这篇文章给大家介绍Linux在多核可扩展性设计上的有哪些不足,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
我其实并不想讨论微内核的概念,也并不擅长去阐述概念,这是百科全书的事,但无奈最近由于鸿蒙的发布导致这个话题过火,也就经不住诱惑,加上我又一直比较喜欢操作系统这个话题,就来个老生常谈吧。
说起微内核,其性能往往因为IPC饱受诟病。然而除了这个显而易见的 “缺陷” ,其它方面貌似被关注的很少。因此我写点稍微不同的。
微内核的性能 “缺陷” 我假设是高开销的IPC引起的(实际上也真是),那么,我接下来便继续假设这个IPC性能是可以优化的,并且它已经被优化(即便不做任何事,随着硬件技术的发展,所谓的历史缺点往往也将逐渐弱化...)。我不公道地回避了核心问题,这并不是很道德,但为了下面的行文顺利,我不得不这么做。
很多人之所以并不看好微内核,很大程度上是因为它和Linux内核是如此不同,人们认为不同于Linux内核的操作系统内核都有这样那样的缺陷,这是因为Linux内核给我们洗了脑。
Linux内核的设计固化了人们对操作系统内核的理解上的观念 ,以至于 Linux内核做什么都是对的,反Linux的大概率是错的。 Linux内核就一定正确吗?
在我看来,Linux内核只是在恰当的时间出现的一个恰好能跑的内核,并且恰好它是开源的,让人们可以第一次内窥一个操作系统内核的全貌罢了,这并不意味着它就一定是正确的。相反,它很可能是错误的。【 20世纪90年代,Windows NT系统初始,但很难看到它的内在,《windows internal》风靡一时;UNIX陷入纠纷,GNU呼之却不出,此时Linux内核满足了人们一切的好奇心,于是先入为主,让人们觉的操作系统就应该是这个样子,并且在大多数人看来,这是它唯一的相貌。 】
本文主要说 内核的可扩展性 。
先泼一盆冷水,Linux内核在这方面做得并非已经炉火纯青。
诚然,近十几年来Linux内核从2.6发展到5.3,一直在SMP多核扩展方面精益求精,但是说实话架构上并没有什么根本性的调整,要说比较大的调整,当属:
$O(1)$调度算法。
SMP处理器域负载均衡算法。
percpu数据结构。
数据结构拆锁。
都是一些细节,没有什么让人哇塞的东西,还有更细节的cache刷新的管理,这种第二天不用就忘记的东西,引多少人竞折腰。
这不禁让人想起在交换式以太网出现之前,人们不断优化CSMA/CD算法的过程,同样没有让人哇塞,直到交换机的出现,让人眼前一亮,CSMA/CD随之几乎被完全废弃,因为它不是 正确 的东西。
交换机之所以 正确 的核心在于 仲裁。
当一个共享资源每次只能容纳一个实体占用访问时,我们称该资源为 “必须串行访问的共享资源” ,当有多个实体均意欲访问这种资源时,one by one是必然的,one by one的方案有两种:
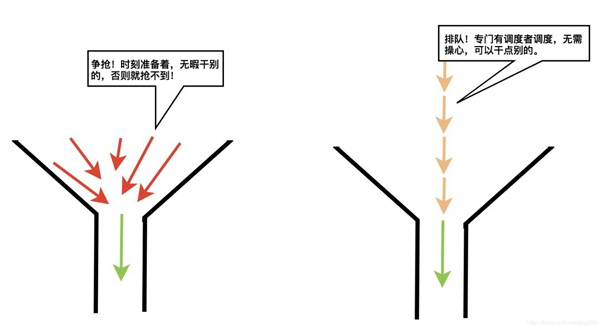
哪个好?说说看。
争抢必会产生冲突,冲突便耽误整体通过的时间,你会选哪个?
