在看源码之前,先看几遍论文《基于角色标注的中国人名自动识别研究》
关于命名识别的一些问题,可参考下列一些 issue:
u u名字识别的问题 #387
u u机构名识别错误
u u关于层叠HMM中文实体识别的过程
HanLP参考博客:
词性标注
层叠 HMM-Viterbi角色标注模型下的机构名识别
分词
在 HMM与分词、词性标注、命名实体识别中说:
分词:给定一个字的序列,找出最可能的标签序列(断句符号: [词尾]或[非词尾]构成的序列)。结巴分词目前就是利用BMES标签来分词的,B(开头),M(中间),E(结尾),S(独立成词)
分词也是采用了维特比算法的动态规划性质求解的,具体可参考:文本挖掘的分词原理
角色观察
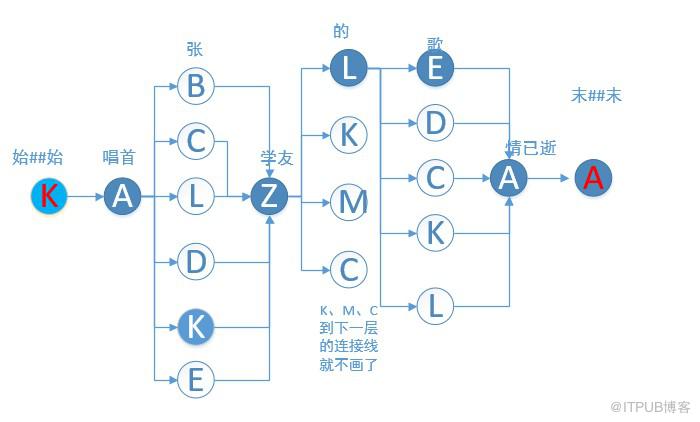
以 “唱首张学友的歌情已逝”为例,
先将起始顶点 始 ##始,角色标注为:NR.A 和 NR.K,频次默认为1
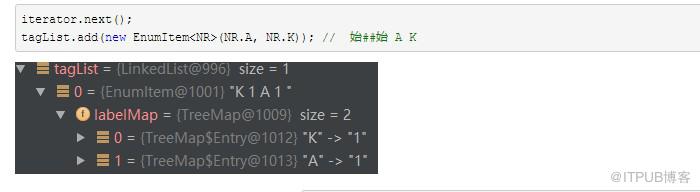
对于第一个词 “唱首”,它不存在于 nr.txt中, EnumItem<NR> nrEnumItem = PersonDictionary.dictionary.get(vertex.realWord); 返回 null,于是根据它本身的词性猜一个角色标注:
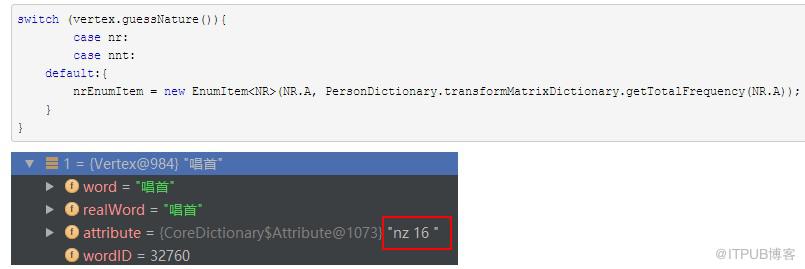
由于 "唱首"的Attribute为 nz 16,不是nr 和 nnt,故默认给它指定一个角色NR.A,频率为nr.tr.txt中 NR.A 角色的总频率。
此时,角色列表如下:

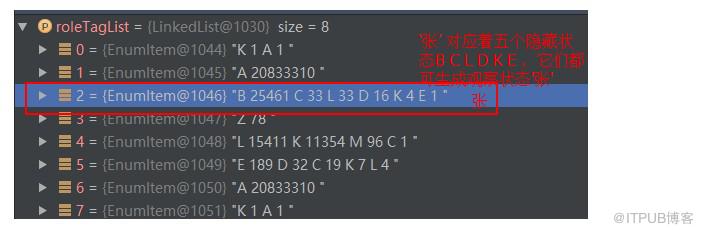
接下来是顶点 “张”,由于“张”在nr.txt中,因此 PersonDictionary.dictionary.get(vertex.realWord) 返回 EnumItem对象,直接将它加入到角色列表中:

加入 “张”之后的角色列表如下:
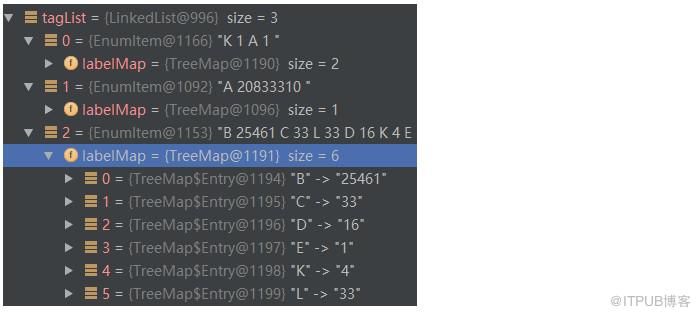
“唱首张学友的歌情已逝” 整句的角色列表如下:
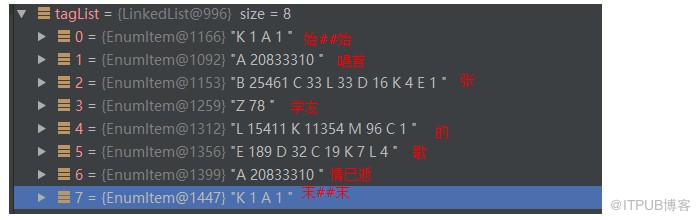
至此,角色观察 部分 就完成了。
总结一下,对句子进行角色观察,首先是通过分词算法将句子分成若干个词,然后对每个词查询人名词典 (PersonDictionary)。
u 若这个词在人名词典中 (nr.txt),则记录该词的角色,所有的角色在 com.hankcs.hanlp.corpus.tag.NR.java 中定义。
u 若这个词不在人名词典中,则根据该词的 Attribute “猜一个角色”。在猜的过程中,有些词在核心词典中可能已经标注为nr或者nnt了,这时会做分裂处理。其他情况下则是将这个词标上NR.A角色,频率为 NR.A 在转移矩阵中的总词频。
维特比算法 (动态规划)求解最优路径
在上图中,给每个词都打上了角色标记,可以看出,一个词可以有多个标记。而我们需要将这些词选择一条路径最短的角色路径。参考 隐马尔可夫模型维特比算法详解
List<NR> nrList = viterbiComputeSimply(roleTagList); //some code.... return Viterbi.computeEnumSimply(roleTagList, PersonDictionary.transformMatrixDictionary);
而这个过程,其实就是:维特比算法解码隐藏状态序列。在这里,五元组是:
u 隐藏状态集合 com.hankcs.hanlp.corpus.tag.NR.java 定义的各个人名标签
u 观察状态集合 已经分好词的各个 tagList中元素(相当于分词结果)
u 转移概率矩阵 由 nr.tr.txt 文件生成得到。具体可参考:
u 发射概率 某个人名标签 (隐藏状态)出现的次数 除以 所有标签出现的总次数
Math.log((item.getFrequency(cur) + 1e-8) / transformMatrixDictionary.getTotalFrequency(cur)
u 初始状态 (始##始) 和 结束状态(末##末)
维特比解码隐藏状态的动态规划求解核心代码如下:
for (E cur : item.labelMap.keySet())
{
