总的来说,对无监督数据进行聚类并非易事。现如今的数据处理和探索无法准确的测量数据。这也意味着我们对数据的处理和探索变得愈发困难。
此外,关于在无监督学习的入门课程中,对拿来讨论的理想的案例,k-means教程,也只适用于数值特性。

在这篇文章中,作者将通过R语言进行非监督分类训练。
第一部分包括方法论:作者正在讨论使用距离的数学概念来衡量个体间相似性的问题。然后介绍了PAM集群算法(围绕medoids进行分割)以及选择最佳集群数(轮廓系数)的方法。
在第二部分中,作者将使用uci机器学习数据库中提供的银行营销数据集和Rtsne软件包中的一些函数来说明该方法。该数据集与葡萄牙某银行机构的电话营销活动相关。我们会把这些数据用于对监督学习情况的讨论。
第一部分:方法论
如何测量相似性

(数据科学家作用在于在对未知数据进行集群时,我们不能盲人摸象,只看到事物的一面。他们主张与数据产生一定的"距离",以便更全面地了解它们。)
距离是对个体之间相隔多远的数值度量,也就是说,用于测量个体之间的接近度或相似度的度量。面对众多的度量,作者必须要介绍的是 Gower distance (1971)。
Gower距离被用于计算个体之间部分差异的平均值。(Gower距离的范围为[0 1]。)

其中表示不相似的(d_ij ^ f)计算取决于被评估的变量的类型。这意味着每个特性都应该有一个固定的标准,并且两个个体之间的距离是所有特性距离的平均值。
· 对于数值特性f,部分相异性是:观察的绝对差异x_i和x_j之间的比率,从所有个体观察到的最大范围:d_ij ^ f = | x_i - x_j | / |(max_N(x) - min_N(x))| ,N是数据集中的个体数量。

数值特性的部分差异度计算(R_f =观察到的最大范围)
· 对于定性特性f,仅当观测值y_i和y_j具有不同的值时,部分相异度等于1。否则为0。
注意:Gower距离可使用R集群包中的daisy()函数。首先自动标准化特性(即重新缩放以落在[0 1]范围内)。
聚类算法:围绕MEDOIDS(PAM)进行分区
Gower距离与k-medoids算法非常相似。k-medoid是一种经典的聚类技术,它将n个对象的数据集集群变为已知的k个集群。
与k-means算法非常相似,PAM具有以下特性:
· 优点:与k-means(由于使用距离的属性)相比,它更直观,对噪声和异常值更敏感,并且它为每个集群产生一个"典型个体"。
· 缺点:它耗费时间,属于计算机密集型(运行时和内存是二次的)。
评估数据集群内的一致性
除非你有一个很好的先验原理来强制特定数量的集群k,否则你可能会向计算机请求基于统计数据的推荐。存在若干方法来限定所选的集群的相关性。在第二部分中,我们使用了轮廓系数。
解释
基本上有两种方法可以调查这种集群实践的结果,以便得出一些专业的解释。
1.每个集群基本都要使用R中的summary()函数。
2.学会利用t-SNE,它是一种用于降维的技术,其特别适合于高维数据集的可视化。
我们在用例中介绍了这两种情况(第二部分)。让我们应用和说明!
第二部分:使用案例
在此用例中,我们将尝试根据以下特性对银行客户进行分组:
· 年龄(数字)
· 工作类型(类别):'行政'、'蓝领'、'企业家'、'女佣'、'管理'、'退休'、'自雇'、'服务'、'学生'、'技师'、'失业'、'未知'
· 婚姻状况(类别):'离婚'、'已婚'、'单身'、'未知'
· 教育(类别):'初级'、'中级'、'大专'、'未知'
· 违约:有过违约记录吗?(类别):'没有'、'有'、'未知'
· 余额(数字):年平均余额,以欧元为单位
· 住房:有住房贷款吗?(类别):'没有'、'有'、'未知'


根据Gower距离划分的相似和不同的客户:





在商业环境中,我们通常会搜索一些有意义且易于记忆的集群,即最多2到8个集群。轮廓图有助于我们确定最佳选择。


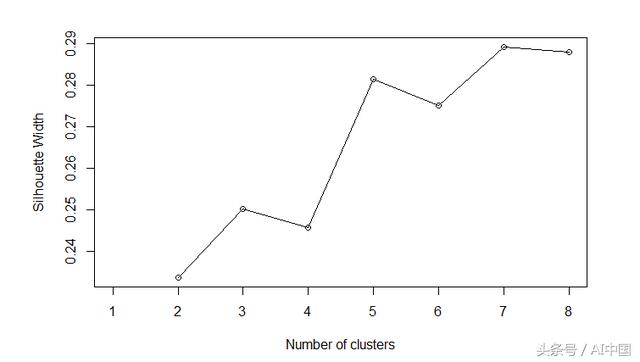
7具有最高的轮廓宽度。但是5更简单,我们选择k = 5
解释
每个集群的摘要
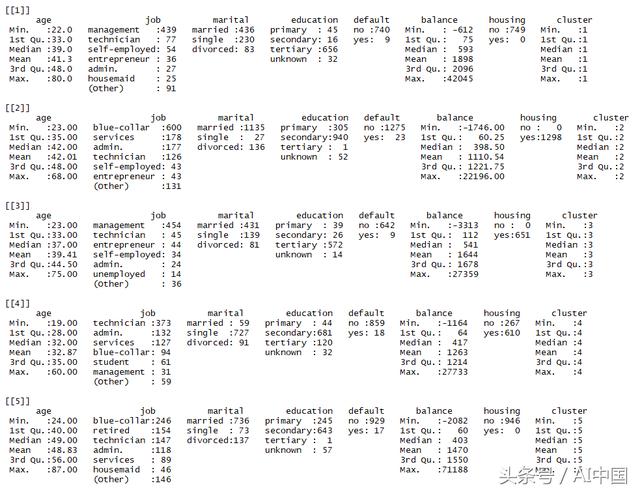
在这里,可以尝试为集群内的客户派生一些常见模式。例如,集群1由"管理x三级x无违约x无住房"客户组成,集群2由"蓝领x二级x无违约x住房"客户等组成。
较低维度空间中的可视化


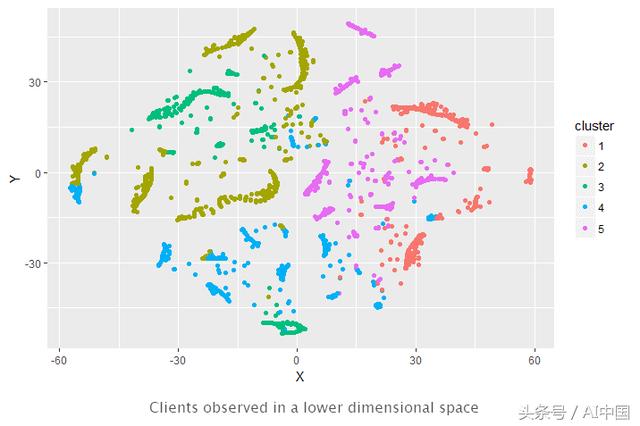
尽管不是很完美(尤其是集群3),但颜色大多位于相似区域,这证实了划分的相关性。
结论
本文回顾了作者在尝试对混合类型无监督数据集执行聚类算法时的想法。作者认为它可以为其他数据科学家带来一些有意思的想法,从而实现共享。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





