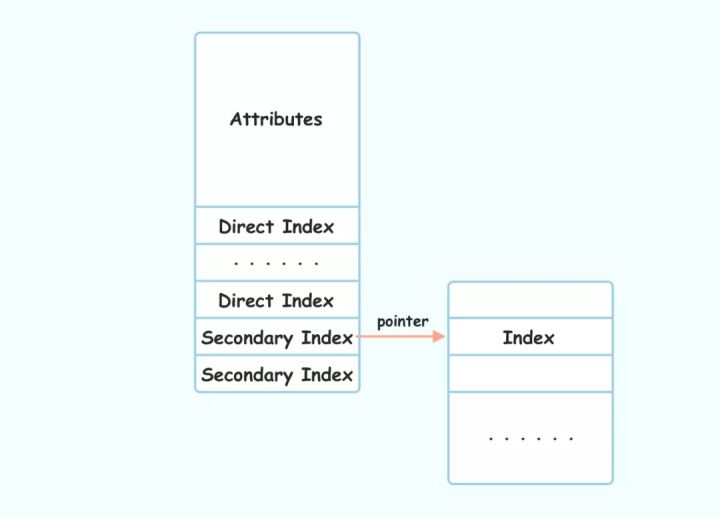 [ 文件系统 inode 结构 ]
[ 文件系统 inode 结构 ]
操作系统中最常见(也可能是最快)的索引大概是虚拟地址到物理地址的映射表。之所以快,首先在于它是连续的,当你进行跨页访问的时候不需要去计算下一个页的地址,另外地址的转换是由专门的硬件MMU来做的,硬件肯定更快。可以设想一下,如果文件存储或者数据库存储的索引也采用虚拟地址映射表加上硬件加速的话,肯定会比现有的方式更快。虚拟地址直接映射到进程地址空间还可以减少进入内核态的开销。
说回 InnoDB 的索引结构,InnoDB 的索引采用 B+ 树这种数据结构,InnoDB 表中的行数据都是由聚簇索引 ( clustered index ) 组织的,它也被称作主键索引 ( primar key ),即主键索引这棵 B+ 树的叶子节点存储的是主键对应的整行数据。为 InnoDB 的每个表都建立自增的主键索引非常重要,之所以需要自增,是因为在插入新记录时可以做到连续,追加插入,这样可以减少索引查找和索引页分裂所带来的额外开销。InnoDB 其他的索引称为二级索引 ( secondary index ),二级索引的叶子节点存储的是主键索引的值,因此,绝大多数使用二级索引查询记录时,都会先通过二级索引找到主键索引的值,再通过主键索引找到行记录。
在 InnoDB 中,数据一致性由 Redo Log 来保证,它使用的是 WAL(Write-Ahead Logging) 机制,即先写日志再写数据。InnoDB 使用这种方式在进行故障恢复时,会将 Redo Log 中的日志重做一遍,也就是将系统中未提交的事务重新执行。默认情况下,Redo Log 记录在磁盘的 ib_logfile0 和 ib_logfile1 这两个文件里,MySQL 循环的写这两个文件,因此,Redo Log 会有写满的情况,这里就需要介绍日志中的 checkpoint 机制。checkpoint 记录了整个系统当前日志已经同步到的位置,也就是说,在 checkpoint 之前的事务都是已经提交的事务,数据不会存在不一致的情况。而当 MySQL 写入 Redo Log 记录追上 checkpoint 时,Redo Log 就写满了,此时需要等待 Redo Log 同步数据并释放空间。
另一方面,在数据库这种存储系统中,更新操作失败并回滚的情况是很常见的,所以需要特别关注这种情况,Undo Log 就是用来解决这个问题。Undo Log 记录的是当一个更新操作失败需要回滚时,应该进行哪些反向操作。即当你 insert 一条记录时,Undo log中会记录一条对应的 delete 记录,反之亦然。
Redo Log 解决了本地数据(这里是指单点实例)一致性的问题。但是数据库要做到高可用,还需要考虑多副本或跨区跨地域容灾。MySQL Binlog 就提供了这种能力,Binlog 支持 Statement,Row 和 Mixed 三种模式。其中, Row 模式会记录每行数据的修改操作,相比 Statement 模式,它能保证主从复制的正确性。
前面已经提到,Redo Log 和 Binlog 必须同时使用才能做到数据一致且高可用。接下来简要分析一下数据库进行插入或更新操作时是如何做到这一点的。MySQL 使用 WAL 机制进行更新操作,即先写 Redo Log 和 Binlog,然后再写数据。写 Redo Log 和 Binlog 必须保证原子性,要么都更新成功,要么都更新失败,否则会造成本地数据和其他副本数据不一致的情况。更新 Redo Log 和 Binlog 的过程称为两阶段提交,其步骤为:
先将更新的操作写到 Redo Log,此时流程标记为 prepare 状态;
更新 Binlog,此时需将 BinLog 刷回磁盘才能视为成功;
提交事务(此时还会清除该事务 Undo 日志),流程标记为 commit 状态。
两阶段提交可以保证数据的一致性,它在任何一个阶段异常失败都可以进行恢复。比如,如果事务已经是 commit 状态,此时Redo Log 和 Binlog 都已更新成功;如果是在 prepare 状态,此时就需要判断 BinLog 中是否有完整的信息,如果有,则会进行 commit,如果没有完整信息,则整个事务回滚。
感谢各位的阅读,以上就是“InnoDB的外存数据结构介绍”的内容了,经过本文的学习后,相信大家对InnoDB的外存数据结构介绍这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