double now = transformMatrixDictionary.transititon_probability[pre.ordinal()][cur.ordinal()] - Math.log((item.getFrequency(cur) + 1e-8 ) / transformMatrixDictionary.getTotalFrequency(cur));
if (perfect_cost > now)
{
perfect_cost = now;
perfect_tag = cur;
}
}
transformMatrixDictionary.transititon_probability[pre.ordinal()][cur.ordinal()] 是前一个隐藏状态 pre.ordinal() 转换到当前隐藏状态 cur.ordinal() 的转移概率。 Math.log((item.getFrequency(cur) + 1e-8) / transformMatrixDictionary.getTotalFrequency(cur) 是当前隐藏状态的发射概率。二者 “相减”得到一个概率 保存在 double now 变量中,然后通过 for 循环找出 当前观察状态 对应的 最可能的(perfect_cost最小) 隐藏状态 perfect_tag。
至于为什么是上面那个公式来计算转移概率和发射概率,可参考论文:《 基于角色标注的中国人名自动识别研究 》
在上面例子中,得到的最优隐藏状态序列 (最优路径)K->A->K->Z->L->E->A->A 如下:
nrList = {LinkedList@1065} size = 8
"K" 始##始
"A" 唱首
"K" 张
"Z" 学友
"L" 的
"E" 歌
"A" 情已逝
"A" 末##末
例如:
隐藏状态---观察状态
"K"----------始##始
最大匹配
有了最优隐藏序列: KAKZLEAA,接下来就是:后续的“最大匹配处理”了。
PersonDictionary.parsePattern(nrList, pWordSegResult, wordNetOptimum, wordNetAll);
在最大匹配之前,会进行 “模式拆分”。在com.hankcs.hanlp.corpus.tag.NR.java 定义了隐藏状态的具体含义。比如说,若最优隐藏序列中 存在 'U' 或者 'V',
U Ppf 人名的上文和姓成词 这里【有关】天培的壮烈
V Pnw 三字人名的末字和下文成词 龚学平等领导, 邓颖【超生】前
则会做 “拆分处理”
switch (nr)
{
case U:
//拆分成K B
case V:
//视情况拆分
}
拆分完成之后,重新得到一个新的隐藏序列 (模式)
String pattern = sbPattern.toString();
接下来,就用 AC自动机进行最大模式匹配了,并将匹配的结果存储到“最优词网”中。当然,在这里就可以自定义一些针对特定应用的 识别处理规则
trie.parseText(pattern, new AhoCorasickDoubleArrayTrie.IHit<NRPattern>(){
//.....
wordNetOptimum.insert(offset, new Vertex(Predefine.TAG_PEOPLE, name, ATTRIBUTE, WORD_ID), wordNetAll);
}
将识别出来的人名保存到最优词网后,再基于最优词网调用一次维特比分词算法,得到最终的分词结果 ---细分结果。
if (wordNetOptimum.size() != preSize)
{
vertexList = viterbi(wordNetOptimum);
if (HanLP.Config.DEBUG)
{
System.out.printf( "细分词网:\n%s\n" , wordNetOptimum);
}
}
总结
源码上的人名识别基本上是按照论文中的内容来实现的。对于一个给定的句子,先进行下面三大步骤处理:
角色观察
维特比算法解码求解隐藏状态(求解各个分词 的 角色标记)
对角色标记进行最大匹配(可做一些后处理操作)
最后,再使用维特比算法进行一次分词,得到细分结果,即为最后的识别结果。
这篇文章里面没有写维特比分词算法的详细过程,以及转移矩阵的生成过程,以后有时间再补上。看源码,对隐马模型的理解又加深了一点,感受到了理论的东西如何用代码一步步来实现。由于我也是初学,对源码的理解不够深入或者存在一些偏差,欢迎批评指正。
关于动态规划的一个简单示例,可参考:动态规划之 Fib数列类问题应用
文章来源 hapjin 的博客
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