现在,我们暂时忘掉诸如宏内核,微内核,进程隔离,进程切换,cache刷新,IPC等概念,这些概念对于我们理解事情的本质毫无帮助,相反,它们会阻碍我们建立新的认知。比如,无论你觉得微内核多么好,总有人跳出来说IPC是微内核的瓶颈,当你提出一个类似页表项交换等优化后,又会有人说进程切换刷cache,寄存器上下文save/restore的开销也不小,然后你可能知道点 带有进程PID键值的cache方案 ,吧啦吧啦,最后一个show me the code 让你无言以对,一来二去,还没有认识全貌,便已经陷入了细节。
所以,把这些忘掉,来看一个观点:
对待必须串行访问的共享资源,正确的做法是引入一个仲裁者排队调度访问者,而不是任由访问者们去并发争锁!
所谓 操作系统 这个概念,本来就是莫须有的,你可以随便叫它什么,早期它叫 监视器 ,现在我们姑且就叫它操作系统吧,但这并不意味着这个概念有多么神奇。
操作系统本就是用来协调多个进程(这也是个抽象后的概念,你叫它任务也可以,无所谓)对底层共享资源的 多对一访问 的,最典型的资源恐怕就是CPU资源了,而几乎所有人都知道,CPU资源是需要调度使用的,于是任务调度一直都是一个热门话题。
你看, CPU就不是所有任务并发争抢使用的,而是调度器让谁用谁才能用 。调度,或者说仲裁,这是操作系统的精髓。
那么对于系统中共享的文件,socket,对于各种表比如路由表等资源,凭什么要用并发争抢的方式去使用?!所有的共享资源,都应该是被调度使用的,就像CPU资源一样。
如果我们循着操作系统理应实现的最本质的功能去思考,而不是以Linux作为先入为主的标准去思考,会发现Linux内核处理并发明显是一种错误的方式!
Linux内核大量使用了自旋锁,这明显是从单核向SMP进化时最最最简单的方案,即 只要保证不出问题的方案!
也确实如此,单核上的自旋锁并不能如其字面表达的那样 自旋 , 在单核场景下,Linux的自旋锁实现仅仅是 禁用了抢占 。因为,这样即可保证 不出问题 。
但到了必须要支持SMP的时候,简单的禁用抢占已经无法保证不出问题,所以 待在原地自旋等待持锁者离开 便成了最显而易见的方案。自旋锁就这样一直用到了现在。一直到今天,自旋锁在不断被优化,然而无论怎么优化,它始终都是一个不合时宜的自旋锁。
可见,Linux内核一开始就不是为SMP设计的,因此其并发模式是错误的,至少不是合适的。
有破就要有立,我下面将用一套用户态的代码来模拟 无仲裁的宏内核 以及 有仲裁的微内核 分别是如何对待共享资源访问的。代码比较简单,所以我就没加入太多的注释。
以下的代码模拟宏内核中访问共享资源时的自旋锁并发争抢模式:
#include <pthread.h> #include <signal.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <errno.h> #include <sys/time.h> static int count = 0; static int curr = 0; static pthread_spinlock_t spin; long long end, start; int timer_start = 0; int timer = 0; long long gettime() { struct timeb t; ftime(&t); return 1000 * t.time + t.millitm; } void print_result() { printf("%d\n", curr); exit(0); } struct node { struct node *next; void *data; }; void do_task() { int i = 0, j = 2, k = 0; // 为了更加公平的对比,既然模拟微内核的代码使用了内存分配,这里也fake一个。 struct node *tsk = (struct node*) malloc(sizeof(struct node)); pthread_spin_lock(&spin); // 锁定整个访问计算区间 if (timer && timer_start == 0) { struct itimerval tick = {0}; timer_start = 1; signal(SIGALRM, print_result); tick.it_value.tv_sec = 10; tick.it_value.tv_usec = 0; setitimer(ITIMER_REAL, &tick, NULL); } if (!timer && curr == count) { end = gettime(); printf("%lld\n", end - start); exit(0); } curr ++; for (i = 0; i < 0xff; i++) { // 做一些稍微耗时的计算,模拟类似socket操作。强度可以调整,比如0xff->0xffff,CPU比较猛比较多的机器上做测试,将其调强些,否则队列开销会淹没模拟任务的开销。 k += i/j; } pthread_spin_unlock(&spin); free(tsk); } void* func(void *arg) { while (1) { do_task(); } } int main(int argc, char **argv) { int err, i; int tcnt; pthread_t tid; count = atoi(argv[1]); tcnt = atoi(argv[2]); if (argc == 4) { timer = 1; } pthread_spin_init(&spin, PTHREAD_PROCESS_PRIVATE); start = gettime(); // 创建工作线程 for (i = 0; i < tcnt; i++) { err = pthread_create(&tid, NULL, func, NULL); if (err != 0) { exit(1); } } sleep(3600); return 0; }相对的,微内核采用将请求通过IPC发送到专门的服务进程,模拟代码如下:
#include <pthread.h> #include <signal.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <errno.h> #include <sys/time.h> static int count = 0; static int curr = 0; long long end, start; int timer = 0; int timer_start = 0; static int total = 0; long long gettime() { struct timeb t; ftime(&t); return 1000 * t.time + t.millitm; } struct node { struct node *next; void *data; }; void print_result() { printf("%d\n", total); exit(0); } struct node *head = NULL; struct node *current = NULL; void insert(struct node *node) { node->data = NULL; node->next = head; head = node; } struct node* delete() { struct node *tempLink = head; headhead = head->next; return tempLink; } int empty() { return head == NULL; } static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; static pthread_spinlock_t spin; int add_task() { struct node *tsk = (struct node*) malloc(sizeof(struct node)); pthread_spin_lock(&spin); if (timer || curr < count) { curr ++; insert(tsk); } pthread_spin_unlock(&spin); return curr; } // 强度可以调整,比如0xff->0xffff,CPU比较猛比较多的机器上做测试,将其调强些,否则队列开销会淹没模拟任务的开销。 void do_task() { int i = 0, j = 2, k = 0; for (i = 0; i < 0xff; i++) { k += i/j; } } void* func(void *arg) { int ret; while (1) { ret = add_task(); if (!timer && ret == count) { break; } } } void* server_func(void *arg) { while (timer || total != count) { struct node *tsk; pthread_spin_lock(&spin); if (empty()) { pthread_spin_unlock(&spin); continue; } if (timer && timer_start == 0) { struct itimerval tick = {0}; timer_start = 1; signal(SIGALRM, print_result); tick.it_value.tv_sec = 10; tick.it_value.tv_usec = 0; setitimer(ITIMER_REAL, &tick, NULL); } tsk = delete(); pthread_spin_unlock(&spin); do_task(); free(tsk); total++; } end = gettime(); printf("%lld %d\n", end - start, total); exit(0); } int main(int argc, char **argv) { int err, i; int tcnt; pthread_t tid, stid; count = atoi(argv[1]); tcnt = atoi(argv[2]); if (argc == 4) { timer = 1; } pthread_spin_init(&spin, PTHREAD_PROCESS_PRIVATE); // 创建服务线程 err = pthread_create(&stid, NULL, server_func, NULL); if (err != 0) { exit(1); } start = gettime(); // 创建工作线程 for (i = 0; i < tcnt; i++) { err = pthread_create(&tid, NULL, func, NULL); if (err != 0) { exit(1); } } sleep(3600); return 0; }我们对比一下执行同样多的任务,在不同的线程数的约束下,两种模式的时间开销对比图:
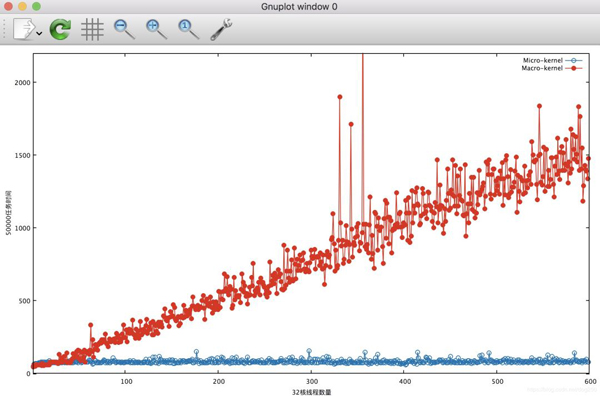
我们看到,在模拟微内核的代码中,用多线程执行并行访问共享数据curr时,开销不会随着线程数量的变化而变化,而模拟宏内核的代码中,总时间随着线程数的增加而线性增加,显然,这部分开销是自旋锁的开销。当今流行的CPU cache结构已经排队自旋锁的开销符合这种线性增长。
那么为什么微内核的模拟代码中的锁开销没有随着线程数量的增加而增加呢?
