这篇文章主要讲解了“怎么使用WebAssembly提高模型部署的速度和可移植性”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“怎么使用WebAssembly提高模型部署的速度和可移植性”吧!
为了说明模型训练与部署之间的区别,让我们首先模拟一些数据。 下面的代码根据以下简单模型生成1000个观测值:图片发布
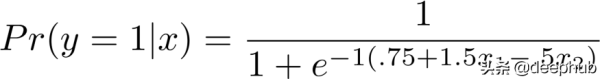
import numpy as np np.random.seed(66) # Set seed for replication# Simulate Data Generating Process n = 1000 # 1000 observations x1 = np.random.uniform(-2,2,n) # x_1 & x_2 between -2 and 2 x2 = np.random.uniform(-2,2,n) p = 1 / (1 + np.exp( -1*(.75 + 1.5*x1 - .5*x2) )) # Implement DGPy = np.random.binomial(1, p, n) # Draw outcomes# Create dataset and print first few lines: data = np.column_stack((x1,x2,y)) print(data[:10])
生成数据后,我们可以专注于拟合模型。 我们只需使用sklearn的LogisticRegression()函数即可:
from sklearn.linear_model import LogisticRegression mod = LogisticRegression().fit(data[:,[0,1]], np.ravel(data[:,[2]]))
仔细看看
在这一点上,梳理并简要考虑引擎盖下正在发生的事情非常有用。与许多其他有趣的ML模型一样,对逻辑回归模型进行迭代训练。为了训练模型,sklearn(或提供类似功能的任何其他软件包)将必须实现以下几个功能:
1. 某种评分函数,指示模型的拟合度。这可能是误差函数或最大似然函数。
2. 该函数可将拟合模型的参数从一次迭代更新到下一次迭代。
训练过程将有效地重复使用这两个功能:最初,模型的参数是随机实例化的。接下来,检查模型的分数。如果认为分数不够(通常是因为与以前的迭代相比,分数有所提高),则将更新模型参数并重复该过程。
即使对于这个简单的模型,sklearn仍需要遍历数据集。以下代码给出了迭代次数:
# Print the number of iterations print(f'The number of iterations is: {mod.n_iter_}.'因此,要训练模型,我们需要访问数据,还有几个工具的函数,并且需要多次迭代/遍历数据集。 总的来说,该训练过程对计算的要求很高,这说明了为什么对于复杂的模型,我们求助于并行计算以及GPU或NPU加速,以在合理的时间内执行。 幸运的是,当训练模型时,所需的相当复杂的逻辑已被我们使用的各种ML库抽象化了。
将其与从已经拟合的模型中生成预测进行比较(通常称为推理,但由于统计中使用的后者不同,因此我发现这个术语令人困惑,因此我坚持使用预测)。 到模型拟合时,在这种情况下,我们实际上需要生成预测的全部就是逻辑回归函数(与上面示例中用于生成数据的数学函数相同)以及拟合模型的三个参数。 这些很容易检索:
b = np.concatenate((mod.intercept_, mod.coef_.flatten())) print(b)
参数最终相对接近我们用于数据生成的值:[0.84576563 1.39541631 -0.47393112]。
此外,在大多数部署情况下,我们通常最终仅使用单个输入来评估模型:在这种情况下,长度为2的数字向量。 如果我们要部署模型,则不需要拟合函数,不需要数据,也不需要迭代。 要生成预测,我们只需要简单有效地实现所涉及的数学函数即可。
"所以呢?"你可能会问。当现代模型训练工具抽象出所有这些细节时,为什么还要关心训练和预测中涉及的细节呢?好吧,因为当您希望有效地部署模型时(例如,当您需要模型在小型设备上快速运行时),您可以更好地利用设备的差异。
为了便于讨论,请对比以下两种模型部署方法(即,将经过训练的模型投入生产,以便可以使用其预测):
将sklearn作为REST服务部署在Docker容器上:这种方法很简单并且经常使用:我们启动一个包含python和用于训练的工具的docker镜像:对于上面的示例逻辑回归模型sklearn。接下来,我们创建一个REST API服务,该服务使用拟合模型的mod.predict()函数来生成结果。
Scailable WebAssembly部署:除了上述方法以外,还可以将拟合模型转换为WebAssembly(使用与Scailable提供的服务类似的服务),并部署.WASM二进制文件,其中仅包含在最小的WebAssembly运行时中进行预测所需的逻辑。 自动生成的二进制文件将仅包含必要的逻辑函数和估计的参数。二进制文件可能部署在服务器上因此也类似地通过REST调用使用,但是,它可以兼容可用的运行时,它也几乎可以在任何边缘设备上运行。
显然,第一个部署过程接近数据科学家的"我们所知道的"。直接使用我们惯用的工具是非常方便的,并且在许多方面它都有效:我们可以使用对REST端点的调用来生成预测。第二种解决方案与我们的标准实践相距甚远,并且对于模型训练毫无用处(即,没有"WebAssembly软件包来训练模型……")。但是,我们仍然认为应该首选:第二种设置利用了训练和预测之间的差异,从而在几个方面使模型部署更好:
内存占用:上面两个选项中的第一个选项将需要至少75Mb的容器(要使容器变小需要大量的工程设计,使容器的大小接近1Gb更为常见)。在这种情况下,存储的模型本身很小(〜2Kb),因此容器占部署内存占用的最大块(请注意,例如大型神经网络可能不正确)。相反,WebAssembly运行时可以降至64Kb以下。 WebAssembly二进制本身本身大于存储的sklearn模型(〜50kb),但是现在它包含生成预测所必需的全部。因此,虽然第一个部署选项至少占用75Mb,但第二个部署选项占用不到0.1Mb。
速度:与高效的WebAssembly部署相比,消耗一个在Docker容器中运行的REST端点并不能在执行时间上取得优势,因为Docker容器启动了所有训练所需的东西。下面是一些针对不同模型的速度比较,但是,不必说,利用训练和预测之间的差异,并且仅仅将预测的基本需求投入生产,就可以通过一个数量级提高速度,从而生成这些预测。
因此,内存占用更小,执行速度更快。有几个原因;其中一个原因是,我们可能希望有效地部署模型,而不会在每次做出预测时浪费能源。但是,一个小的内存占用和快速的执行也是很吸引人的,因为这正是我们在将模型投入生产的边缘所需要的:好运部署你的Docker容器(例如,)在ESP32 MCU板上。使用WebAssembly,这是小菜一碟。
感谢各位的阅读,以上就是“怎么使用WebAssembly提高模型部署的速度和可移植性”的内容了,经过本文的学习后,相信大家对怎么使用WebAssembly提高模型部署的速度和可移植性这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