因为在类似宏内核的同步任务中,由于并发上下文的相互隔离,整个任务必须被一个锁保护,比如 Linux内核的tcp_v4_rcv 里面的:
bh_lock_sock_nested(sk); // 这部分耗时时间不确定,因此CPU空转率不确定,低效,浪费! ret = 0; if (!sock_owned_by_user(sk)) { if (!tcp_prequeue(sk, skb)) ret = tcp_v4_do_rcv(sk, skb); } else if (unlikely(sk_add_backlog(sk, skb, sk->sk_rcvbuf + sk->sk_sndbuf))) { bh_unlock_sock(sk); NET_INC_STATS_BH(net, LINUX_MIB_TCPBACKLOGDROP); goto discard_and_relse; } bh_unlock_sock(sk);然而,在微内核的代码中,类似上面的任务被打包统一交给单独的服务线程去 调度执行 了,大大减少了锁区里的延时。
宏内核的隔离上下文并发抢锁场景需要锁整个任务,造成抢锁开销巨大,而微内核只要锁任务队列的入队出队操作即可,这部分开销和具体任务无关,完全可预期的开销。
接下来让我们对比一下执行同样的任务,在不同CPU数量的约束下,两种模式的时间开销对比图:
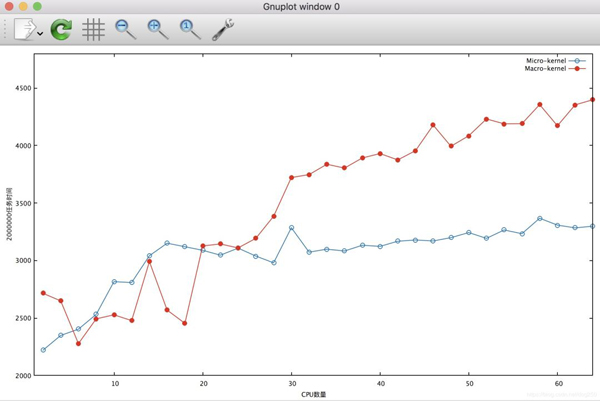
可见,随着CPU数量的增加,模拟宏内核的代码锁开销大致在线性增加,而模拟微内核的代码,锁开销虽然也有所增加,但显然并不明显。
为什么会这样?请看下面宏内核和微内核的对比图,先看宏内核:
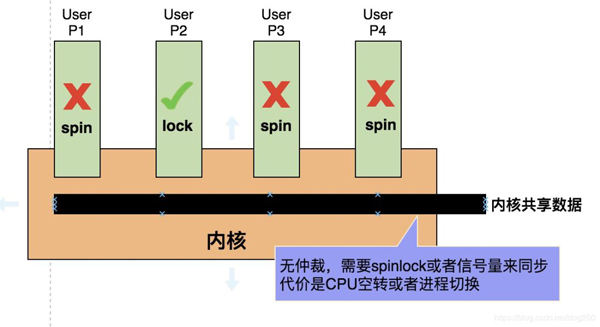
再看微内核:
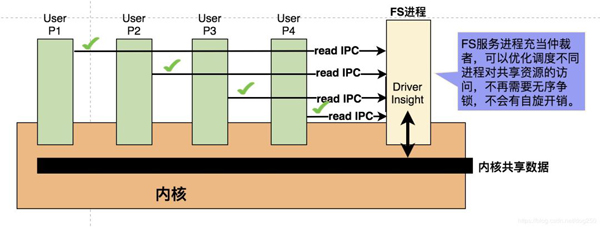
这显然是一种更加 现代 的方式,不光是减小了锁的开销提高了性能,更重要的是大大减少了CPU的空转,提高了CPU的利用率。
我们先看一下模拟宏内核的代码在执行10秒时的CPU利用率:
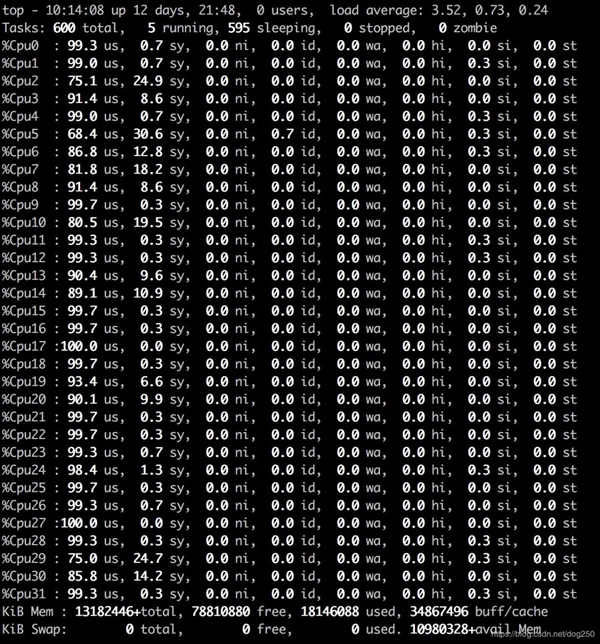
观察下热点,可以猜测就是spinlock:

显然,CPU利用率那么高,并非真的在执行有用的task,而是在spin空转。
我们再看下模拟微内核的代码在同样情况下的表现:
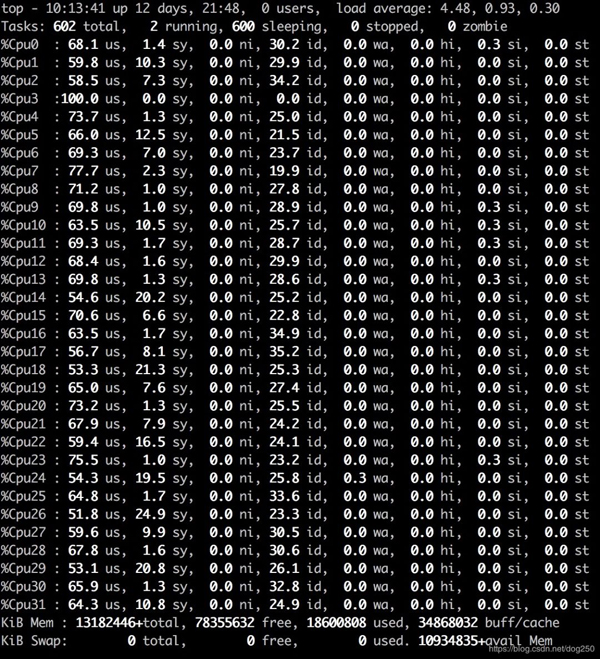
看下热点:

显然,仍然有个spinlock的热点,但显然降低了很多。在更高执行效率的保证下,CPU并没有那么高,剩余的空闲时间可以再去执行更多有意义的工作进程。
本文只是展示一个定性的效果,实际中,微内核服务进程的任务队列的管理效率会更高。甚至可以硬件实现。【参见交换机背板的交换网络实现。】
说了这么多,也许有人会说, NO,你这两个比对的case不严谨,你只模拟了访问共享的数据,如果是真的可并行执行的代码用微内核的方案岂不是要降低性能吗?平白自废武功,将并行改成串行!确实如此,但是 内核本身就是共享的。 操作系统本身就是协调用户进程对底层共享资源访问的。
所以真并行需要程序员自己来 设计可并行的应用程序。
内核本身就是共享的。共享资源的多线程访问就应该严格串行化,并发争锁是一种最无序的方式,而最有效的方式则是统一仲裁调度。
在我们日常生活中,我们显然能看到和理解为什么排队上车比拥挤着上车更加高效。在计算机系统领域,同样的事情我们也见于交换式以太网和PCIe,相比CSMA/CD的共享式以太网,交换机就是一个仲裁调度器,PCIe的消息hub也是扮演着同样的角色。
其实,即便是宏内核,在访问共享资源时,也并不是全都是并发争锁的方式,对于敏感度比较高的资源,比如时延要求很高的硬件资源,系统底层也是仲裁调度实现的,比如网卡上层发包的队列调度程序,此外对于磁盘IO也有对应的磁盘调度程序。
然而对于宏内核,更加上层的逻辑资源,比如VFS文件对象,socket对象,各种队列等等却没有采用仲裁调度的方式去访问,当它们由多个线程并发访问时,采用了令人遗憾的并发争锁模式,这也是不得已而为之,因为没有哪个实体可以完成仲裁,毕竟访问它们的上下文是隔离的。
来个插叙。当进行Linux系统调优时,瞄准这些方面相关的热点基本就够了。大量热点问题都是这种引起的,open/close同一个文件,进程上下文和软中断同时操作同一个socket,收包时多个CPU上的软中断上下文将包排入同一个队列,诸如此类。\如果你不准备去调优Linux,或许你已经知道Linux内核在SMP环境下的根本缺陷,调它作甚。多看看外面的世界,搞不好比你眼前唯一的那个要好。
当我们评价传统UNIX以及Linux这种操作系统内核时,应该更多的去看它们缺失了什么,而不是一味的觉得它们就是对的。【你认为它是的,可能仅仅因为它是你第一个见到并且唯一见过的】
如果非要说下概念,那就有必要说说 现代操作系统 的虚拟机抽象。
对于我们经常说的 现代操作系统 而言,按照最初的冯诺伊曼结构,只有 “CPU和内存” 在 多处理(包括所有的多进程,多线程等机制) 机制中被抽象了出来,而对于文件系统,网络协议栈等等却没有进行多处理抽象。换句话说,现代操作系统为进程提供了 独占的虚拟机抽象 ,该虚拟机仅仅包括CPU和内存:
时间片调度让进程认为自己独占了CPU。
虚拟内存让进程认为自己独享了内存。
再无其它虚拟机抽象。
在进程使用这些抽象资源时,现代操作系统无疑采用了仲裁调度机制:
操作系统提供任务调度器仲裁CPU的分时复用(典型的是多级反馈优先级队列算法),为进程/线程统一分配物理CPU的时间片资源。
操作系统提供内存分配算法仲裁物理内存空间的分配(典型的是伙伴系统算法),为进程/线程统一分配物理内存映射给虚拟内存。
显然,正如本文开头说过的,操作系统并未任由进程们去并发争抢CPU和内存资源,然而对于其它几乎所有资源,操作系统并未做任何严格的规定。操作系统以两种态度对待它们:
鸿蒙官方战略合作共建——HarmonyOS技术社区
认为其它资源并非操作系统核心的一部分,于是微内核,用户态驱动等等就形成了概念。
认为其它底层的资源也是操作系统核心的一部分,这就是宏内核比如Linux的态度。
态度如何,这并不重要,宏内核,微内核,用户态,内核态,这些也只是概念而已,没有什么大不了的。关键的问题乃是:
如何协调共享资源的分配。 或空间资源,或时间资源的或并发争锁,或仲裁调度的方式分配。
无疑,最大的争议就在CPU/内存之外如何协调非进程虚拟化的文件系统的访问和网络协议栈的访问。但无论它们俩的哪一个,目前无论是宏内核还是微内核都有非常非常棒的方案。遗憾的是,这些很棒的方案都不是Linux内核所采用的方案。
哦,对了Nginx便采取了类似微内核,交换机,PCIe的方法,Apache却不是。还有很多别的例子,不再一一赘述,只是想说一点,操作系统领域,核心的东西都是大象无形的,而不是那些形形色色的概念。
摘录一段王垠聊微内核时的一段话:
跟有些人聊操作系统是件闹心的事,因为我往往会抛弃一些术语和概念,从零开始讨论。我试图从“计算本质”的出发点来理解这类事物,理解它们的起因,发展,现状和可能的改进。我所关心的往往是“这个事物应该是什么样子”,“它还可以是什么(也许更好的)样子”,而不只是“它现在是什么样子”。不明白我的这一特性,又自恃懂点东西的人,往往会误以为我连基本的术语都不明白。于是天就这样被他们聊死了。
这其实也是我想说的。
so,忘掉微内核,宏内核,忘掉内核态,用户态,忘掉实模式,保护模式,这样你会更深刻地理解如何仲裁共享资源的访问的本质。
关于Linux在多核可扩展性设计上的有哪些不足就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





